Insight
Exploring Computer Vision Datasets

James Le
Tech Advocate | 2021/11/29 | 4 min read

What are open datasets?
A dataset is a collection of samples (in this case, images or video) used to train and test machine learning models. Datasets usually contain examples that belong to a particular topic or domain.
Open datasets are datasets available for anyone to download and use freely. Mostly these datasets are labeled and can be used as ground truth for various supervised learning tasks like object detection or image classification. Labeled datasets were a key factor that accelerated research in computer vision in the past ten years.
Working with image datasets
To understand the challenges of working with open datasets for computer vision, it is essential to point out the difference between structured and unstructured datasets. A tabular or structured dataset can be understood as a table or matrix where data points are organized so that columns and rows correspond to a particular variable and field of the dataset. That structure makes it possible to query, apply statistical methods to analyze data and formulas to transform data, and extract features for machine learning models to learn from.
On the other hand, datasets for computer vision tasks lack that uniform structure, making exploration and preprocessing of data for training a very different task. Multiple things differentiate unstructured datasets:
- They are big datasets with media files, and so consume a lot of bandwidth to download and move around.
- A dataset is usually structured as a folder with images and a CVS file containing image-label mapping. To visualize images with labels and corresponding bounding boxes, one would need to write dozens of lines of code regenerating thousands of images to analyze. And after that, you might want to edit some ground truth labels, which means you’ll require an annotation tool.
- One should always be careful not to break image-label mapping when working with an image dataset. Mapping is even more complex for object detection or segmentation tasks as it can have multiple labels per image and bounding box coordinates associated with each label.
- Images should be scaled and normalized to one standard appropriate for a particular neural network. Usually, it’s a good idea to augment and transform the data to introduce more variation in your training. This means generating another dataset - which is a time and storage-intensive endeavor.
- Exploring thousands of images in a dataset to find meaningful assumptions that can improve training is important, but the lack of established tools and frameworks to do so makes this extremely difficult. Often computer vision practitioners are basically forced to work in the dark.
Exploring computer vision datasets
Like with tabular data, image datasets should be explored first, especially since downloading and preprocessing them is a big commitment from a time and resources perspective.
Exploring an image dataset at the very least can save you a lot of time spent on wrangling and processing image datasets, only to find out they are not suited for your use case. But more often than not, good data exploration will provide insights needed to understand your model performance and how to improve it.
Public computer vision datasets are usually labeled by many people from one organization or crowdsourced from all over the world. Therefore you should never assume that they are perfect.
Here’s what you can learn from exploring image datasets visually:
- Assess overall data quality. Inspect as much of the dataset as possible visually. Make sure there are no obvious graphics artifacts.
- Inspect classes available in the dataset. Are they what you need or expected?
