Insight
A Primer on Data Labeling Approaches To Building Real-World Machine Learning Applications

Caroline Lasorsa
Product Marketing | 2022/01/05 | 9 min read

Introduction
In computer vision and machine learning operations, data labeling is an essential part of the overall workflow. For reference, data labeling is the process by which raw images, video, or audio files are identified and annotated individually for machine learning models, which in turn use that data to make predictions that can be applied to the real world. For example, a correctly labeled dataset for a self-driving car can help a model distinguish between a stop sign or a pedestrian, but if mislabeled, it can have catastrophic consequences.
For machine learning models to deliver the best results, datasets must contain a high level of detail, and files must be labeled accurately. In building machine learning models, companies may choose to use manual or automated approaches. As artificial intelligence becomes more commonly used in scenarios such as food delivery services, surgeries, and warehouse robots, accurate computer vision models are becoming increasingly paramount.
In deciding which approach to take in building your machine learning models, one of the primary considerations is human involvement, also known as human in the loop (HITL). As of now, machine learning models are largely unable to operate entirely autonomously and require some level of human oversight to build an accurate model. In the current landscape, the need for HITL is becoming less necessary than in years past, but the level of human involvement depends entirely on the desired approach and end goal for a particular project.
While no single approach to data labeling could be considered ‘correct’ or ‘incorrect,’ each does possess distinct advantages and disadvantages that you should carefully evaluate within the context of your use case and project before you get too far into the weeds. In this article, we’ll examine the most popular methods of data labeling by dividing them into two major categories: manual labeling and automatic labeling, and explore their inherent benefits and limitations.
Manual Data labeling
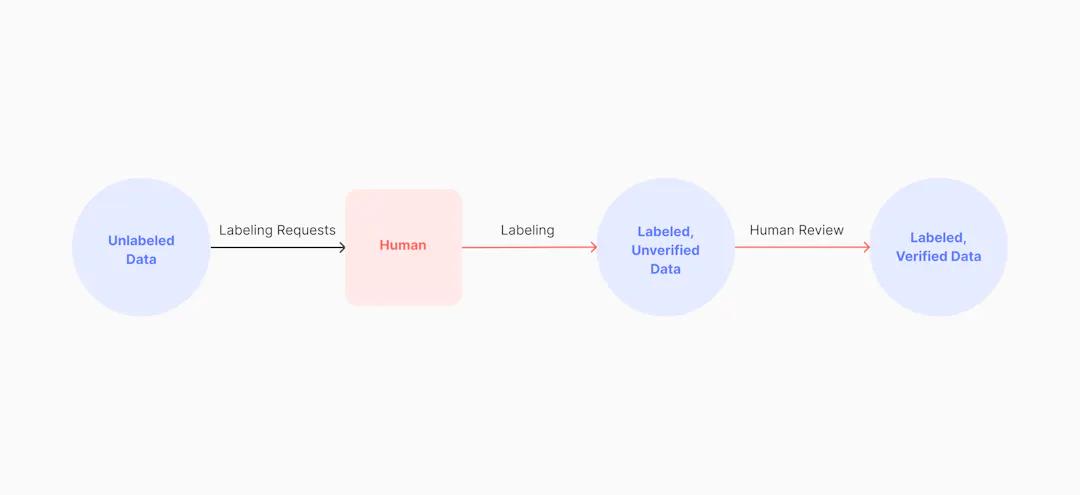
Diagram of the manual data labeling process
Perhaps the most cumbersome approach is through manual data labeling. Manual labeling is exactly as the name implies in that it requires the highest level of human intervention when building out a dataset. In this approach, humans manually annotate objects in each image or video to build a training dataset for a machine learning model. Though time-consuming and costly, manual data labeling does have its advantages for certain types of projects.
