Insight
Part 1: An Overview of DataOps For Computer Vision

James Le
Tech Advocate | 2021/05/12 | 10 min read

Computer vision applications, in specific, and machine learning applications, in general, rely heavily on data to train the models. In production systems, input data is fed into the model to make inferences. These production systems then use the inference outputs as the basis for the training data that serve as inputs for the next iteration. Because of such a data flywheel, low-quality data can cause a massive negative impact on the system quality. In other words, a computer vision system that does not attend to data quality issues will 100% degrade over time (assuming it is put into production in the first place).
1 - What is DataOps For Data Analytics?
Agile development and DevOps techniques brought a massive revolution in the software industry in the last two decades. DevOps-first companies deploy software releases daily or hourly while reducing the number of software bugs and defects. There have been scientific studies on the correlation between DevOps and the high performance of software development teams.
So what is the main difference between DataOps and DevOps? DevOps transforms the delivery of software systems by software developers. On the other hand, DataOps transforms the delivery of intelligence systems and analytic models by data analysts and data engineers.
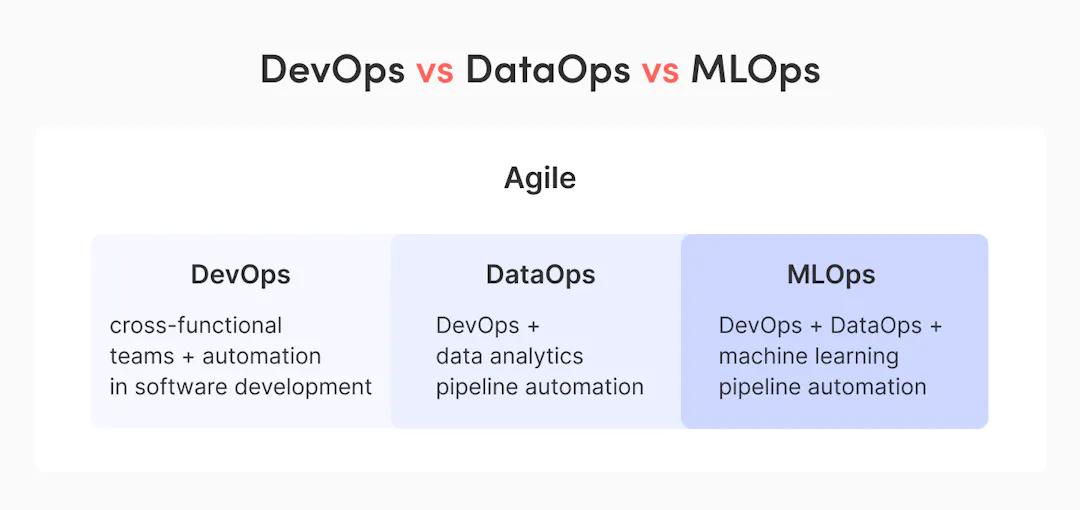
DevOps vs DataOps vs MLOps
How DataOps Relates To Agile, DevOps, and MLOps (Source: DataOps - Adjusting DevOps For Analytics)
The goal of DevOps is to synergize engineering, IT operations, and quality assurance to lower the budget and time spent on the software development and release cycle. With DataOps, we have an additional layer of Data. The goal of DataOps is to synergize data engineering, data analytics, and IT operations to improve the efficiency of acquiring raw data, building data pipelines, and generating actionable insights. If we talk about using data for machine learning applications, we need to bring data science and machine learning engineering into this equation (aka MLOps).
Like how DevOps has made a tremendous impact in software engineering teams, DataOps fundamentally redefines how data analytics teams function. Without DataOps, there is no connection between data pipelines and no collaboration among data producers and data consumers. This will inevitably lead to manual efforts, duplicated code, an increasing number of errors, and a slower time to market.
2 - Why DataOps For Computer Vision?
For companies looking to use Computer Vision (and ML in general) to modernize their operations and decision-making processes, it’s vital to adopt tools that help raise the productivity of data producers and data consumers. These tools should facilitate reliability, discovery, and reuse of data. Let’s unpack three principal reasons why this is important.
Reason 1 - Data Is More Important Than Models
In most real-world machine learning (including computer vision) projects, data is king! Getting better data might be the single best bang for the buck in terms of performance improvement. This contrasts with academic machine learning, which emphasizes the modeling component rather than rethinking the data paradigm.
