Insight
Part 2: Three DataOps Challenges That Most Computer Vision Teams Struggle With

James Le
Tech Advocate | 2021/07/05 | 7 min read

Introduction
Implementing state-of-the-art architectures, tuning model hyperparameters, and optimizing loss functions are the fun parts of machine learning. Sexy as it may seem, behind each model that gets deployed into production are data labelers and data engineers responsible for building a high-quality training dataset that serves as the model’s input.
For small teams with a handful of data engineers or data labelers, building training datasets is easy. They’re familiar with every dataset, and it doesn’t take long to prepare the data they need. But for larger organizations, the amount of data dwarfs any one person or team’s ability to understand all of it. This is even more difficult for image and video data used in computer vision, which does not accommodate traditional forms of data storage, processing, and analysis.
In part 1 of this series, we provided an overview of DataOps for computer vision by (1) introducing the concept of DataOps for data analytics, (2) arguing for the case of using DataOps for computer vision, and (3) laying out the 6 DataOps principles for any enterprise computer vision system. This part 2 will examine the three data-related challenges that any computer vision teams have to deal with. Furthermore, we will propose specific functions of an ideal DataOps platform to address these challenges.
Let’s dive in!
1 - Curate High-Quality Data Points
Data curation is the process of discovering, examining, and sampling data for a specific analytics/prediction task. It is an inevitable data management problem for any organization that wants to extract business value from data—otherwise, the adage “garbage in, garbage out” holds. In the context of machine learning, data curation entails collecting, storing, and archiving the data for future reuse.
In the context of computer vision, data curation is massively under-rated as there is no streamlined method to understand what kind of data has been collected and curate it into a well-balanced high-quality dataset, besides writing ETL jobs to extract insights. However, the value which can be created through good data curation is tremendous. On the other hand, the mistakes that happen here will cost you dearly later on when low accuracy and high costs occur.
Unfortunately, data curation remains the most time-consuming and least enjoyable work of data scientists and engineers. Data curation tasks often require substantial domain knowledge and a hefty dose of “common sense.” Existing solutions can’t keep up with volume, velocity, variety, and veracity in the ever-changing data ecosystem. Furthermore, these solutions are narrow because they primarily learn from the correlations present in the training data. However, it is pretty likely that this might not be sufficient, as you won’t be able to encode domain knowledge in general and those specific to domain curation, such as data integrity constraints.
