Last month, I attended two great summits organized by REWORK: The MLOps summit that discovers how to optimize the ML lifecycle & streamline ML pipeline for better production and the ML Fairness summit that discovers strategies to ensure ML models are accountable & fair to build secure & responsible AI. As a previous attendee of REWORK’s in-person summit, I have always enjoyed the unique mix of academia and industry, enabling attendees to meet with AI pioneers at the forefront of research and explore real-world case studies to discover the business value of AI.
In this long-form blog recap, I will dissect content from the talks that I found most useful from attending the summit. The post consists of 10 talks that range from automated data labeling and pipeline optimization, to model fairness and responsible AI at scale.
MLOps Stage
1 - ADVANCED MACHINE LEARNING METHODS FOR AUTOMATING IMAGE LABELING
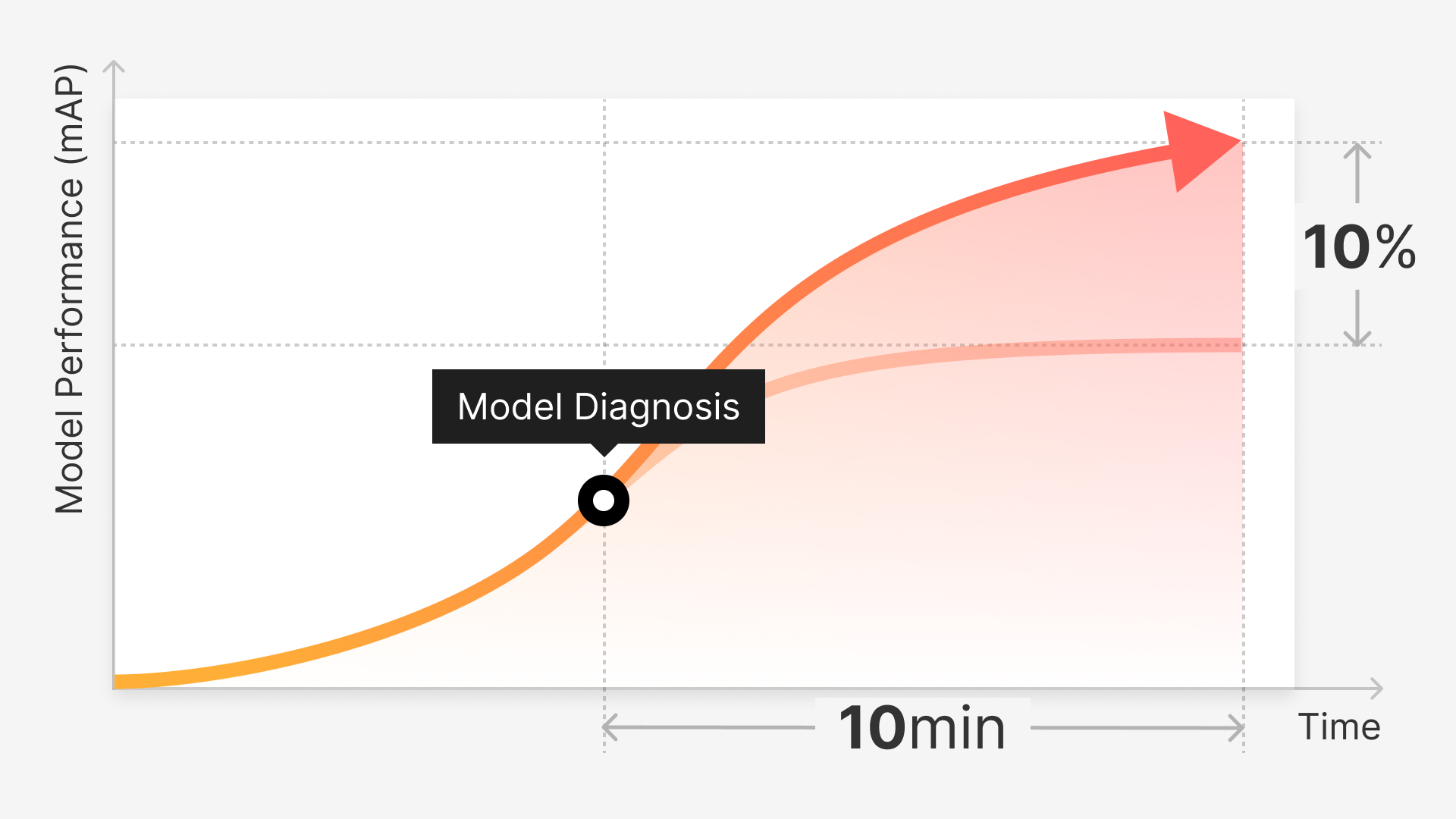
Training computer vision models require a constant feed of large and accurately labeled datasets. However, this typically requires large time and capital commitments, especially since humans manually do most labeling and quality assurance. Can most, if not all, of this workflow be automated intelligently? Hyun Kim, Superb AI's CEO (and my boss!), talked about how we use advanced ML techniques like transfer and few-shot learning to help teams automate the labeling and auditing of computer vision datasets.