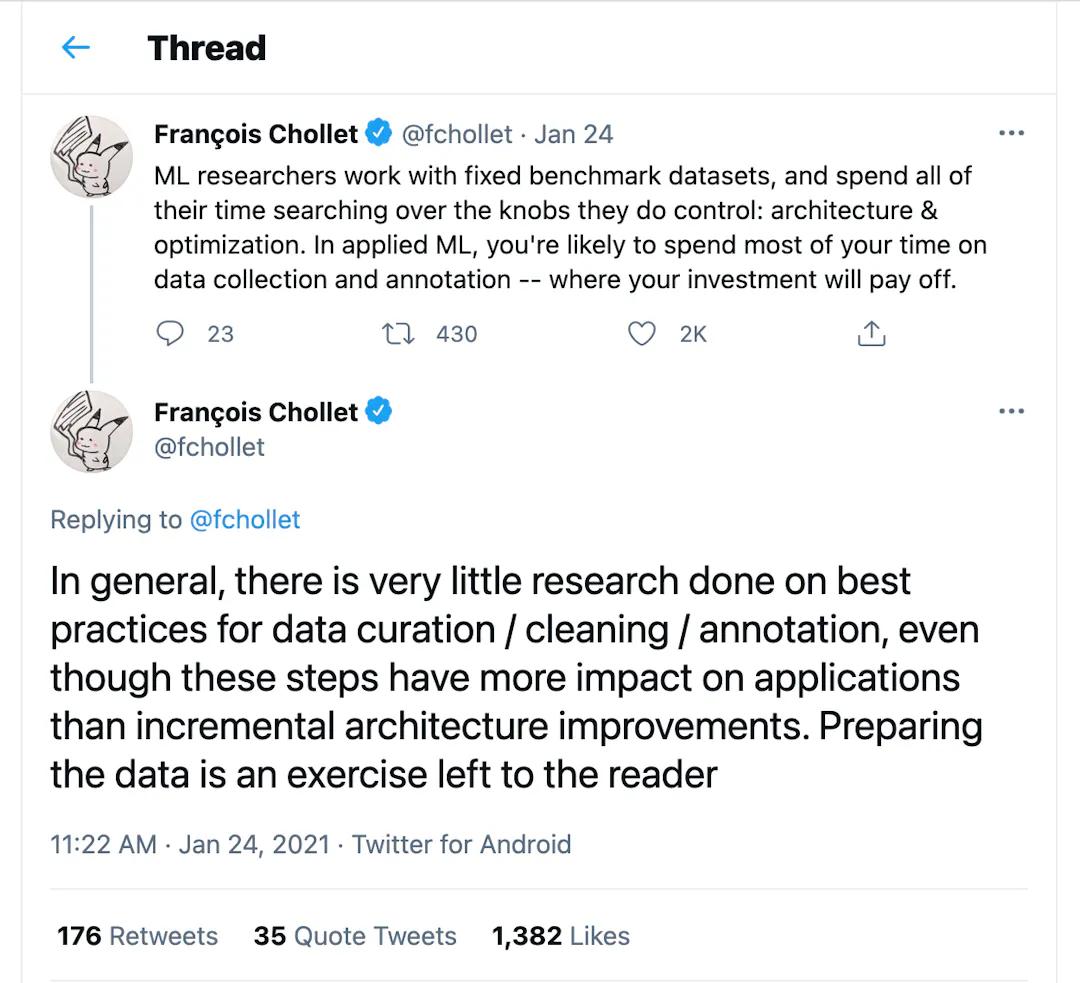
The above sentiment is conveyed by Francois Chollet - the creator of Keras
What other data-related low-hanging fruits are we missing? Shreya Shankar argues that “data-ing” should be equally or more important than modeling. This means finding another piece of data that gives insight into a completely new aspect of the problem, rather than tweaking the loss function. Whenever model performance is bad, we should not only resort to investigating the model architecture and tuning hyper-parameters. We should also attempt to identify the root cause of bad performance in the data.
DataOps helps you explore/visualize, sample/curate, and collect/label only the data points that (1) are worth labeling and (2) yield the most value with respect to a given task. Data observability practices (see principle 4 in section 3) let you accomplish these tasks without too much hassle.