In instances where images contain lots of data with inconsistencies and caveats, manual labeling by trained human professionals is the best approach. For example, a computer vision model developed to identify tumors in cancer patients should likely be hand-labeled by medically trained radiologists. There’s one exception to this rule of thumb involving a novel automation method and custom labeling AI, but we’ll discuss that near the end. In training ML models, you can take the following approaches:
1 - In-house operations
Teams looking to build their models entirely onsite can rely on everyone from data scientists and engineers to ML engineers and even interns for simple use cases to label the thousands of images needed to create an effective training dataset. Utilizing their own teams is advantageous when an expert opinion is necessary. Tech giants such as Tesla will often use their own in-house teams to build out their datasets.
The Good:
In-house operations teams can oversee every step in the data labeling process from start to finish. When building out datasets that involve careful annotation, in-house teams utilize their expertise to create more accurate datasets. Building in-house datasets have the advantage of letting it reside with the experts who know it inside and out and understand each use case for their dataset. In many circumstances, datasets need to be constantly updated to match the ever-changing landscape of real-world scenarios. Keeping the data in-house is a sure-fire way for teams to update their datasets quickly and easily. In the example of self-driving cars, the vehicles on the road are constantly changing, so the images in the dataset should also be updated frequently to avoid data drift and other associated issues. In addition, keeping the data in-house ensures that proprietary information is kept close to the source, reducing the risk of leaks and breaches.
The Limitations:
While keeping datasets in-house limits any hiccups that outsourcing may cause, it also takes up valuable resources within the company. The most time-consuming aspect of building out a machine learning model is data labeling. Utilizing in-house data scientists and ML engineers to label hundreds of thousands of images cuts into valuable time that could be spent on more pressing company needs. Not to mention, it’s hideously expensive. Engineers are some of the highest-paid employees at tech companies, meaning that the process of labeling data is costly and prohibitive for smaller outfits. In-house data labeling simply isn’t possible for smaller startups with limited resources.
Using in-house resources isn’t the only option for manual data labeling. Some companies opt for a hybrid or crowdsourced approach. Choosing one of these methods depends entirely on the needs of your business, and there are many reasons to choose one avenue over another.
2 - Crowdsourcing
When crowdsourcing, companies use freelancers to complete the data labeling process through programs like Amazon Mechanical Turk. Labeling is conducted on a small scale by a large set of labelers, reducing the workload individually and company-wide. This is a good option for outfits that do not have the resources to implement in-house operations.
The Advantages:
Crowdsourcing has both its benefits and limitations. One of the main draws for companies to crowdsource data labeling is cost. Utilizing inexpensive freelancers is much less of a financial burden than turning to ML engineers. In addition, it takes much less time than relying on a small cohort of employees to build out a dataset. Crowdsourcing data labeling appeals to smaller companies looking for an efficient way to build their machine learning models, but it has its drawbacks.
The Disadvantages:
Relying on a crowdsourced team allows large amounts of data to be labeled quickly and cheaply, but accuracy is always a concern. When fragments of datasets are annotated from hundreds or even thousands of sources, the method for doing so varies widely between freelancers, meaning that inconsistencies in the datasets are inevitable. For example, if a company is looking to label cars and trucks accurately, one person might consider an SUV a truck while another might consider it a car. Inconsistent labels can affect the overall accuracy and performance of datasets. Relying on others also makes it challenging to manage workflows and conduct quality assurance checks.
3 - Outsourcing
For those looking for a third option, outsourcing data labeling is a common route that companies take. In this instance, outside teams are hired specifically to label data manually. They’re often trained by QA specialists and devote their full attention to labeling.
The Upside:
Outsourcing is a common practice for companies looking to save time and money, as relying on outside teams to assist in building datasets is far cheaper than using in-house ML engineers. Using outsourced teams is advantageous for projects with large volumes of data that need to be completed in short periods of time. Outsourcing is an optimal choice for temporary projects that don’t need consistent updating.
The Downside:
Outsourced data labeling is often sent to teams overseas, so ML engineers have limited control over the workflow. Because a centralized team is devoted to your project, it is slower than crowdsourcing because fewer people are generally working on it. That said, outsourcing tends to yield more accurate datasets than crowdsourcing and is often a consideration when choosing this route.