A vision pipeline typically has three major stages:
Data Ingestion: Images and videos, extracted from various sources, are explored, validated, and loaded into a downstream system like Superb AI.
Data Labeling and Auditing: This stage is typically done through a team of project managers and labelers (internal), or outsourced.
Data Delivery: Audited datasets are packaged for delivery.
Based on conversations with 100+ data and ML engineers, data labeling and auditing is a major bottleneck within the data preparation pipeline for computer vision systems: "Teams spend up to 50-70% of their time with data preparation and management."
Interestingly enough, based on our surveys and interviews, this bottleneck applies to teams that just start a new computer vision project and more mature teams with models already in production.
Companies or teams in the early stages of ML development want to utilize AI in some ways, but they do not have any models pre-trained on niche or domain-specific datasets.
Mature teams with models in production are well-versed in the ML development and deployment lifecycle. They tend to have sophisticated pre-trained models and are focused on further improving model accuracy. They want to identify where the model is failing and manually prepare datasets to address those edge cases. They also want to address issues like data and model drift, where the accuracy of the trained model degrades over time as the characteristics of the data, upon which the model is trained on, change over time.
To get a better sense of how much it takes for ML teams to create a training set, let's do a quick back-of-envelope calculation here (from our experience):
A bounding box annotation typically takes a human labeler anywhere from 2-5 seconds.
For a 100,000-image dataset with 10 objects per image, it will take around 600-1,500 man-hours to label.
If you add the time to validate and audit the labels, you will spend considerably more time and money.

Hyun Kim - Advanced Machine Learning Methods for Automating Image Labeling (REWORK MLOps Summit 2021)
In addition, let's say you have a successful Proof-of-Concept project and now want to deploy models in production. As your project progresses, you'll have to constantly collect and label more data to improve the model performance. When you rely on brute-force manual labeling, the labeling cost increases linearly proportional to the number of labels created. What makes things even worse is that you will need exponentially more data and more money as your model performance improves. Unfortunately, your model performance plateaus as the number of labels increases. In other words, the marginal gain of your data diminishes as your model performance improves.
Despite all these challenges, there are two ways that you can leverage AI assistant to cut labeling cost and time:
You can embed AI into your labeling tool. For example, there are interactive tools that take as input a bounding box and then turn it into a polygon segmentation.
Another popular method is called model-assisted labeling. Teams who already have a pre-trained ML model can upload model predictions and use these as a starting point for their labels. After the model predictions are uploaded, the labeling team can review and modify the outputs if they find errors.
The model-assisted labeling approach is good for pre-labeling what your model is already efficient at. Most labeling platforms allow model predictions (soft labels) to be uploaded into an editing tool. But here's the catch: in order to improve model performance, you want to focus on collecting and labeling the edge cases where your model actually fails. By definition, model-assisted labeling won't work well for labeling these edge cases. Also, if you want to try pre-trained models on these cases, you will end up spending more time fixing the pre-labels than just labeling them from scratch.
Let's take a look at challenges in data labeling for real-life applications:
The images and videos that computer vision models see can be very dense. For example, images can have a lot of objects, making manual labeling very expensive.
Images in real life have various viewpoints and lighting. If you take a model pre-trained on clean open-source datasets and try to automate labeling, the model is likely to not perform well under these conditions.
In order for the model to detect rare events, you want to collect unlabeled data in these rare events. Labeling these rare events with a pre-trained model is almost impossible when you don't have enough of these rare events to begin with. This is a catch-22 situation.

Hyun Kim - Advanced Machine Learning Methods for Automating Image Labeling (REWORK MLOps Summit 2021)
Our key hypothesis at Superb AI is that data labeling should still be automated! We are using advanced auto-labeling techniques to help industry practitioners automate their data preparation pipeline:
Transfer learning is the reuse of a pre-trained model on a new problem. Essentially, a machine utilizes the knowledge gained from a previous task to improve generalization about another. Within the Suite platform that Superb AI provides for our clients, we have a very large pre-trained model that can be repurposed by training it on the data that users provide. This significantly reduces the amount of data and the time it takes to obtain a trained model that can be used to automate your data labeling pipeline.
Few-shot learning refers to the practice of feeding a learning model with a very small amount of training data. Instead of labeling hundreds to thousands of images, you can instead label just a few images and use our platform to create a custom-made model tailored to your dataset and be immediately used for data labeling.