Reason 2 - The Challenge of Unstructured Data Preparation
Error-ridden data labels give error-ridden ML models. Adding to this the growing number of data sources, the fluid nature of modern data, and the increased complexity of downstream usage, it becomes challenging to ensure the data and label quality. Computer vision deals with unstructured data that is schema-free and does not accommodate older forms of data storage, processing, and analysis.
Preparing massive volumes of unstructured data in computer vision poses various challenges: dealing with the unpredictable nature of images and videos, managing the labeling workforce, allocating sufficient labeling budget, addressing data privacy, and more. Before carrying on with the modeling component, the labeled data needs to be audited for correctness and quality. This can only be done via rigorous data processing, data transformation, data augmentation, data visualization, and label validation to see if the data can serve as part of the training data.
DataOps helps teams spend time on gathering high-value data and create valuable datasets by filtering out irrelevant data points with continuous testing (see principle 3 in section 3). With CI/CD, the data engineers can automate the data preparation workflow seamlessly (see principle 2 in section 3).
Reason 3 - The Iterative Nature of Building Computer Vision Products
Taivo Pungas gave an excellent talk about the two loops of building algorithmic products, which include the algorithm development loop and the product development loop.
The algorithm development loop entails (1) building the algorithms using algorithmic frameworks (done by the CV scientists), (2) measuring against dataset with annotation specs (done by the product owners) + large-scale testing tools (done by the ML engineers), and (3) learning from failures with test analysis and manual review tools (done by the CV scientists).
The product development loop entails (1) building products using service and infrastructure frameworks (done by the ML engineers), (2) measuring the products in production via monitoring and logging tools (done by the ML engineers), and (3) learning from failures via dashboards and analyses of live performance data (done by the CV scientists).
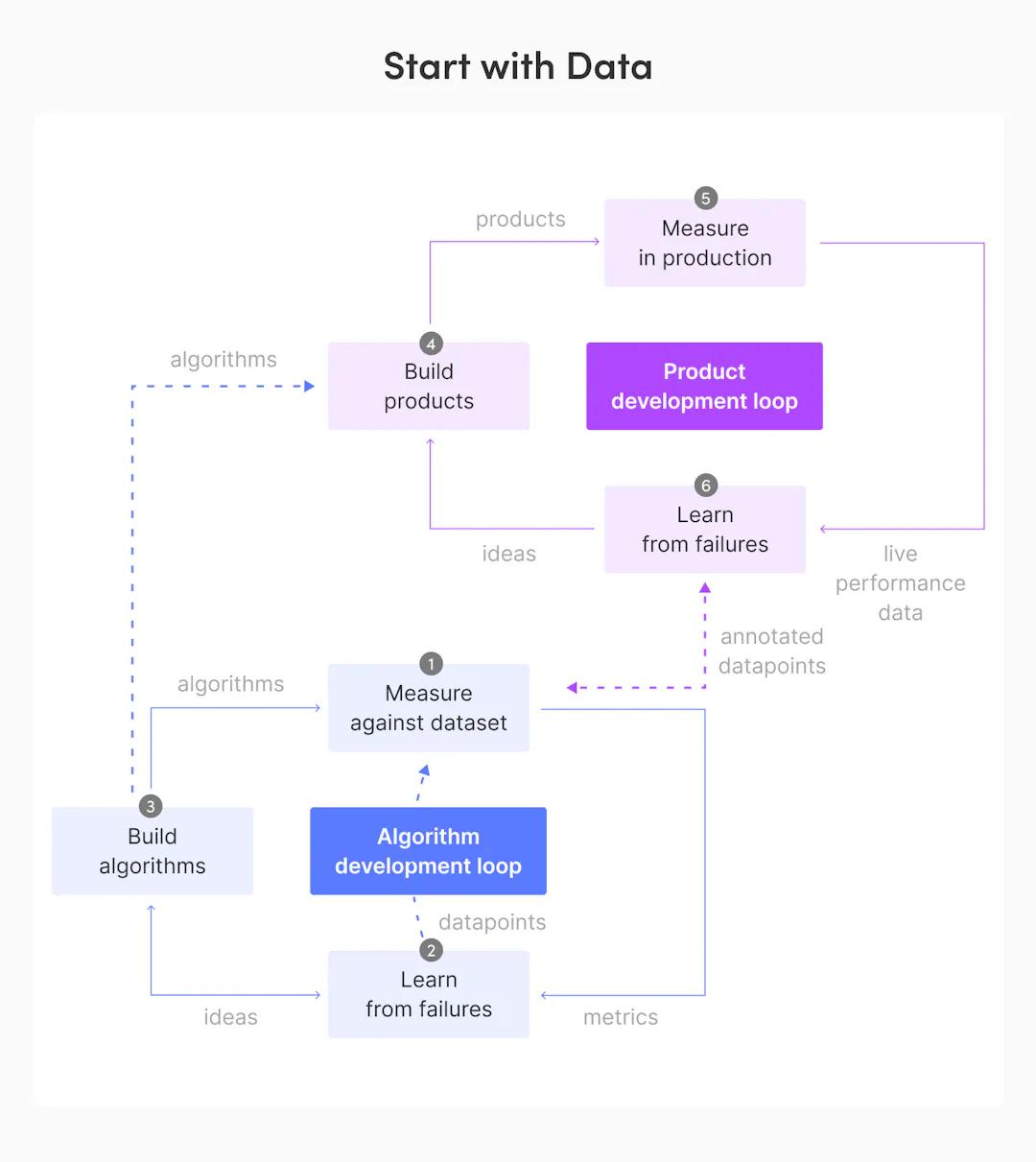
Source: The Two Loops Of Building Algorithmic Products
DataOps can speed up the iteration of these two loops, which work together in at least two ways if we take a data-centric mindset (as seen in the diagram above).
