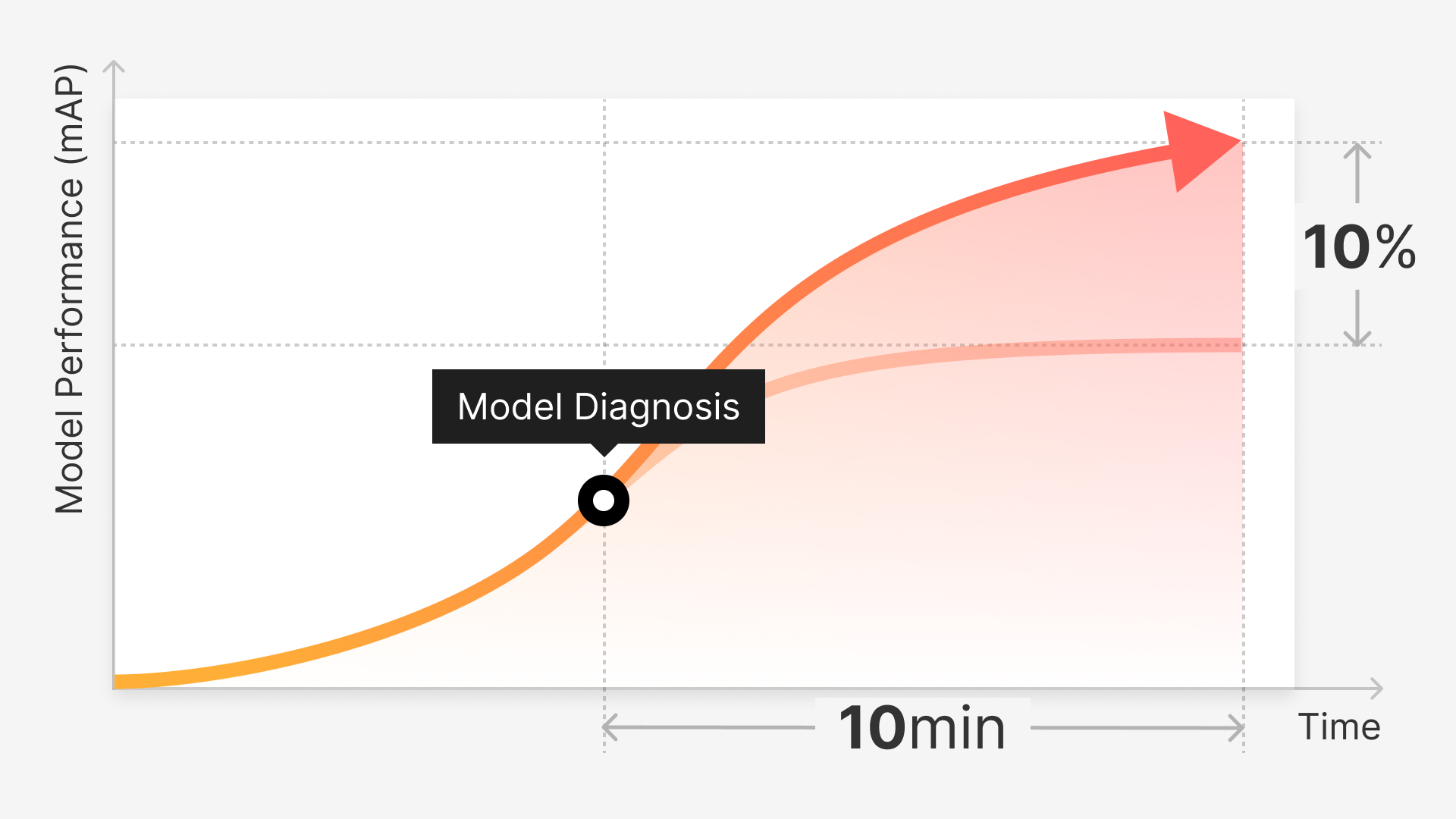
At Superb AI, we are bullish on the fact that you need a solid foundation for your data before being effective with machine learning (see “The AI Hierarchy of Needs”). As we enter the Software 2.0 era (where software iterates through data to retrain and improve ML models that learn from the data we give them), data becomes more important than code. However, preparing high-quality datasets is challenging. Dealing with incorrect or missing data is unglamorous but necessary work. Ingesting from siloed databases is a tedious but crucial task. Knowing how to manage more subtle problems with data (like bias and fairness) is a more difficult organizational challenge.