Automated ML is the process of automating the process of applying ML to real-world problems. Instead of having your ML engineers spending hours training models, our platform can accomplish that without any human intervention/custom engineering work. It only takes one click to train a fully customized model on your data.
Uncertainty estimation (based on the Bayesian deep learning technique) enables a model to output predictions and confidence (how sure or unsure the model is with its own predictions). This helps you quickly narrow down the images that need to be reviewed (those with high uncertainty / low confidence).
Combining all 4 techniques, here's how your workflow might look like:
Re-train models that we have (transfer learning)
Using a very small number of your data (few-shot learning)
Without any custom engineering work (auto ML)
To audit model predictions faster (uncertainty estimation)
The end result is a customized model for further data labeling in just a few clicks and 1 hour later.

Hyun Kim - Advanced Machine Learning Methods for Automating Image Labeling (REWORK MLOps Summit 2021)
We believe that the ML-first approach to labeling should look like the diagram above:
You first ingest all raw collected data into our platform and label just a few images.
Then you train our custom auto-label function in under an hour without any custom engineering work.
Once that's done, you can apply the trained model to the remainder of your dataset to instantly label them.
Our model will also tell you which images need to be manually audited along with the model predictions.
Once you finish auditing the small number of hard labels, you are ready to deliver the training data.
Then, the ML teams train a model and get back to you with a request for more data.
If your model is low-performing, you need a new set of data to augment your existing ground-truth dataset. Next, you run them to your pre-trained model and upload the model predictions into our platform. Then, we will help you find and re-label the failure cases. Finally, you can train our auto-label on these edge cases to drive performance up.
This cycle repeats over and over again. With each iteration, your model will cover more and more edge cases.
Note: At Superb AI, we are going beyond labeling and building a DataOps product that addresses challenges with preparing high-quality training datasets for enterprise-level computer vision systems. I wrote up about this vision over here.
2 - MAKING CODE AND HUMANS GPU-CAPABLE AT MAILCHIMP
What happens when you have many data scientists, a bunch of new and old projects, a big grab-bag of runtime environments, and you need to get all those humans and all that code access to GPUs? Emily Curtin (Senior ML Engineer at Mailchimp) discussed how her team dealt with these problems by (1) wrestling with connecting abstract containerized processes to very-not-abstract hardware, then (2) scaling that process across tons of humans and projects.
Emily claimed that MLOps is all about people. For instance, there are various tradeoffs that her team has to figure out the right balance points in terms of:
How to make the infrastructure friendly for developers vs. efficient for computers.
How to move fast, break things, and make flashy demos vs. do not deploy anything ever until a giant checklist is complete.
How to satisfy typical Data Scientist system needs vs. their system knowledge and experience.
Mailchimp's typical tech stack includes Python as the programming language; Pytorch, Hugging Face, and TensorFlow as deep learning libraries; Docker as containers; Google Cloud Platform as the cloud infrastructure; and Kubernetes (either directly or indirectly) as the orchestrator. This stack enables good scalability and reproducibility. The cloud infrastructure, in particular, is good for spiky ML workloads (vs. more consistent, predictable web service). However, it was not easy for them to connect the Docker containers with the GPU devices.
At the base definition level, GPUs are optional hardware peripherals that require special drivers and rely on system buses for I/O. Emily made the case that GPUs are just printers!
The diagram below is a prototypical call stack of how requests trickle down from a front-end service to a real GPU.
Client requests come into Mailchimp's service framework, which are then routed to a service library.
The service library has dependencies on an ML library (either PyTorch or TensorFlow).
Then the requests go down to the level of Docker files / Docker images. These Docker assets are part of a Kubernetes pod (one or many containers).
Next, the requests go down to Kubernetes CUDA Daemonset, which runs on individual nodes. Because they use cloud infrastructure, there will probably be proprietary hyper virtual machines as well.
Eventually, the requests reach a Kernel module in an operating system on an actual node somewhere. This node talks to an actual, real, not virtual GPU device.

Emily Curtin - Making Code and Humans GPU-Capable at Mailchimp (REWORK MLOps Summit 2021)
The technical trick for making code GPU-capable is matching CUDA. More specifically, you need to match the CUDA version supported by your ML library of choice, in your base Docker image, and available on your Kubernetes nodes, exposed through Daemonset. However, since MLOps is all about people and Mailchimp needed to balance their data scientists' systems needs and systems knowledge and experience, Mailchimp went the low tech round.
Emily's team built an internal project leveraging Cookiecutter, an open-source Python package for project templating. It templates different versions of a basic project repository depending on the use case (such as Python library, Dataflow job, etc.). There is a single base image for everything, which is now GPU capable! It has custom tooling for re-runs and updates to existing projects. It also has a custom Github Enterprise bot for finding projects that need updated Docker base image versions.
