It’s no secret that data labeling can be expensive and time-consuming. Before you procure, sort through, and label your data, you should carefully consider these tips to ensure you get the most out of your computer vision training data and labeling budget.
Introduction
The ultimate success of your AI and computer vision projects rests on the quality and diversity of your training datasets and their size to a lesser extent. While the algorithm you use is important and being clever about ML feature engineering has an impact, what you ‘feed’ it takes distinct priority. As so many machine learning engineers and data scientists are fond of saying - garbage in, garbage out.
But collecting the right set of data and labeling it while balancing speed, precision, and consistency can be a monumental task. One that is frequently underestimated, leading to inadequate planning. This can take multiple forms, like:
- Why do we have to re-do all of these bounding boxes?
- Why did we spend $50,000 on this dataset when we still need to label 10k more images?
- Why did our data scientists spend so much time this week on data preparation?
- Why didn’t we collect enough X images, or why can’t our model accurately predict X?
- And so on…
Fortunately, you can largely address these challenges by following these simple tips. This article will cover some fundamental tips and give you insights to help you develop a more effective training data and labeling budget. First, let’s answer the fundamental question of why budgeting is so important for computer vision projects.
Why Is Budgeting So Important?
While often overlooked in the planning process, budgeting plays a crucial role in calculating accurate ROI for AI and computer vision projects. Your budget essentially defines how much you can afford compared to how much you are willing to spend, as they are fundamentally different, in terms of your overall tech stack, resources, staff, and more. It’s estimated that 26% of companies that attempt to develop AI systems fail halfway through due to poor or improper budgeting. So it’s critical to get this step right, but unfortunately, most companies are not. In fact, Comet's recent ML practitioner survey found that “68% of respondents (scrap) a whopping 40-80% of their experiments altogether…due to breakdowns that occur throughout the machine learning lifecycle outside of the normal iterative process of experimentation.” Often this occurs because of a lack of sufficient infrastructure and resources, as well as various issues related to inaccurate or misrepresentative data.
Ultimately, this means significant time, resources, and budgets are wasted. For example, they found that there is a serious lag in deployment, to the point where only 6% of respondents can take a model live in under 30 days - the majority took between four to six months to deploy a single ML project and up to three months (46% and 43%, respectively). Conversely, budgets for the types of tools that could solve some of the issues hampering ML teams across the board are overall lacking.
Essentially, a lack of transparency and due consideration into where this money is being spent and the metrics needed to understand what that money is being translated into is slowing down development times. For example, in this same survey, respondents claimed that a lack of resources is one of the biggest pain points slowing down their AI roadmap. If that money simply can’t be found, a more effective budget would allow you to do more with less, perhaps with the help of automated data labeling or human-in-the-loop workflows. To sum things up, even increasing ML budgets for 2022 will only be effective in changing these trends if the money is used wisely. Thankfully, you can mitigate many of these negative trends and challenges during the budgeting process. Here are some key tips you should consider, in no particular order:

Tip 1: Be mindful about how you set up your ML project
The amount of training data you need is often directly proportional to the complexity of the problem you are trying to solve with computer vision. The variance of the classes found within your intended data and use case also directly influences how many labeled examples you’ll need. As the volume, i.e., the amount of data you need to get started and the amount of data you’ll need in the long term to maintain and further evolve your models, directly correlates to and influences the price you’ll end up paying, you should carefully consider what that number is before going forward. That idea stands whether you go with a third party or do the labeling in-house.
While there aren’t many hard and fast rules to follow to determine how much data you need at a minimum, outside of consistent experimentation and experience, you can do a few things to come up with an educated idea:
1. This first one will seem super obvious, but it bears repeating: ask your ML and data science teams if they’ve worked on similar projects or experiments before. They might have a good ballpark number based on past experience, at least enough to get started. You could also review published academic papers based on ML and computer vision experiments that might be similar to your own concept to see how much data they used.
2. Inventory what data is already available and accessible to you, whether that be raw or labeled data, and determine what can and can not be leveraged in some fashion to reduce early costs. It also often makes sense to see if you can leverage any open source or academic datasets, although licensing can sometimes be an issue (especially for commercial applications). Also, if you have an existing system that is already capturing data, try to determine the size of the data corpus.