The Labeling Challenge For Early-Stage Computer Vision Startups
Nested under the umbrella of data preparation is data labeling, which is the task of choosing the correct label given a data point. From multiple conversations with computer vision (CV) practitioners and managers, we noticed that while there are a considerable number of CV-focused enterprises that need solutions to remedy the time and cost restriction with data labeling, there are even more companies and teams that share the same restrictions but also face a human resources constraint. We can assert that companies with 1-to-5 member ML teams, while still primarily focused on high-quality data delivery and iteration, do not have the resources to manage labeling and auditing workflows at scale (or even after the first few iterations yet). This could be due to the lack of a market-proven product/application, resulting in little to no external capital investment.
We believe that companies at this stage better not worry about processes and tools for their first project. Instead, they should build momentum and quickly show the ROI of investing in ML. They should look for projects that focus on one use case and can be completed with a high chance of success within a relatively short timeframe. In other words, the team should do what they need to get the first product through the door.
Why LAUNCH?
Today we introduce the LAUNCH program. For those just getting started, bootstrapping their way through experimental models, or even looking to disrupt the market with an innovative MVP product powered by computer vision, LAUNCH provides fully managed data services that any team can afford. Powered by automation (via our proprietary Custom-Auto-Label product) that eliminates the headache of annotating, managing, and auditing data at scale on a tight timeframe, our startup package empowers even one-person teams to deliver enterprise-quality datasets quickly.
Here are three tangible benefits of LAUNCH:
1. Ideal For Small Teams: We know you’re a small team and don’t have the resources (yet) to constantly prepare large datasets for training. With LAUNCH, we remove the resource constraint and keep you moving forward!
2. Speed: Because our cutting-edge Custom Auto-Label product only requires a small subset of annotations to learn your use case quickly, the time to delivery is drastically reduced. Training only takes an hour!
3. Cost: Our Custom Auto-Label’s price-per-annotation is much more cost-conscious (compared to other managed services)!
How LAUNCH Works
Here are the five steps that will help you get started with your computer vision projects using our LAUNCH program:

Now let’s dive into each of these steps:
1 - Assess
Initially, you will provide us the sample raw dataset that needs to be labeled (Superb AI supports images and videos format). Given that dataset, our internal CV project manager will assess the efficacy of our auto-label product on them. Things we look for include the size of the dataset, the diversity of the object classes, the complexity of the object shapes, and more. If the auto-label results are sub-optimal, we will provide an option for fully managed manual services.
2 - Create Custom Auto-Label
If the auto-label results are promising, you can take advantage of our powerful Custom Auto-Label (CAL) product. For your context, CAL combines the best of both manual and automatic labeling techniques. It leverages subject matter expertise from manual labeling and advanced ML techniques to distill such expertise into an automated solution. First, you want to determine the size of your ground truth set to fine-tune CAL. Then, you train the CAL model on your dataset, which typically takes less than an hour.
3 - Label and Audit
After training is done, you can apply the CAL model to the rest of your data if it reaches a satisfactory detection rate. Then, you can use CAL’s uncertainty estimation to surface hard labels quickly and export them for further auditing. Superb AI’s project manager and labeling team will review and edit labels as needed. Read this post to learn more about our approach to validate label accuracy.
4 - Deliver
The dataset is delivered, and you do a final round of review on the labels. If you want to improve the quality of the labels, you can add more data and manual annotations for the particular classes that CAL did not perform well on. We also provide pre-trained models that have been self-supervised on a variety of popular application scenarios for computer vision, which might work well for your domain (especially if your data belongs to a highly specialized domain).
5 - Iterate
Building high-quality datasets is an iterative process. Using your labeling policy and/or testing tools, you can perform error analysis, gather raw data on instances where CAL underperforms, and manually label their object classes. Doing so enables you to check and capture our CAL’s performance enhancements on those classes as you iterate.
Read our in-depth guide on best practices for using Superb AI’s Custom Auto-Label for a recommended workflow.
How To Get Started With LAUNCH
Superb AI’s LAUNCH manages your labeling projects using an expertly trained team along with a customized auto-label that is fine-tuned to your data. This, in turn, enables you to quickly get your computer vision projects off the ground and justify further investment in their application use cases. You can sign up today and follow the details provided in LAUNCH. You can also request a demo to see the full power of Custom Auto-Label in action.