Insight
Part 3: Building a DataOps Team for Your Computer Vision Projects

James Le
Tech Advocate | 2021/11/17 | 7 min read

Introduction
Common reasons behind computer vision projects failing are (1) a failure to make it to production, (2) the time where your coveted computer vision scientists and engineers spend too much of their time on menial tasks, and (3) increased governance risk. It is essential to invest in foundational activities for your computer vision teams to tackle these challenges - like getting production-quality labeled training data via data operations (DataOps) tools and processes.
In part 1 of this series, we provided an overview of DataOps for computer vision by (1) introducing the concept of DataOps for data analytics, (2) arguing for the case of using DataOps for computer vision, and (3) laying out the 6 DataOps principles for any enterprise computer vision system. In part 2, we (1) examined the three data-related challenges that any computer vision teams have to deal with, (2) proposed specific functions of an ideal DataOps platform to address those challenges, and (3) argued that enterprises need to structure a proper DataOps team to build incentives that recognize their essential work on data.
Part 3 underscores (1) the key personas that make up an ideal DataOps team and (2) the organizational structure needed to take advantage of the valuable data work. But first, let’s look at how to leverage DataOps when scaling your computer vision projects.
Guidelines for DataOps Implementation
DataOps represents a culture change that focuses on improving collaboration and accelerating dataset delivery by adopting lean and iterative practices, where appropriate, to scale data pipeline operations from acquisition to delivery. As seen below, a typical DataOps pipeline for computer vision consists of data acquisition, annotation, debugging, augmentation, transformation, and curation stages. Hence, to implement DataOps, enterprises need to primarily focus on:
- People to ensure collaboration across a cross-functional team that works toward shared outcomes in the form of data accessibility in a governed fashion.
- Tooling to support data quality assurance, data transformation, data labeling, automated data testing, data pipeline orchestration, and more.
- Governance to bring the appropriate balance of control, accessibility, accountability, and traceability of data usage behavior through access control, metadata management, and data versioning.
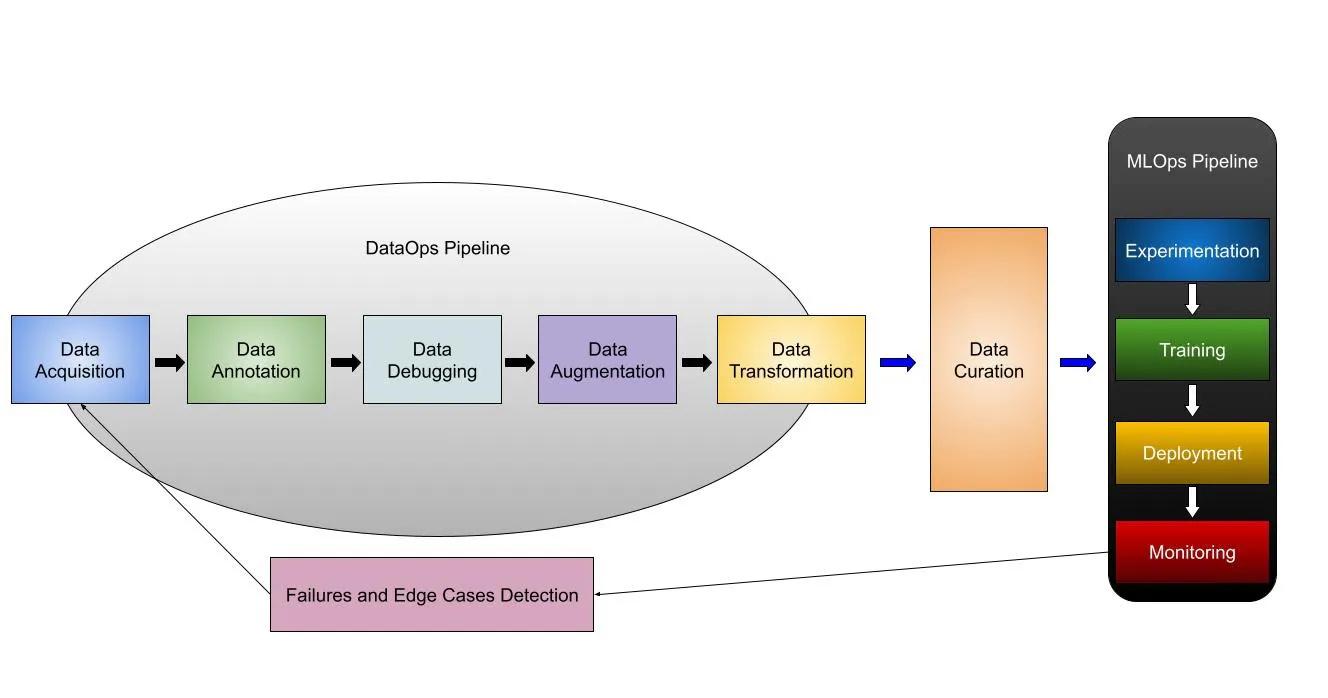
In brief, DataOps helps provide the agility, efficiency, and continuous assessment of data that is governed throughout its life cycle. The goal is to create data pipelines with orchestration tools that can be provisioned automatically within production environments, while ensuring governance and security across development and production environments.
The Goal of The DataOps Team
Computer vision practitioners from an academic background are often hired to do technical work with algorithms, meaning a strong background in mathematics and computer science is needed. However, these skills don’t translate well into assembling a good dataset (thanks to Taivo Pungas for coming up with this list), which requires:
- Curating high-quality data samples for labeling.
- Manually or automatically labeling thousands to millions of images.
- Collaborating with Product, Engineering, Analytics, and other functions to make judgment calls in uncertain cases.