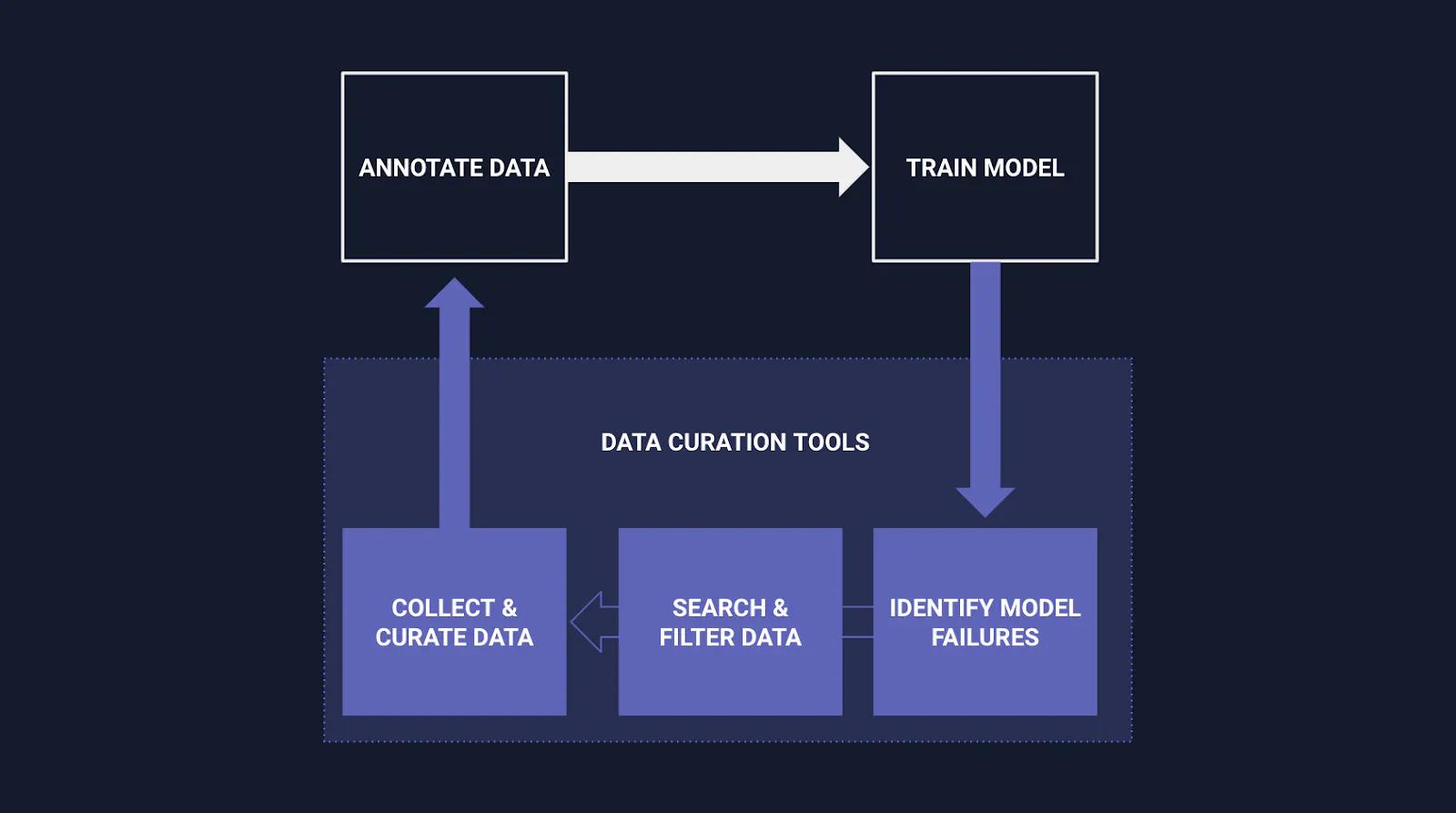
The Role Data Curation Tools Play in Machine Learning (Adapted from Siasearch)
A functional DataOps platform for computer vision should have data curation capabilities that enable data and ML engineers to understand the collected data, identify important subsets and edge cases, and curate custom training datasets to put back into their models. More specifically, this platform should be able to:
- Visualize massive datasets: Obtain key metrics, distributions, and classes of the datasets regardless of their format.
- Discover and retrieve data with ease: Quickly search, filter, and sort through the entire data warehouse by making all features easily accessible.
- Curate diverse scenarios: Identify the most critical dataset slices and manipulate them to create custom training sets.
- Integrate seamlessly with existing workflows and tools.
2 - Label and Audit Data at Massive Scale
Training computer vision models require a constant feed of large and accurately labeled datasets. The label accuracy is essential because the algorithm learns from ground-truth data, so the label quality ultimately defines the model quality. Therefore, any error induced by the data labeling process will negatively impact the model performance. However, this typically requires a considerable time and capital commitment, especially since most of the labeling and quality assurance is done manually by humans.
Based on our conversations with 100+ data and ML engineers, data labeling and auditing are major bottlenecks within the data preparation pipeline for computer vision systems. Interestingly enough, based on our surveys and interviews, this bottleneck applies to teams that just started a new computer vision project and mature teams with models already in production.
- Companies or teams in the early stages of ML development want to utilize AI somehow, but they do not have any models pre-trained on niche or domain-specific datasets.
- Mature teams with models in production are well-versed in the ML development and deployment lifecycle. They tend to have sophisticated pre-trained models and are focused on further improving model accuracy. They want to identify where the model is failing and manually prepare datasets to address those edge cases. They also want to address issues like data and model drift (covered below), where the accuracy of the trained model degrades over time as the characteristics of the data (upon which the model is trained on) changes over time.
