Product
Data Labeling Meets Data Monitoring with Superb AI and WhyLabs

James Le
Tech Advocate | 2021/11/30 | 4 min read

Introduction
Data quality is the key to a performant machine learning model. Without high-quality data to train on, the model will be unable to represent the real-world processes that the data encapsulates accurately. And without high-quality data to feed into the model once it’s trained, the model’s predictions will be wildly inaccurate. That’s why WhyLabs and Superb AI are on a mission to ensure that data scientists and machine learning engineers have access to tools designed specifically for their needs and workflows. These tools enable them to generate high-quality data and monitor the quality of their data, so they can produce robust and reliable ML models.
In this blog post, we explain how WhyLabs and Superb AI’s complementary technologies fit together in a way that brings value to AI practitioners. After a brief overview of each platform, we dive into an example workflow that demonstrates how the two tools can be used in conjunction.
Superb AI Suite Platform
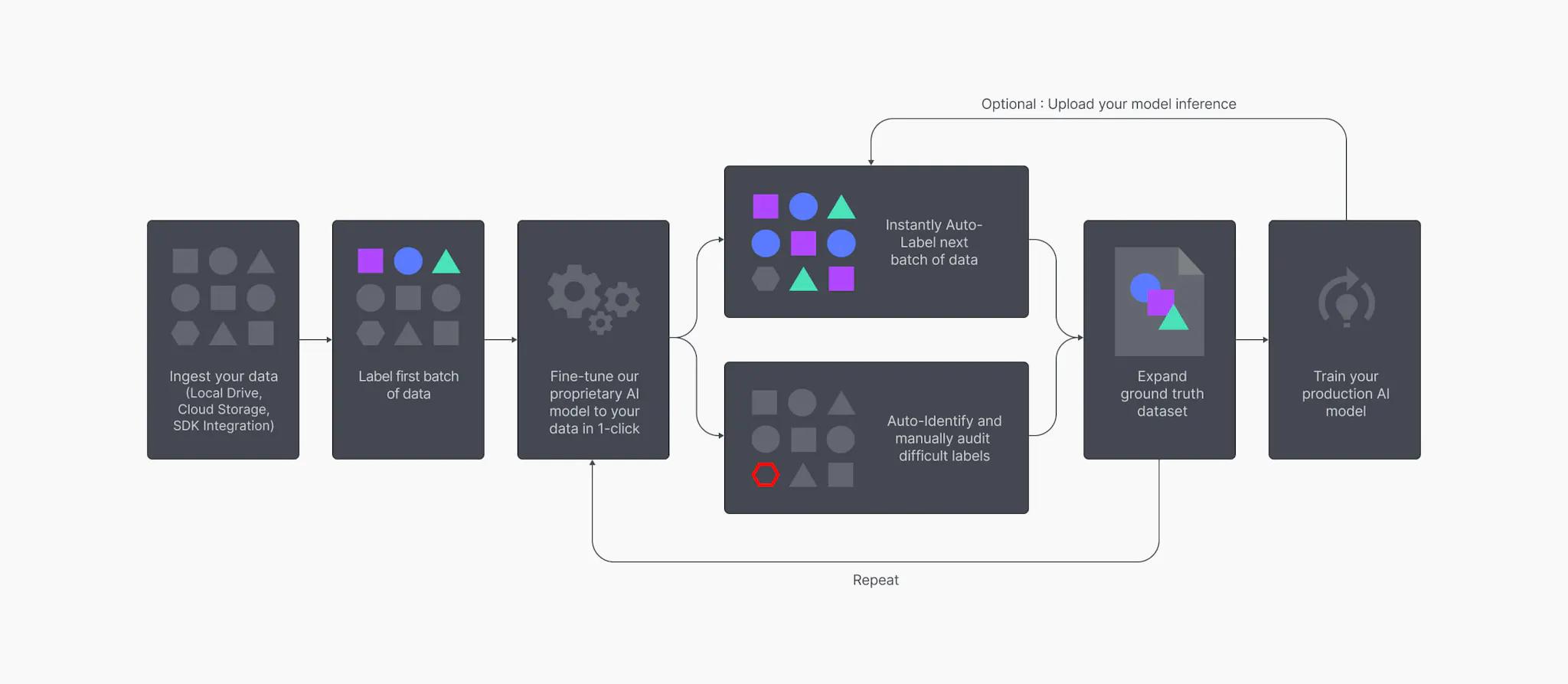
Superb AI has introduced a revolutionary way for ML teams to drastically decrease the time it takes to deliver high-quality training datasets. Instead of relying on human labelers for a majority of the data preparation workflow, teams can now implement a much more time and cost-efficient pipeline with the Superb AI platform.