3. Use a few rules of thumb. They are far from perfect but better than a naive guestimate. You could, for example, apply the rule of 10, which recommends that the amount of training data you need is ten times the number of parameters or degrees of freedom in your model. Or you can follow Peter Warden’s conclusion that 1,000 images per class act as a good baseline based on his analysis of entries from the ImageNet classification challenge. In general terms, you should probably include a few hundred examples of each plausible scenario covered in your use case. Remember that quality will influence your result just as much if not more than quantity. Choosing the appropriate number of parameters or degrees of freedom in your model is also important but ultimately intrinsically linked to your budget and device specs. According to this article from the Computer Science Department at the University of North Carolina at Chapel Hill, degrees of freedom can generally be equal to the number of parameters in the model for simple classification models. For more complex use cases, they discuss deep networks, the degrees of freedom are “generally much less than the number of parameters in the model, and deeper networks tend to have fewer degrees of freedom."
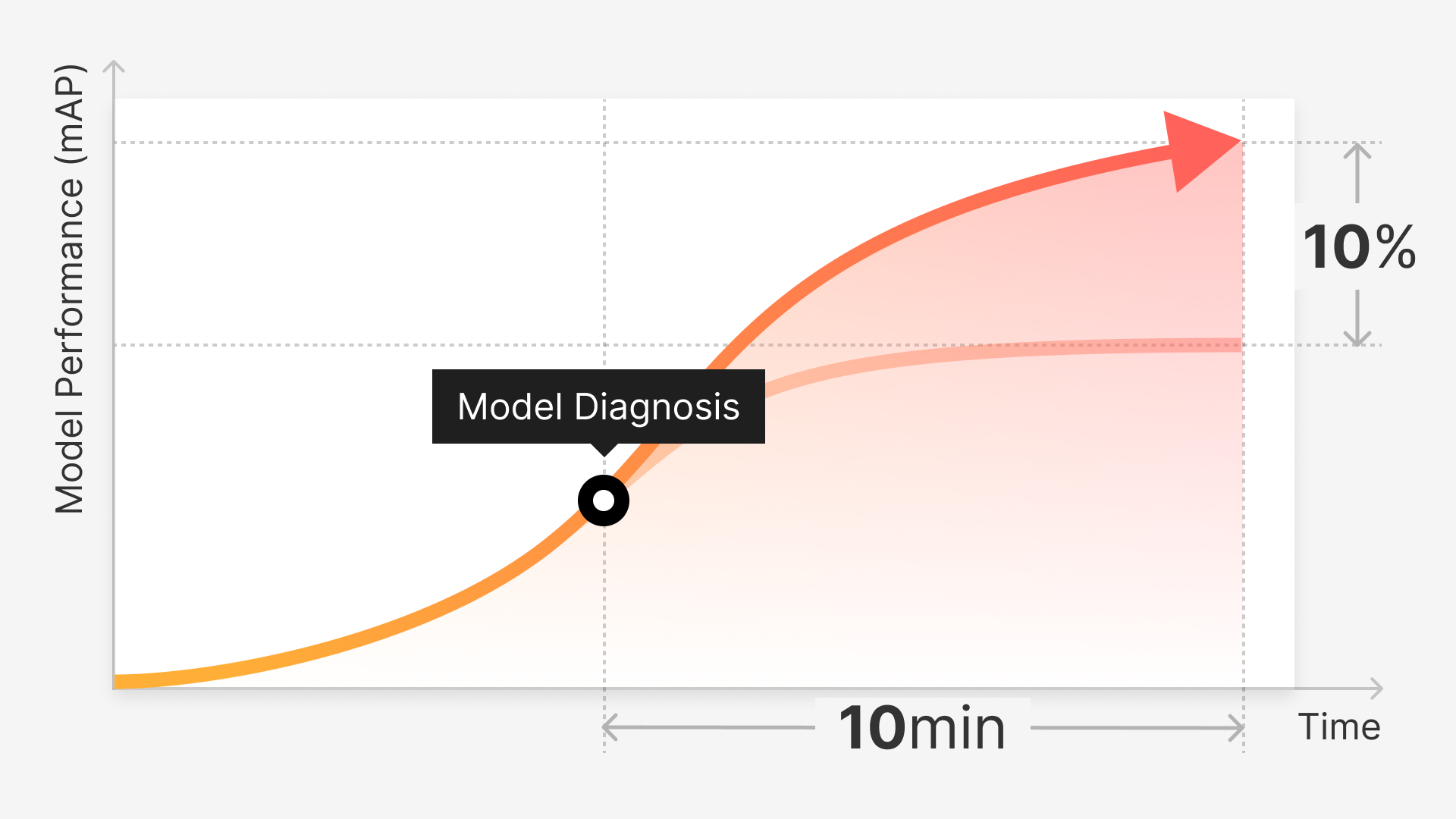
4. Graph it out using a learning curve. If you already have some data, you could design a study to evaluate the ability of the model based on the size of the dataset by plotting your results on a graph. This will give you a general idea of the relationship between dataset size and model skill or performance. It also helps you determine when more data would have diminishing returns. Just make sure your logistic regression skills are up to the task!