To get a better sense of how much it takes for ML teams to create a training set, let's do a quick back-of-envelope calculation here (from our experience):
- A bounding-box annotation typically takes a human labeler anywhere from 2-5 seconds.
- A 100,000-image dataset with 10 objects per image will take around 600-1,500 man-hours to label.
- You will spend considerably more time and money if you add the time to validate and audit the labels.
In addition, let's say you have a successful Proof-of-Concept project and now want to deploy models in production. As your project progresses, you'll have to constantly collect and label more data to improve the model performance. When you rely on brute-force manual labeling, the labeling cost increases linearly proportional to the number of labels created. What makes things even worse is that you will need exponentially more data and more money as your model performance improves. Unfortunately, your model performance plateaus as the number of labels increases. In other words, the marginal gain of your data diminishes to improve your model performance.
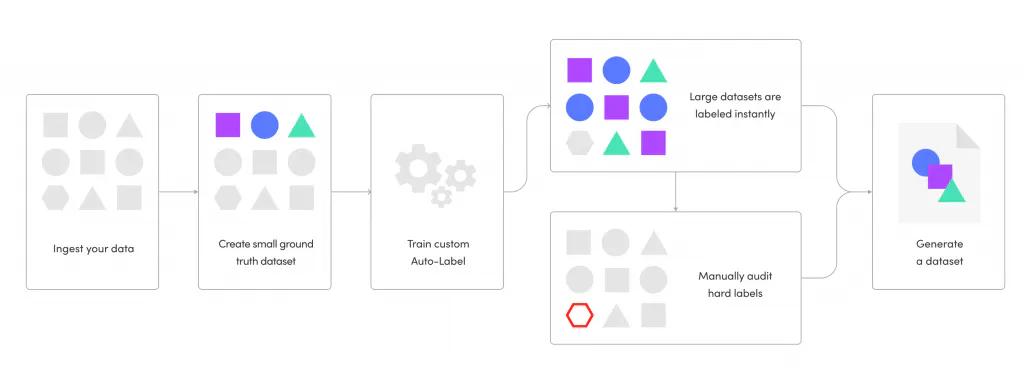
Custom Auto-Labeling Process
An effective DataOps Platform for computer vision must address these two expensive steps of labeling the data and auditing the labels. These issues are managed effectively in Superb AI’s Suite product, which uses a powerful capability called Custom Auto-Label to label large datasets in a short timeframe. Combining Custom Auto-Label with Suite’s Uncertainty Estimation and management capabilities, teams can immediately identify hard labels, build active learning workflows for auditing, and deliver datasets in a matter of days.
Our customers have already seen immense benefits from being able to quickly spin up a model trained on their specific datasets for the purpose of rapid labeling. Besides relieving the financial burden, improving the time to delivery has been becoming extremely critical, both for getting projects off the ground and helping with rapid model optimization.
3 - Account For Data Drift
Computer vision systems suffer from a major limitation that constrains their accuracy on real-world visual data captured at a specific moment in the past. They have a built-in assumption where the mapping function of input data used to predict the output data is assumed to be static. In practice, the visual data drifts over time because it comes from a dynamic, time-evolving distribution. This phenomenon is known as data drift. In these cases, predictions made by a model trained on historical data may no longer be valid, and the model performance will begin to decrease over time. As more ML applications move toward streaming data, the potential for model failure due to data drift exacerbates.
There are various causes of data drift:
- Upstream process changes - changing user behavior or changing business KPIs.
- Data quality issues - systems go down due to increasing web traffic.
- Natural drift in the data - temporal changes with seasons.
- Covariate shift - change in the relationship between features.