Everything centers around Superb AI’s customizable auto-label (CAL) technology, which uses a unique mixture of transfer learning, few-shot learning, and autoML, allowing the model to achieve high levels of efficiency with small, customer-proprietary datasets quickly. The concept is quite simple: instead of having to create massive ground truth datasets by hand, teams can now build much smaller ground truth or “golden” sets, quickly spin up and train an auto-labeling model with just a few clicks and start labeling large datasets in a matter of minutes. Coupling the workflow with proprietary Uncertain Estimation AI and enterprise-level auditing tools, teams can label large datasets, immediately identify hard labels, build active learning workflows for auditing and deliver datasets in a matter of days.
WhyLabs AI Observability Platform
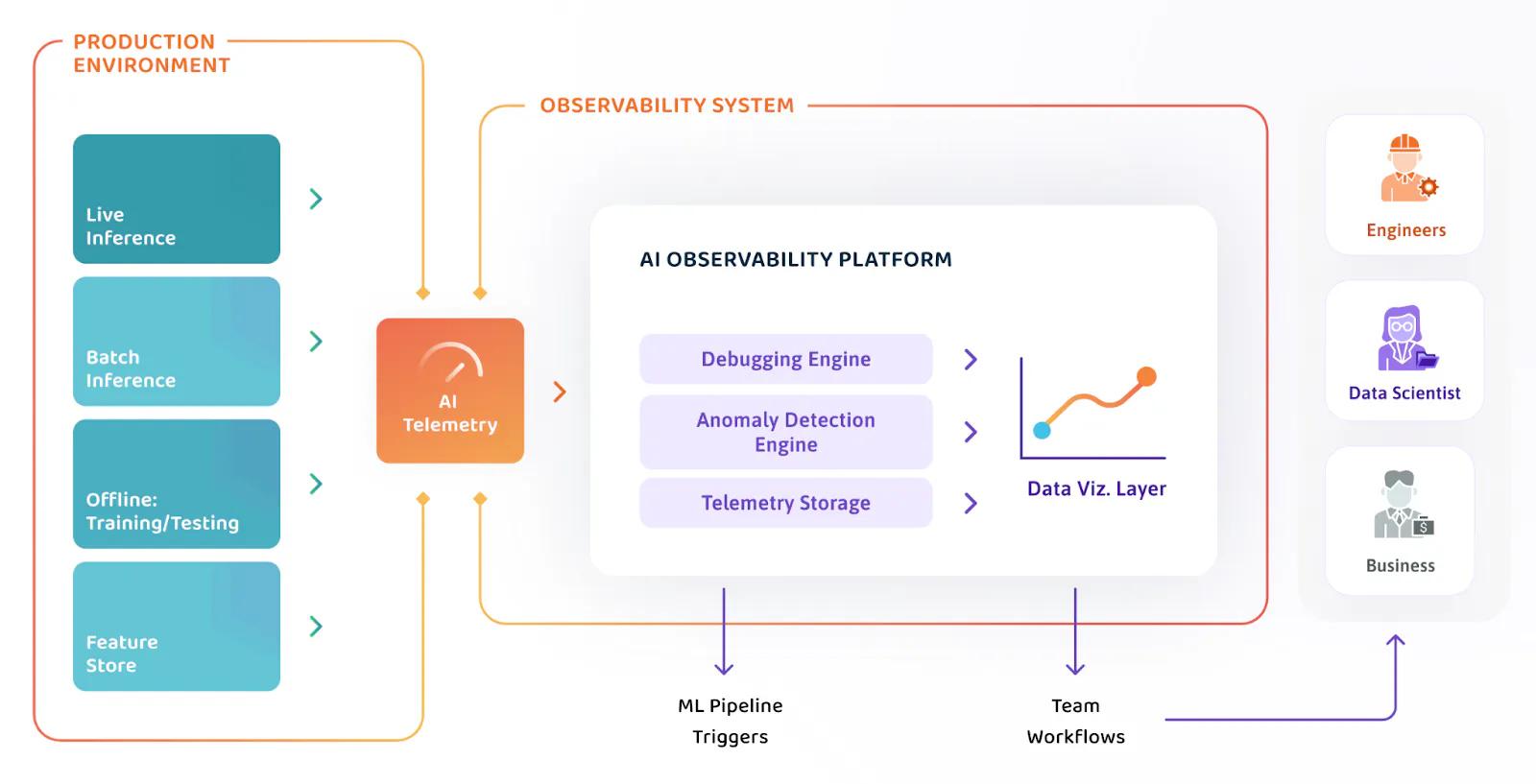
WhyLabs provides the critical missing component of AI observability in production ML systems by monitoring ML deployments. With the WhyLabs AI Observability Platform, every AI practitioner can switch on monitoring for model and data health automatically. Data science teams use the platform to monitor data pipelines and AI applications - surfacing data quality issues, data bias, data drift, and concept drift. Out-of-the-box anomaly detection and purpose-built visualizations let WhyLabs users prevent costly model failures and eliminate the need for manual troubleshooting.