- Documenting labeling policies and changes to them.
- Building the most effective labeling workflows using a combination of in-house, open-source tools, SaaS solutions, and outsourced services.
- Designing data pipelines for moving between data sources, labeling tools, and MLOps tools.
All activities can be brought under a single function of DataOps, whose mission is to assemble good datasets. Ideally, for every prediction task, this team (1) provides a corresponding dataset that comprehensively and accurately reflects what the product intends to achieve and (2) maintains its accessibility and freshness for downstream purposes.
When building a DataOps team, the ML/Data leads need to figure out their team composition and high-level structure for the DataOps team. They rightly do so; having a strong DataOps team is not a luxury anymore, but essential to the survival of any ML-first company today.
Where Are You In Your ML Data Management Journey?
Before building a DataOps team, you must realize where you are in your “ML data management journey” because this will directly affect the structure of your team. If you’re not familiar with ML data management as a category, Astasia Myers provides a solid primer on the tools that help improve ML models by improving datasets. Essentially, these tools extract data quality best practices from the data analytics world and apply them to ML. They help the DataOps team curate good training datasets, detect mislabels, and identify challenging edge cases.
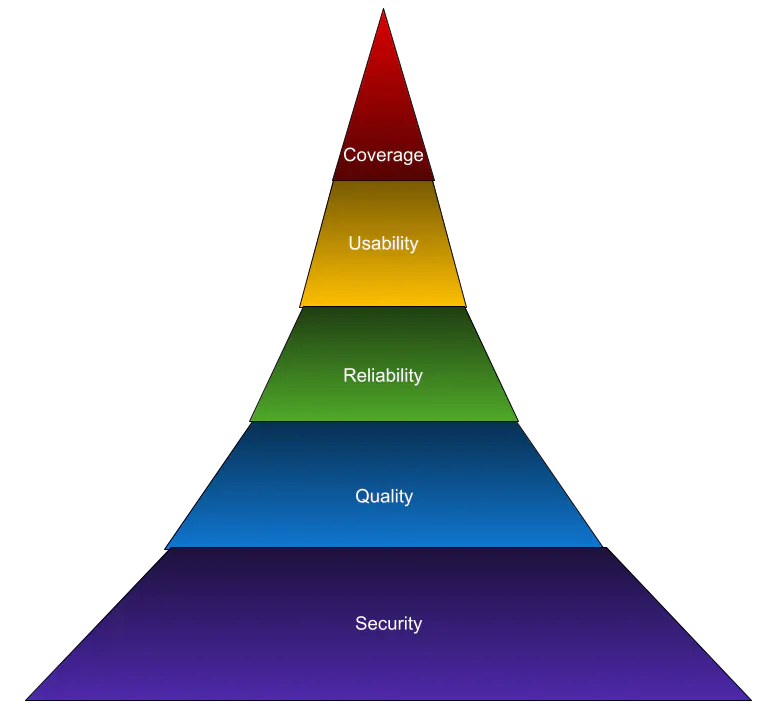
To evaluate ML data management maturity, we need to define the fundamentals mentioned here (Maslow’s hierarchy of needs heavily influences this). If we try to assemble a good training dataset, what are the fundamental things that enable such a goal?
- The first requirement for any company working with data should be protecting their customers. Security has to be your first priority. By protecting your customers, you protect yourself.
- The second pillar is data quality. Real sustained growth and velocity come from avoiding disasters as much as going faster. Data quality is an investment in terms of risk mitigation by protecting yourself from bad decisions. Your team can lean into test-driven development so that they can test for data quality right from the beginning.
- The third pillar is reliability. Any good solution has to be dependable, and this is the nuts-and-bolts of DataOps: defining SLAs, understanding user needs, and measuring how well you perform from a reliability perspective.
- The fourth pillar is usability. Engaging in data and ML engineering is a creative enterprise. It’s about asking questions and using the answers (to those questions) to either take action or ask better questions. Whenever you engage in a creative endeavor, if you struggle with your tools, your creativity is inevitably constrained. If the data curators struggle with understanding ground-truth labels or visualizing images, they won’t be able to curate the most relevant data samples. User experience becomes critical.
- The last pillar is coverage. Do we have the information that describes the event we are trying to understand? If you don’t resolve the first four, there is no point in giving people data. You also want to keep the scale and scope under control. Constrain your scope, target the most valuable question to answer, and work backward from there.
The better your organization meets this “data hierarchy of needs,” the more mature your ML data management capabilities are.