Automatic Data Labeling
Aside from manual data labeling, automatic labeling is also an option for different types of projects and is a more viable choice for many companies. While there is a lot of variability in the various forms of automated labeling, it generally involves either an AI system labeling raw data for you or AI being implemented within the annotation UI itself to speed up manual processes (like converting a bounding box to a segmentation). In either case, trained professionals are used to review the data for accuracy and quality.
Data that is correctly labeled is then fed through the system, creating a data pipeline of sorts. Though data labeling cannot be completely automated, as human touch is often needed for highly complex projects and to validate the AI’s performance, some tools and strategies can significantly streamline and speed up the process.
1 - Model-assisted Labeling
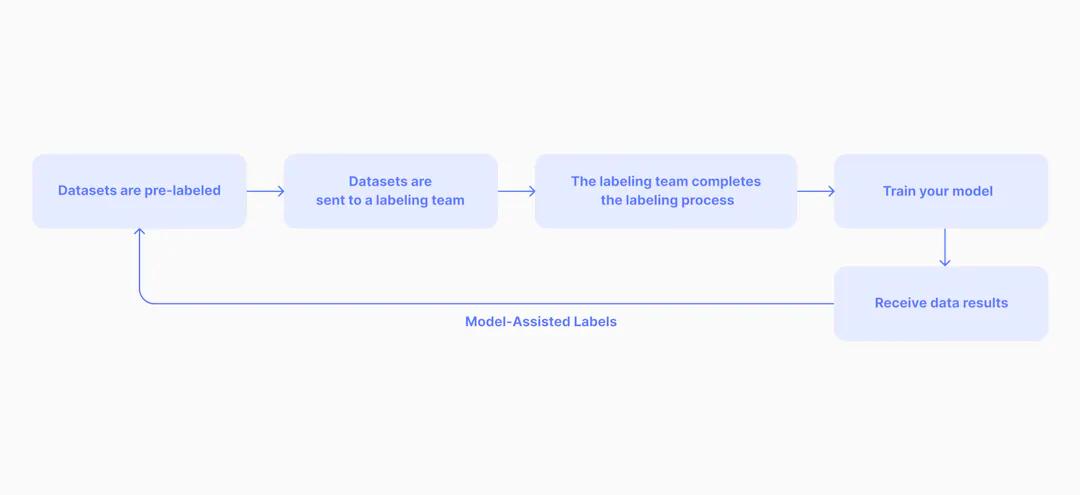
Diagram of model-assisted data labeling tools
Model-assisted labeling generally involves labeling a small initial dataset and training an AI system in parallel solely for the purpose of labeling, which then uses this information to predict annotations for unlabeled data. Alternatively, a pre-existing production model is used within the labeling loop to make predictions for you. Then, a human must generally audit the pre-labeled data and correct any errors that could affect the dataset (while feeding the corrected labels back to the model). Some solutions allow you to complete this process within the UI itself, but others only support the uploading of pre-labeled data (i.e., the model makes predictions using your existing technology stack, and you upload those pre-labels to the solution).
The Good:
Using this method to build out training datasets for your computer vision models can, in theory, be a highly effective way to get a lot of labels quickly - as approving pre-labels is generally faster than manual annotation. In addition, this method provides early indicators of model weaknesses, mainly when working with existing production models, giving you the chance to make corrections earlier in the process. It also cuts down on the need for project managers to oversee crowdsourced or outsourced labeling, a major bottleneck in manual labeling.
The Drawbacks:
On the flip side, MAL has its drawbacks. While much more automated than manual labeling, it still requires a HITL element to oversee the labeling process - precisely because no model is perfect. Without a human to decipher specific errors, automated models can lead to mistakes easily avoided by a person. It’s also only as good as your pre-existing models or the model you are training, so it is paramount that both your model and datasets are as accurate as possible before or in the early stages of automated labeling. Using time and resources to fix each error is costly, but it is unavoidable without a perfect way to automate machine learning algorithms. Many practitioners have reported to us that they often end up spending more time fixing errors in their pre-labels than they would have spent simply manually labeling them from the start.