1. After building the algorithms, the CV scientists provide those algorithms to the ML engineers to incorporate into the computer vision products (from step 3 to step 4).
2. After learning from use case failures, the CV scientists sample and annotate only the hard, error-prone data points. Then, they will measure against and possibly combine the new data points with the existing data points for the next iteration of the algorithm development loop (from step 6 to step 1).
Software engineering best practices ensure that both steps are standardized and carried out without issues (see principle 1 in section 3).
3 - DataOps Principles For Computer Vision
Given that the practice of DataOps is fundamental to how data moves across the stack (from data sources to end product), it is crucial to understand the core principles of DataOps. According to Vijay Karan, there are 6 DataOps principles for all data analytics projects, explained in detail below. We will examine how these principles can be adapted for computer vision projects.
Principle 1 - Follow Software Development Lifecycle Guidelines
The first principle is to implement best practices for development. In the data domain, data engineers, data analysts, and data scientists come from different sorts of backgrounds. Given that data engineering and data science are code-heavy, it is imperative for practitioners in such disciplines to follow software development lifecycle guidelines.
In practice, these guidelines include version control (using Git to track code changes), code reviews (pushing or pulling code request), unit testing, artifacts management (with Docker images), release automation, and Infrastructure-as-Code (using Terraform to maintain the infrastructure versions and follow infrastructural changes easily just like code).
Applying these software development best practices for computer vision is straightforward. To get started, I recommend watching these 2-part CVPR 2018 tutorials (part 1 and part 2) on software engineering in computer vision systems.
Principle 2 - Continuous Integration and Delivery
The second principle is to automate and orchestrate all data flows from initial sources to final deployment. You want to automate your deployment with a CI/CD pipeline (with tools like Jenkins or CircleCI) and discourage any kind of manual data wrangling. The best way to go about this is to run your data flows using an orchestrator (like Apache Airflow) for tasks such as backfilling, scheduling, and gathering pipeline metrics. Other open-source industry-leading tools are Luigi and Prefect.