Learning Curve of machine learning model with the size of dataset used for testing and training. Source.
5. Finally, you should determine your overall tolerance for errors. The intended role of your model will directly influence how much or how little data you can get away with using. For example, a 1% error rate may be considered catastrophic for a self-driving car model but perfectly acceptable for detecting flaws in a product line (given that the human error rate may be much higher, i.e., it is still a significant improvement using CV and automation). The amount of data you need will directly correlate to how risk-averse or integral to the success of your business your algorithm is.
From our own experience, one of the most effective ways of gauging how much data you need (and ultimately budgeting) is by using an iterative process of collect-label-train-evaluate after determining a baseline using the above steps. Now, what this process actually looks like, plus the fact that you could take many more steps to scientifically determine how much data is needed for your computer vision project, would take a whole blog post - or a series of them - to map out, so let’s move on for now.
Tip 2: Define the factors that could impact your per-label price
Regardless of whether you end up labeling your data in-house or through a third-party service, both the annotation type and the number and complexity of those annotations will likely play a factor in determining your end price. To ensure your estimate is as accurate as possible, you should consider these factors' impact when planning out your budget. Here are a few examples:
- Geographical location from whence your datasets are sourced
- The immediacy of your data requirements and overall volume required
- How you plan to prepare your data, as some tasks require numerous object classes per label
- How long it takes for your data labelers to reach full throughput
- Do increases in throughput impact data quality?
- And so on..
Geographical location, for example, plays a role in raw data collection because acquiring data from an accessible market will be significantly less expensive than from sparse geographical locations like harsh deserts (drones notwithstanding). Essentially, to create a more optimized budget, you need to understand all of the various factors that could cause a fluctuation in your per-label price to plan ahead accordingly.
Tip 3: Leave space in the budget for changes in project scope and focus
While many algorithms are increasingly data-efficient, at least compared to the data-hungry models of the 2000s and 2010s, there will almost always be new edge cases and use cases to tackle. Leaving extra space in your budget for acquiring and labeling more data as needs dictate ensures you don’t get blindsided by unexpected costs. Essentially, don’t use your full budget on initial data collection and preparation as model training and development is almost always more of a journey than a one-time project. While you might not need as much data for your 3rd or 4th model iteration - you’ll probably need more focused data as you start to identify cases that would have the most impact on model performance, perhaps using active learning and other methods.