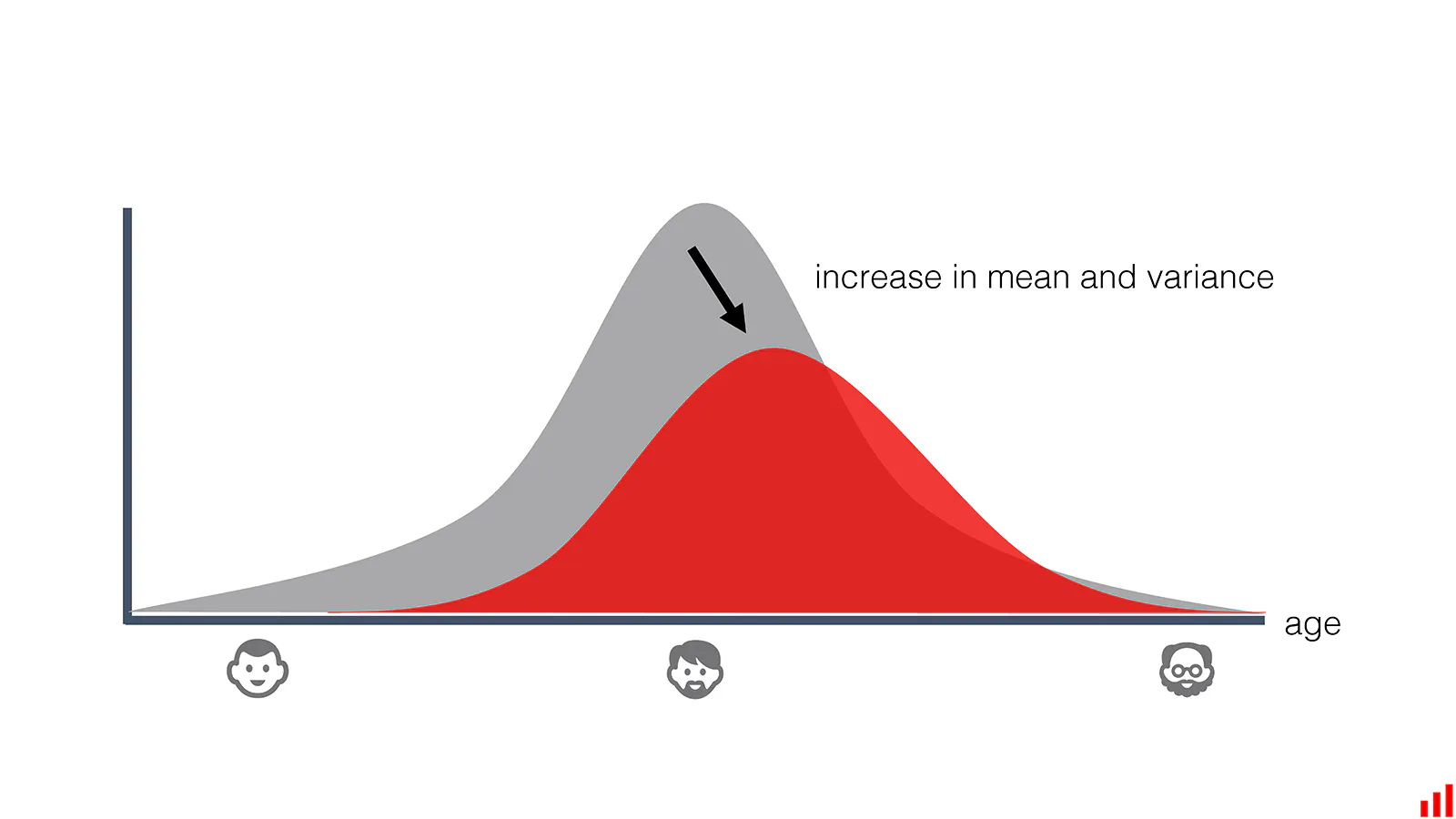
Change In The Distribution Of The “Age” Feature (EvidentlyAI)
In the research realm, data drift is well studied in the domain of low-dimensional, structured data analysis. A widely-used technique is Kalman filtering, which uses a series of measurements observed over time, containing statistical noise and other inaccuracies. It produces estimates of unknown variables that tend to be more accurate than those based on a single measurement alone by estimating a joint probability distribution over the variables for each timeframe. However, it can’t cope with drift in high-dimensional, unstructured data such as images and videos.