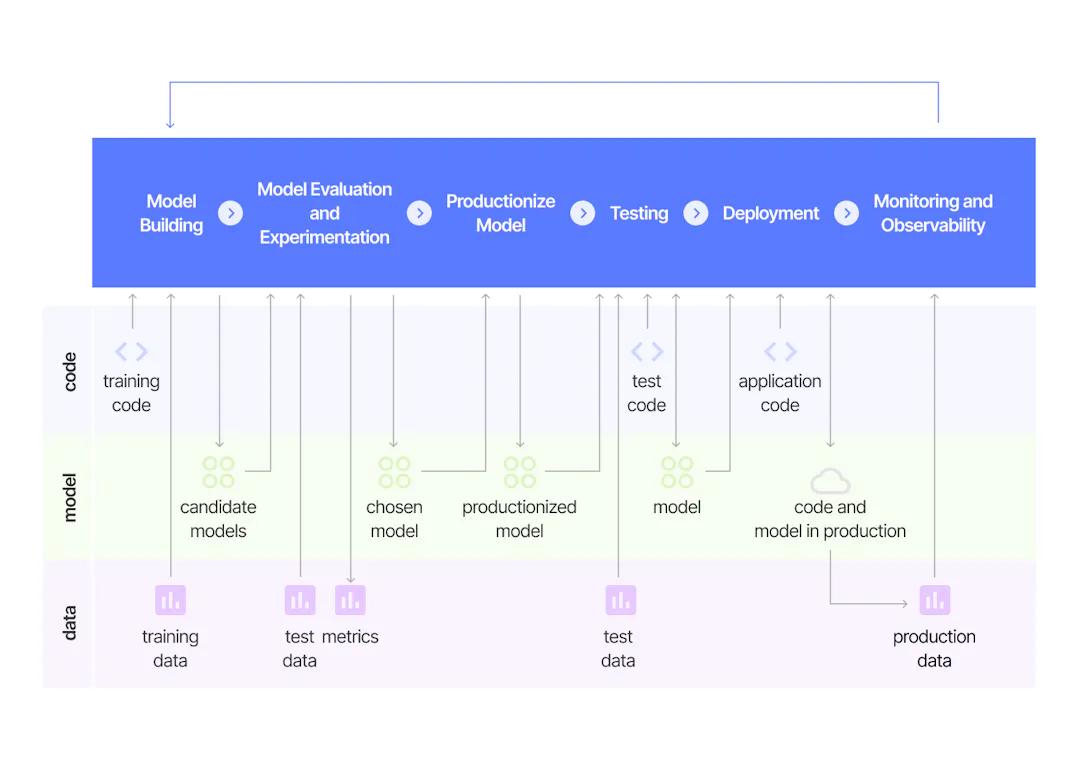
Source: Continuous Delivery For Machine Learning
Applying CI/CD for computer vision is also straightforward. A great resource to get started with is ThoughtWorks’ CD4ML, which is the discipline of bringing Continuous Delivery principles and practices to ML applications. Our friend at Algorithmia also explains the four key stages of a CI/CD pipeline for machine learning that entails source, build, test, and deploy. The main characteristics and benefits of a great CI/CD pipeline are speed, reliability, and accuracy.
Principle 3 - Continuous Testing
The third principle is to test data quality in all stages of the data life cycle. As data is the atomic unit of any data project, you want to validate the data at various stages of your entire data life cycle.
In practice, you definitely want to test the data at the source by writing data unit tests or schema/streaming/SQL tests (depending on the data sources your pipeline is connected to). You then want to validate the data as it goes from the sources to a staging environment, as it undergoes transformation, and as it gets promoted to production and goes into a data warehouse. Next, you want to capture and publish metrics across the aforementioned stages. Finally, you want to reuse your test tools for your following projects (the Don’t Repeat Yourself notion), aka a common testing framework standardized across your data team. A well-developed open-source option is Great Expectations.
For computer vision, continuous testing is trickier. Given the curse of big data labeling, how can we test label quality? It is noteworthy that quality and accuracy in data labeling are not the same things. Dataset quality is about accuracy across the overall dataset, which includes things like the raw data distribution on top of the label consistency. Does the work of all of your labelers look the same? Is labeling consistently accurate across your datasets? Given the human-in-the-loop component (the labelers), building a common testing framework for label quality is not for the faint of heart.
Principle 4 - Improve Observability
The fourth principle is to monitor quality and performance metrics across the data flows. In traditional software development, you can improve the overall software systems by monitoring various kinds of metrics. More importantly, you want to have similar quality metrics and performance metrics across your data flows (to achieve proper SLAs, for instance).
In practice, the first step is to define your data quality metrics, which can be broken down into technical metrics (i.e., the number of rows in a data schema after the data ingestion phase), functional metrics (driven by the business), and performance metrics (to capture how much time it takes to reach expected SLAs). The second step is to visualize these metrics (with Looker or Power BI) to appropriate data stakeholders so that they can take meaningful actions using meaningful alerts. SaaS solutions from startups like Monte Carlo Data, Accel Data, and Datafold can address this whole data observability principle more sophisticatedly.

Source: What Is Data Observability?
What does observability look like for computer vision? I think it would be a combination of data observability and model observability.