Key Players On a DataOps Team
We believe that an ideal DataOps team should be composed of the core functions outlined below:
- Data Labeling Manager (DLM): They often work with either in-house and/or offshore labeling teams to help scale the throughput of data labeling. They define labeling instructions, inspect the work of the labelers, and decide how to handle complex or ambiguous scenarios.
- Data Engineer (DE): They are responsible for designing, building, and maintaining datasets that can be leveraged in ML projects. As such, data engineers closely work with ML engineers. They can actually be the ML engineers themselves, especially if your organization has mature tooling for setting up data pipelines, versioning models, and orchestrating model retrains.
- Data Curator (DC): They are experts in their respective data domains, visualizing and manipulating ML datasets. They are agile and straddle the line between the data side and the business units to help bridge the gap and improve efficiency. They can be assigned based on the data/model type they are responsible for (i.e., image classification, object detection, semantic segmentation) or based on the customer/geography they serve (i.e., North America, APAC, EMEA). Their knowledge of the business goals and the ML capabilities can inform how best to prioritize data curation to improve the ML system.
- Head of DataOps: They provide strategic oversight to the DataOps team. Their goal is to create an environment that allows all different parties to access the data they need painlessly, build the skills of the business to draw meaningful insights from the data, and ensure data governance. They also act as a bridge between the DataOps team and other ML/Product/Engineering units, serving as a visionary and a technical lead.
How To Structure Your DataOps Team?
There is no ideal structure for a DataOps team. Considering that your organization’s data needs will likely evolve rapidly, your DataOps team structure should also adapt accordingly. For this reason, we don’t prescribe a given structure, but rather present the most common models and how they can be suited to different types of businesses.
Centralized Model
In a centralized model, the DataOps team has access to all the data and serves the whole organization in various projects. All data engineers, curators, and labeling managers within this team are managed directly by the head of DataOps. With this structure, the DataOps team collaborates in tandem with the ML stakeholders based in ML units in a consultant-type relationship.
This flexible model adapts to the continuously evolving ML needs of a growing business. If you’re at the beginning of your ML data management journey, this is the structure we recommend. The DataOps team’s initial projects will seek to bring visibility to the business, ensuring all ML teams in your organization have the high-quality training data they need.
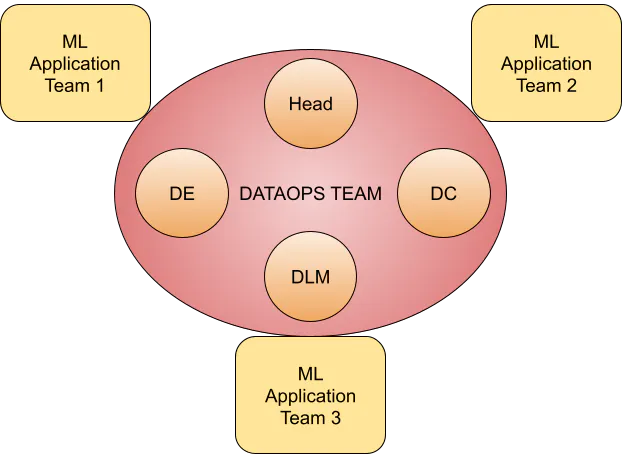
Pros
- The DataOps team can help with a wide variety of ML projects while working on its own agenda. As such, the team can prioritize ML projects across the organization.
- There are more opportunities for talent and skill development in a centralized team. Data labeling managers, data engineers, and data curators can benefit from their peers’ insights.
- The Head of DataOps has a centralized view of the company’s ML strategy and can assign data people to ML projects most suited to their capabilities.
Cons