2 - AI-assisted Labeling
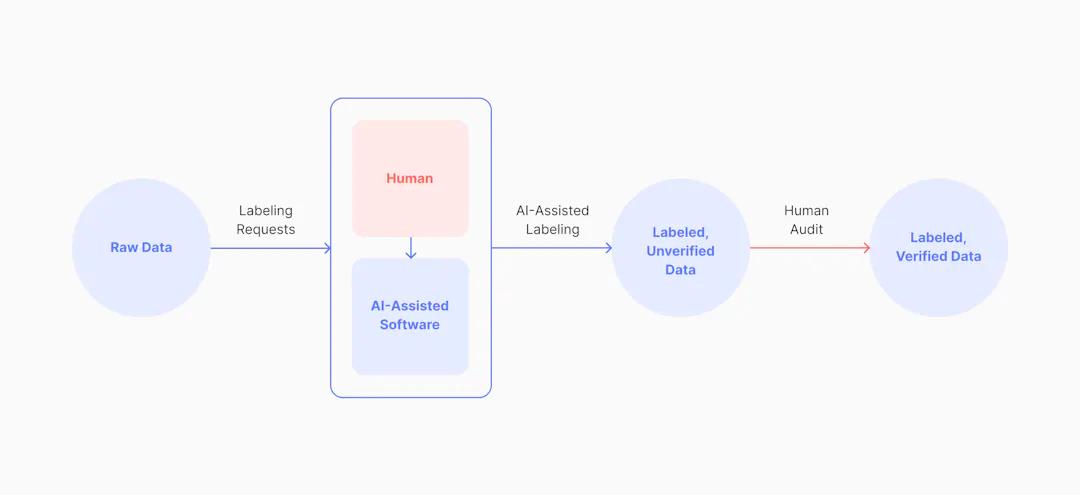
Diagram of AI-assisted automatic data labeling powered by computer vision tools
Another form of automatic data labeling that some companies choose to implement is an AI-assisted annotation system. In this circumstance, AI-assisted software helps the labeler perform manual tasks more efficiently, like drawing out an outline from only a small set of points - or making predictions based on previous experience.
The Advantages:
AI-assisted labeling speeds up the process of building datasets with human oversight, meaning that more labels can be completed in a shorter period of time compared to purely manual labeling. In the medical field, for example, specialists often use AI-assisted annotation to more quickly build out ML models trained to identify diseases in a group of patients. Once sufficient labels have been created, the AI software can help determine which objects within a specific image or video frame should be annotated.
The Disadvantages:
With AI-assisted labeling, teams can annotate data and build their models quickly and more efficiently than manually. However, it still generally requires a decent amount of human involvement for each piece of data, and the labels still need to be reviewed after the fact by a QA team or other auditing group.
3 - Auto-Labeling and Custom Auto-Labeling
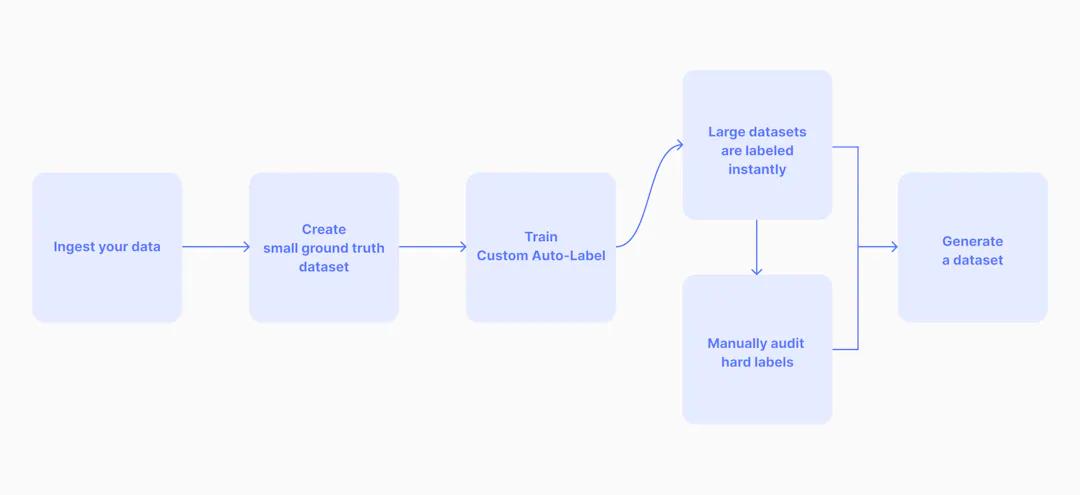
In the world of artificial intelligence, data labeling is the most laborious part of the process, so many companies are looking for ways to alleviate the bottleneck with automation. At Superb AI, we want to challenge the notion that labeling needs to be difficult and cumbersome. With its no-code platform, Superb AI offers the ability to achieve ground truth with only a few hundred labeled images or video frames using our common objects auto-labeling system or our custom auto-labeling system.