- Check the quality of annotations for object detection or segmentation. Are there mislabeled instances? Does the annotation quality look good?
- Are there examples with missing annotations or that are only partially labeled?
- How many examples are available per class? Are there apparent imbalances?
At Superb AI, we know that exploring image datasets can be a hassle. So now, to make this whole process a fair bit easier, you can use our training data platform to explore some public datasets quickly - with no signup or downloads required. Just visit our Datasets page to visually explore some of the most popular and unique image datasets available today.
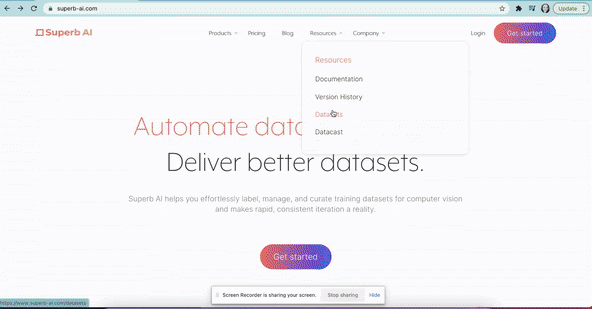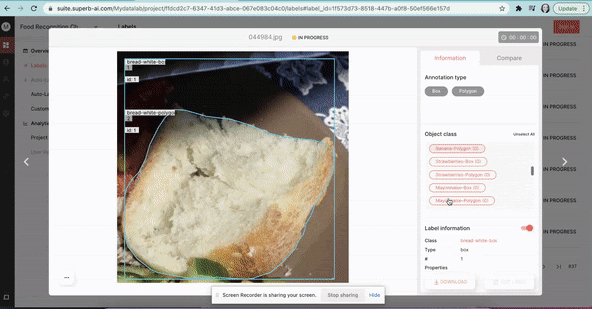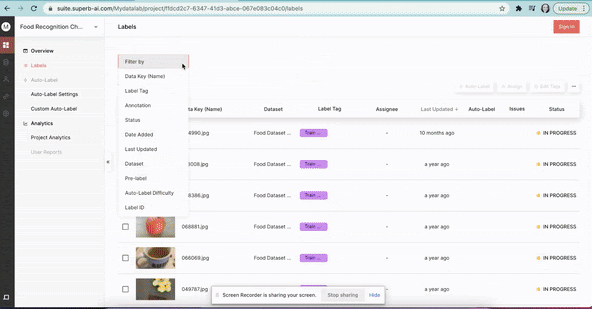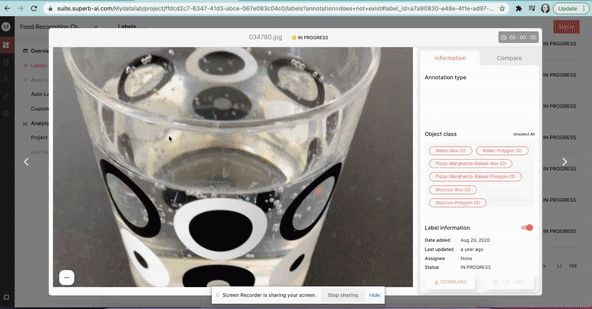
Where to find open datasets for computer vision
There are plenty of open datasets available online.
The list below includes some of the best computer vision dataset aggregators maintained and regularly updated by the community. You can rely on them for high-quality open-source datasets.
A really valuable resource to look for datasets. This site features a wide variety of datasets and corresponding papers with state-of-the-art models trained on a given dataset. It is also straightforward to use because you can filter your search by task (like object detection) or modality.
This is the most well-known resource for datasets and machine learning competitions.
Dataset Search is a search engine for datasets. Using a simple keyword search, users can discover datasets hosted in thousands of repositories across the Web.
Open Images is actually a dataset, not an aggregator. Latest version 6 consists of ~9M images annotated with image-level labels, object bounding boxes, object segmentation masks, visual relationships, and localized narratives.
Repository of datasets categorized by the computer vision task: detection, classification, recognition, tracking, segmentation and more.
Great place to find and share computer vision datasets with detailed search filters.
Conclusion
Most of the time, deep neural networks are the default choice for computer vision tasks. They can extract meaningful features from image data much better than humans can. Because of this, deep neural networks are treated as something of a black box that can’t be understood. This assumes that there is nothing much we can do but jam millions of images into the network and hope for the best.
We are convinced, however, that initial data exploration is the key to success. At the very least, it can save a lot of time spent on wrangling and processing image datasets only to find out they are not suited for your use case. But more often than not, good data exploration will provide insights needed to understand your model performance and how to improve it.
Related Posts

Insight
How to Restart an AI Project That Stalled for Lack of Data—with Just 10 Images

Hyun Kim
Co-Founder & CEO | 7 min read

Insight
Three Years of the Few-Shot Object Detection Challenge: Mapping the Global Vision AI Landscape
Hyun Kim
Co-Founder & CEO | 7 min read

Insight
⑪ Germany's Physical AI Moment: Siemens, BMW, and the Robot Unicorn Counteroffensive
Hyun Kim
Co-Founder & CEO | 15 min read

About Superb AI
Superb AI is an enterprise-level training data platform that is reinventing the way ML teams manage and deliver training data within organizations. Launched in 2018, the Superb AI Suite provides a unique blend of automation, collaboration and plug-and-play modularity, helping teams drastically reduce the time it takes to prepare high quality training datasets. If you want to experience the transformation, sign up for free today.