A robust DataOps platform for computer vision that can identify where the distribution changes occur can even help to reduce the amount of labeling. This is clearly favorable because acquiring labeled data is very expensive, as explained above. More specifically, this platform should be able to:
- Detect when data drift happens and alert the ML engineers to the potential occurrences of concept drift during the running process of their deployed ML models.
- Analyze where and why drift happens: A simple numerical measure of drift degree is not sufficient. Additional useful information to explore includes the data distribution and the distribution changes over time. This ties to the concept of observability that has surged recently.
- Overcome drift and improve performance: Also known as drift adaptation, this means adapting the model to new data, ideally reusing parts of the old model.
Conclusion
Data is the most important component of any ML workflow that impacts the performance, fairness, robustness, and scalability of the eventual ML system. Unfortunately, the data work has traditionally been underlooked in both academia and industry, even though this work can require multiple personas (data collectors, data labelers, data engineers, etc.) and involve multiple teams (business, operations, legal, engineering, etc.).
Google recently released a paper that illustrates the phenomenon of data cascades and the challenges of ML practitioners across the globe working in important ML domains, such as cancer detection, landslide detection, loan allocation, and more. In particular, the paper proposes a few ways to address data cascades; two of which are:
- Develop and communicate the concept of goodness of the data that an ML system starts with, similar to how we think about the goodness of fit with models. This includes developing standardized metrics and frequently using those metrics to measure data aspects like phenomenological fidelity (how accurately and comprehensively the data represents the phenomena) and validity (how well the data explains things related to the phenomena captured by the data).
- Build incentives to recognize data work, such as welcoming empiricism on data in conference tracks, rewarding dataset maintenance, or rewarding employees for their work on data (collection, labeling, cleaning, or maintenance) in organizations.
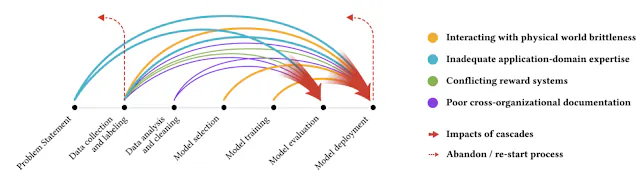
Different color arrows indicate different types of data cascades, which typically originate upstream, compound over the ML development process, and manifest downstream. (GoogleResearch)
A DataOps platform can help provide “good” training datasets used in the ML system. How to assemble a “good” dataset? By curating valuable samples for labeling. By accelerating the labeling workflow. By observing data changes and taking appropriate actions. This blog post has hammered home these three points, detailing the why and the how.
To build incentives that recognize work on data, enterprises need to structure a proper DataOps team. The goal of this team is to create a corresponding dataset that comprehensively and accurately reflects what the product intends to achieve for every ML task. At the moment, there is no playbook to follow nor best practices to implement. In part 3 of this DataOps for Computer Vision series, we will dive into the key personas that make up an ideal DataOps team and the organizational structure needed to take advantage of the valuable data work.
At Superb AI, we found this exciting: DataOps for Computer Vision is both under-appreciated and critical. We are building a DataOps platform that powers curation, labeling, and observability to help Computer Vision teams be more impactful. If this is interesting, drop me a line at us-marketing@superb-ai.com or contact our Sales team.
Related Posts

Insight
How to Restart an AI Project That Stalled for Lack of Data—with Just 10 Images

Hyun Kim
Co-Founder & CEO | 7 min read

Insight
Three Years of the Few-Shot Object Detection Challenge: Mapping the Global Vision AI Landscape
Hyun Kim
Co-Founder & CEO | 7 min read

Insight
⑪ Germany's Physical AI Moment: Siemens, BMW, and the Robot Unicorn Counteroffensive
Hyun Kim
Co-Founder & CEO | 15 min read

About Superb AI
Superb AI is an enterprise-level training data platform that is reinventing the way ML teams manage and deliver training data within organizations. Launched in 2018, the Superb AI Suite provides a unique blend of automation, collaboration and plug-and-play modularity, helping teams drastically reduce the time it takes to prepare high quality training datasets. If you want to experience the transformation, sign up for free today.