Common Objects Auto-Label
Superb AI grants clients the choice of using their own pre-labeled data to build out their model (custom auto-label) or use one of ours (common objects auto-label). In the latter process, Superb AI’s auto-label AI utilizes a plethora of open source, pre-trained datasets to label your model through a process known as transfer learning. These datasets are derived from a model or task similar to your project and automatically generate label annotations using our common objects auto-label AI, clients are able to implement labels based on existing datasets, speeding up the overall process and streamlining the QA process.
Custom Auto-Label
Alternatively, custom auto-label offers flexibility outside of transfer learning when building a model. Utilizing few-shot learning, Superb AI uses a small amount of labeled data (around 2,000 annotations per object class, though sometimes it can be much lower) from your own dataset to train a model. The amount of data needed to train your model is significantly less than that of other AIs, drastically reducing the time, man power, and cost of labeling your dataset--and it doesn’t require a pre-trained model. CAL is a fantastic tool for newer companies in the machine learning space as well as those working on niche projects. In addition, creating your specific CAL is fast, taking under an hour; once this is done, your dataset is audited by our uncertainty estimation AI, which can point out any areas of uncertainty that may indicate mislabeling. Showing only the labels our AI is unsure of reduces the time required to audit your dataset dramatically. After the first go-around, ML engineers can correct any discrepancies within their model, feed it through again, and maintain a higher level of accuracy. This is done multiple times until the ML model achieves a high level of precision.
In the current technological landscape, machine learning models are impossible to automate from start to finish, but some advances have made it possible to alleviate human involvement. Superb AI’s custom auto-label is tackling the bottleneck that impedes many machine learning engineers.
Conclusion
In essence, machine learning models are an essential part of artificial intelligence and are becoming more commonplace as technology advances. Finding the correct strategy for labeling your data relies heavily on the types of projects you’re building, the resources you have access to, and the goals you’re looking to accomplish. Each approach has its advantages and drawbacks that machine learning engineers must consider.
The path to automated data-labeling isn’t clear-cut, and the need for some human oversight is still inevitable. But there are ways to cut down on time and labor costs with the Superb AI Suite. Utilizing our custom auto-label technology to achieve ground truth faster and with less resources saves both time and money for your company’s AI projects. To learn more about Superb AI’s auto-label capabilities, click here.
Related Posts

Insight
⑪ Germany's Physical AI Moment: Siemens, BMW, and the Robot Unicorn Counteroffensive

Hyun Kim
Co-Founder & CEO | 15 min read

Insight
⑩ Big Tech Physical AI Trends (2): Tesla vs. Amazon Strategy Breakdown
Hyun Kim
Co-Founder & CEO | 10 min read

Insight
⑨ Big Tech Physical AI Trends (1): NVIDIA vs. Google Strategy Breakdown
Hyun Kim
Co-Founder & CEO | 7 min read

About Superb AI
Superb AI is an enterprise-level training data platform that is reinventing the way ML teams manage and deliver training data within organizations. Launched in 2018, the Superb AI Suite provides a unique blend of automation, collaboration and plug-and-play modularity, helping teams drastically reduce the time it takes to prepare high quality training datasets. If you want to experience the transformation, sign up for free today.