Tip 4: Watch out for “hidden costs” or pitfalls associated with some labeling workflows
Too often, we think of our labeling budget in terms of a fixed dollar amount per annotator compared to the number of person-hours required to annotate whatever the number of images or videos we need. This approach, however, is far too simplistic because of hidden costs and inefficiencies that you can inadvertently incur during both the planning stage and while setting up your annotation processes. A few examples include:
- Insufficient or unclear labeling guidelines can create confusion and the need for rework (standards aren’t consistent across the board)
- Underestimating the value of the ease of use for labeling platforms (a UI that enables you to quickly and easily train and onboard new labelers and managers leads to cost savings over time)
- Selecting a tool that’s only ‘ok’ for now, but won’t scale well as data volume and/or complexity increase (you’ll be forced back to square one in terms of learning/training if you make the switch)
- Pulling your ML engineers (which can cost upwards of ~$100 an hour) into management and QA tasks that would better be handled by a project manager or labeling lead
Identifying potential pitfalls before launching a new labeling project, or expanding an existing one, helps ensure you stay on target and avoid exceeding your budget due to avoidable rework or operational issues. Finding the right tool from the get-go can save you a lot of headaches and allow you to maintain simple and repeatable workflows, even as the complexities of your tooling infrastructure, workforce, and project management may increase as data volume increases.
Tip 5: Aim for balance in your datasets and understand the impact of QA
The best datasets for computer vision have a high bar across three key characteristics: accuracy, quantity, and variety. Here at Superb AI, we believe that quality is of utmost importance, as poor quality is one of the worst problems. That’s because low-quality data can backfire and hurt you twice. The first is when you train your actual model, especially in terms of performance and consistency, and the second is when your model uses the data to inform future decisions.
Also, carefully consider the approach you intend to take to QA. As so often happens with approaches like crowdsourcing and soft labels, among other similar approaches, the cheapest option may end up being the most expensive in the long run if you need to spend an excessive amount of time auditing and fixing mislabels. Determining your ideal and practical QA workflow during the planning stage can save you a lot of headaches and unexpected expenses down the road.
Tip 6: Consider automated data labeling to make your budget go further
Today, most data labeling is still done manually. But, this has proven time and time again to be a significant barrier to scalability for companies and teams of all shapes and sizes, both in terms of time and cost. Money, of course, isn’t the only cost. Finding the bandwidth for data scientists and other subject matter experts to label more complex data and correct labeling errors can be difficult, if not impossible. Regardless of the reason, and to be clear, there are many pluses and minuses associated with hand labeling, we at Superb AI are big believers in the value of automation when it comes to streamlining data preparation. In fact, we’ve seen some highly encouraging results from clients using our version of automated data labeling as part of their wider workflows, including:
- 10x increase in labeling throughput
- 85% reduction in per-label cost
- 8-10% increase in model performance
But the type of automation you use is just as important as implementing it in the first place in terms of label quality. Model-assisted labeling (in which datasets are pre-labeled and an AI system is trained to predict annotations for unlabeled data) and AI-assisted labeling (in which AI-assisted software helps the labeler perform manual tasks more efficiently) can certainly help. In both cases, however, your labelers must still manually label each example (such as reviewing and confirming each ‘soft label’ in the case of model-assisted labeling), and making modifications to labeled data can be much more time-consuming than just labeling raw data. In the end, they often spend more time fixing mislabels than just labeling them from scratch in the first place, which makes the QA process a costly burden when it comes to scalability.
With Superb AI’s custom auto-label, which can, in essence, be seen as an evolution of earlier more naive model-assisted approaches, you can train a custom model fast to label your datasets at scale. With custom auto-label, unlike traditional model-assisted approaches, you don’t need a ton of labeled data to get started - you can simply train our model with one click and a small ground-truth dataset. Getting started with a much smaller number of labeled data also allows you to iterate easier as more and more data gets labeled. Custom auto-label also outputs uncertainty metrics that greatly shorten your auditing efforts by freeing you to focus on the labels that are most likely to need review rather than random sampling or other less efficient methods.
Conclusion
Like many things related to data labeling and computer vision, building an effective budget for your projects can be a unique challenge and experience that benefits most from careful and considerate planning. Further complicating things is the sheer amount of factors that can change the time and cost of your project on a per-label and operational basis, from the scope and complexity of your use case to your tolerance of errors, preferred pricing structure, and everything in between. By following these general tips, however, you can be sure to avoid any unwanted surprises and put yourself on the path to labeling success. Here at Superb AI, we’d be happy to help, regardless of the stage of your project! Reach out, and we’d be happy to discuss your unique data needs and help you build a solid plan of action.