- Our friend at Monte Carlo defines the five pillars of data observability to be freshness, distribution, volume, schema, and lineage. In the context of computer vision, these translate to (1) how up-to-date the labels are updated, (2) how the labels are distributed within an image (or changing distribution in a video), (3) how big the number of images is, (4) how the labels are visualized and formatted, and (5) how the images are versioned.
- Our friend at Arize AI defines model observability as the process of collecting model evaluations in training, validation, and production environments, then typing them with analytics to allow one to connect these points to solve the ML engineering problems. The objective is to understand the cause behind model actions and build workflows to improve. This translates directly into the computer vision workflow, where the output predictions from one model serve as the input training data for the next model iteration.
Principle 5 - Focus on Data Semantics
The fifth principle is to build a common data and metadata model. This helps a lot in driving the DataOps and delivering the value quickly. However, most organizations face a significant challenge because the data comes from different sources, and everybody looks at the system from different angles.
Borrowing from the domain-driven design concept in software development, you want to identify similar terminologies across different areas and share them across different teams (engineering, data, and business). Tools like dbt enable you to combine different data sources and put them into a common data warehouse. An enterprise-focused approach is to invest in a data catalog to share data knowledge more broadly across the data organization (Atlan, Atlation and Collibra for SaaSs or Amundsen, DataHub, and Marquez for open-source). With a data catalog, each data owner knows exactly what he/she is provided with.
For computer vision, this means creating a repository of all your image and video data from various sources - including notes on their structure, quality, definitions, and usage. Ideally, you allow the users to access the metadata (like JSON objects) alongside the data itself. One thing that is still hard, in my opinion, is versioning control for unstructured data. Solutions from Pachyderm and Quilt are promising options that are on my horizon. The emerging paradigm of data lakehouse can store, refine, analyze, and access unstructured data, but yet to tackle version control. Furthermore, a sophisticated solution that provides a graphical representation of the data assets’ lineage can simplify future data governance and compliance concerns.
Principle 6 - Cross-Functional Teams
The sixth principle is to empower collaboration among data stakeholders. There are different ways to structure your data teams, but the best approach is to embed the data thinking into every functional team. This is similar to the agile principle, where you want to build a cross-functional team with no division between key functions. Such teams define important metrics and KPIs together, and craft shared objectives with the business goals. Furthermore, to remove potential bottlenecks for data usage, you want to set up self-service data monitoring (Soda Data) and democratize access to the data (Immuta Data).

Data Stakeholders Uniting Around Business Requirements (Source: DataOps - Adjusting DevOps For Analytics)
While building computer vision applications, the three major stakeholders are data producers (such as labelers and labeling project managers), data consumers (such as data engineering and ML engineering), and DevOps practitioners (software engineers and IT operations professionals). I believe the collaboration process between them is still ad-hoc at most organizations, and there is room for tools that can make this process more efficient.
DataOps helps bring rigor, reuse, and automation to the development of computer vision pipelines and applications. DataOps can transform the data preparation process from ad-hoc to automated, from slow to agile, and from painful to painless. At Superb AI, we are a heavy advocate for DataOps principles. The Superb AI Suite enables computer vision teams to build time- and cost-efficient data labeling pipelines (from raw data ingestion to labeled data delivery) by fostering collaboration and automation. In part 2 of this DataOps for Computer Vision series, we will examine the key challenges of preparing image/video data and propose Superb’s “work-in-progress” DataOps pipeline to address these challenges.
Related Posts

Insight
⑪ Germany's Physical AI Moment: Siemens, BMW, and the Robot Unicorn Counteroffensive

Hyun Kim
Co-Founder & CEO | 15 min read

Insight
⑩ Big Tech Physical AI Trends (2): Tesla vs. Amazon Strategy Breakdown
Hyun Kim
Co-Founder & CEO | 10 min read

Insight
⑨ Big Tech Physical AI Trends (1): NVIDIA vs. Google Strategy Breakdown
Hyun Kim
Co-Founder & CEO | 7 min read

About Superb AI
Superb AI is an enterprise-level training data platform that is reinventing the way ML teams manage and deliver training data within organizations. Launched in 2018, the Superb AI Suite provides a unique blend of automation, collaboration and plug-and-play modularity, helping teams drastically reduce the time it takes to prepare high quality training datasets. If you want to experience the transformation, sign up for free today.