- There is a high likelihood of a disconnect between the DataOps team and other ML teams. Data engineers and data curators are not immersed in the day-to-day activities of other teams, making it difficult for them to identify the most relevant datasets to build.
- There is the risk for the DataOps team to become a “support” function.
- Other ML units might feel like their data needs are not adequately addressed or that the planning process is too slow.
Decentralized Model
In a decentralized model, each ML team needs its “own” DataOps people. Data labeling managers and data curators focus on the problems faced by their specific ML unit, with little interaction with data people from other ML teams of the company. With this structure, data curators report directly to the head of their respective ML unit.
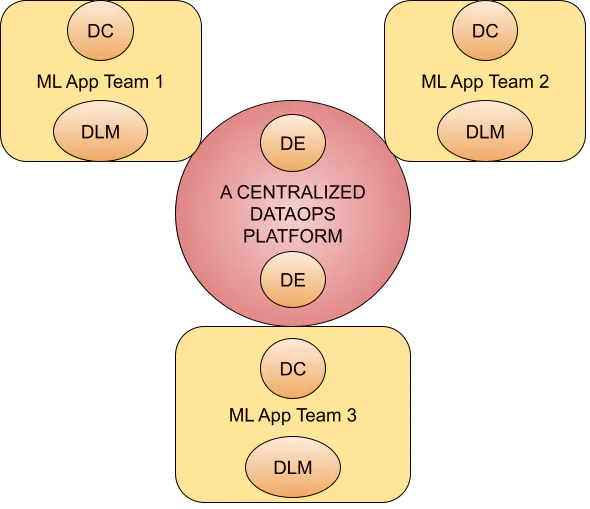
Pros
- Embedded teams of DataOps people are agile and responsive because they are dedicated to their respective ML functions and have good domain knowledge.
- ML teams don’t have to fight for resources to build their ML project because the resources sit in the teams.
Cons
- DataOps people end up working on redundant issues due to a lack of communication between different ML teams.
- The silos lead to productivity erosion since DataOps people can’t draw on their colleagues’ expertise as they do in the centralized model.
- This model makes it harder to staff DataOps people on different ML projects optimally.
Conclusion
A strong DataOps team is a key pillar you need to build if your company is to develop and deploy computer vision in the real world. The extent to which your model will extract predictive power from data ultimately depends on the strength of this team and how symbiotic it is with the rest of your organization. There is no made-to-order advice for the composition and structure of your DataOps team. That’s why you need to understand your organization’s ML Data Management maturity level so that you can build a DataOps team suited to your ML objectives and aligned with your business goals.
At Superb AI, we write about all the processes involved when building computer vision products: from the modern machine learning stack, to data operations teams composition, to data labeling and curation. Our blog covers the technical and the less technical aspects of bridging the gap between computer vision in academia and industry.
We are building a training data management product for the modern ML stack in the data-centric AI development world. We have designed our product to be enterprise-ready, automated, and intuitive.
Want to check it out? Reach out to us, and we will show you a demo.
Related Posts

Insight
How to Restart an AI Project That Stalled for Lack of Data—with Just 10 Images

Hyun Kim
Co-Founder & CEO | 7 min read

Insight
Three Years of the Few-Shot Object Detection Challenge: Mapping the Global Vision AI Landscape
Hyun Kim
Co-Founder & CEO | 7 min read

Insight
⑪ Germany's Physical AI Moment: Siemens, BMW, and the Robot Unicorn Counteroffensive
Hyun Kim
Co-Founder & CEO | 15 min read

About Superb AI
Superb AI is an enterprise-level training data platform that is reinventing the way ML teams manage and deliver training data within organizations. Launched in 2018, the Superb AI Suite provides a unique blend of automation, collaboration and plug-and-play modularity, helping teams drastically reduce the time it takes to prepare high quality training datasets. If you want to experience the transformation, sign up for free today.