WhyLabs is unique in its approach to monitoring data and ML models. It relies on the open-source data logging standard, whylogs, to generate data profiles, statistical summaries of datasets. These profiles get sent to the WhyLabs platform, where they can be analyzed and alerted on. It works on any data, structured or unstructured, at any scale, on any platform.
Automated Labeling + Monitoring = Reliable Data Operations
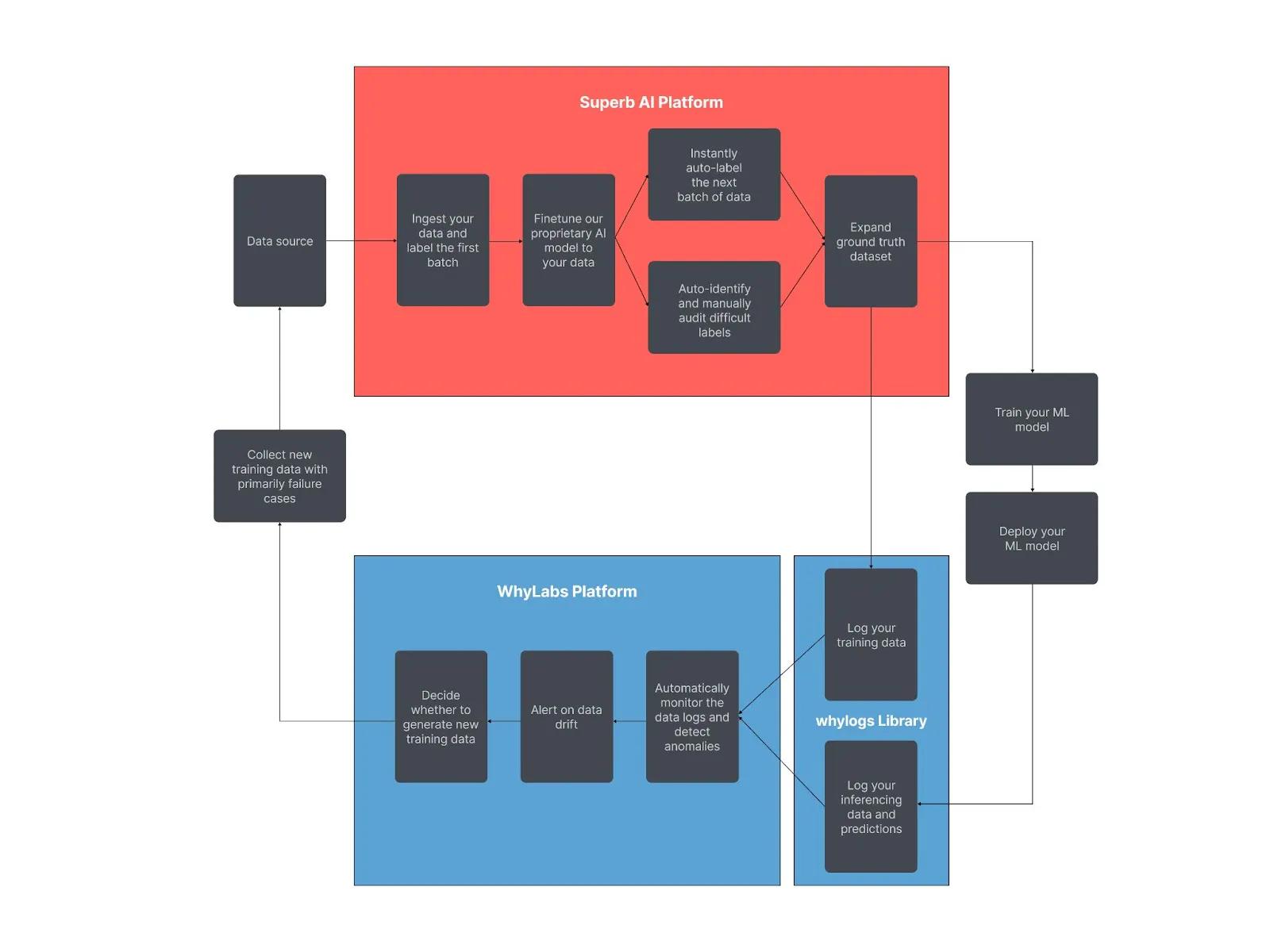
Amongst the common use cases for WhyLabs’ customers is monitoring computer vision models. To monitor such a model, a “baseline” profile needs to be generated from the images on which the model is trained. Then, more profiles are generated on the images used for inference once the model is in production. These production profiles are compared against the baseline profile and against each other, allowing a data scientist to notice when data starts to drift and performance starts to degrade.
When a user experiences training-serving skew or data drift, they can be sure that model performance degradation is sure to follow. And if a model is not performing well, it is costing the business potential revenue that it would be able to capture if the model was functioning. To remedy this model performance degradation, a user can turn to SuperbAI to automatically label a fresh dataset and retrain their model based on this new data.
Conclusion
As you can see, WhyLabs and Superb AI fit together perfectly to enable data quality assurance for their users and enable reliable data operations.
If you’re interested in trying out the WhyLabs, check out the always-free Starter edition.
If you’re interested in trying out the Superb AI platform, request a free trial here.
Related Posts

Product
How to Build & Deploy an Industrial Defect Detection Model for a Lucid Vision Labs Camera

Sam Mardirosian
Solutions Engineer | 15 min read

Product
How to Build & Deploy a Safety & Security Monitoring AI Model for an RTSP CCTV Camera
Sam Mardirosian
Solutions Engineer | 15 min read

Product
How to Use Generative AI to Properly and Effectively Augment Datasets for Better Model Performance

Tyler McKean
Head of Customer Success | 10 min read

About Superb AI
Superb AI is an enterprise-level training data platform that is reinventing the way ML teams manage and deliver training data within organizations. Launched in 2018, the Superb AI Suite provides a unique blend of automation, collaboration and plug-and-play modularity, helping teams drastically reduce the time it takes to prepare high quality training datasets. If you want to experience the transformation, sign up for free today.