Emily emphasized that "repo templating is not cool. And it totally works." She ended the talk with these takeaways:
MLOps is a super technical role that's all about people.
Remember to match your CUDA versions all the way down the call stack.
Be uncool to do cool stuff.
3 - ML PERFORMANCE IN THE REAL WORLD: WHAT THEY DON’T TEACH YOU IN SCHOOL
To ensure that machine learning models are continually achieving business goals, companies must monitor their model performance constantly. Issues such as the degradation of model performance over time can be detected by spotting changes to model accuracy or data drift. Adam Wenchel, CEO of Arthur AI, covered the basics of model accuracy and data drift, the most common metrics used for each analysis, and how Arthur enables the continuous monitoring of these critical features for organizations with ML models in production.
Students are taught basic concepts to monitor model performance such as accuracy, sensitivity, specificity, precision, and F1 score in school. However, when you want to deploy models into the real world, these metrics are simply not enough.
Firstly, the real world is always evolving, and the data always changes. When you train your models on historical data, they will almost always degrade when tested on new data. Adam broke down this problem into three categories:
Slow problems entail long-developing shifts that might take years or decades to happen (macroeconomics, population, urban infrastructure, etc.). These affect model performance, but not suddenly.
Fast problems (like the COVID-19 pandemic) happen faster and have a bigger impact on your model performance.
Very fast problems happen when an upstream data provider changes the way data is encoded, thereby changing the whole data workflow.
Secondly, it is challenging to construct a feedback loop from the model performance in the first iteration to the training data in the second iteration. The timeline is often very lengthy, making it not viable in practice. As a result, we need to find ways to shorten this feedback loop.
Adam provided three concrete approaches to accomplish that: (1) setting constraints on the data; (2) calculating data drift with techniques like KL divergence, KS test, PSI; and (3) detecting anomalies that are indicative of system bugs. All three approaches apply to input and output monitoring.
Beyond these basic approaches, you can try out more complex techniques like multi-variate drift (to calculate data drift in the interactions among variables) and regional performance analysis (to understand different pockets of the data).
In domains like NLP and Computer Vision, these monitoring approaches become even more complicated, given the complexity of unstructured data.
Beyond monitoring, you need comprehensive observability if you are looking to deploy mission-critical ML systems in the real world. This includes capabilities such as explainability, bias monitoring, and operationalizing.
Note: Arthur AI just released the first computer vision monitoring solution for the enterprise. Be sure to read their blog post for the details!
4 - KEY IDEAS FOR OPTIMIZING ML TRAINING PIPELINE AND MODEL ACCURACY
When it comes to allowing optimal performance for Machine Learning models, taking a data-centric approach is key to success. Why is training data the most powerful driver you need to leverage? How to leverage training data into an integrated end-to-end ML platform? How to accelerate model training through efficient ML workflows? Edouard d'Archimbaud, CTO & co-founder at Kili Technology and a former Head of Data & AI Lab at BNP Paribas, shared some key learnings from the Facebook ML use case.
Here's a bit of context about Kili Technology:
It is a comprehensive enterprise-grade Training Data Platform to enable AI Project deployments at scale building and managing high-quality training datasets.
It empowers businesses for increased value creation with advanced capabilities from smart labeling through to collaboration, QA, and training data management.
It has a trusted and experienced team in Data Labeling and ML solutions.
It was founded in 2018, has 30 collaborators, and has deployed 7000+ projects to date.
AI is made up of three components: CPU, Code, and Data. Edouard argues that data is the current biggest bottleneck to enable optimal performance of ML systems. To illustrate this point, he brought up the example of Halo, Facebook's internal annotation platform that allows Facebook researchers to more easily and efficiently create high-quality training data.
Halo (short for Human-AI loop) is a configuration-based annotation UI framework that leverages SVG layering to stack various annotation components into a single platform that allows researchers to plug and play different pieces quickly. Researchers can streamline annotation tasks, visualize the results and accuracy metrics of annotations, and export the annotations to start training their models.

Edouard d'Archimbaud - Key ideas for Optimizing ML Training Pipeline and Model Accuracy (REWORK MLOps Summit 2021)
Models trained with Halo-labeled datasets have powered AI experiences across Facebook's family of products:
Transcription of audio from video: In one instance, researchers at Facebook used a standard video player and a single text box to transcribe all intelligible audio from a set of publicly available videos. The goal was to train and evaluate automatic speech recognition (ASR) models for live captioning and other downstream applications. The labeler watched the entire video to transcribe the parts where a person was speaking. With the help of Halo, the team created labeler jobs programmatically via Halo API, where each job contains video chunks generated by employing a voice activity detection (VAD) model. This production-ready tool was created in three days and decreased average labeling per video by 32 percent. As a result, the transcription process is a lot easier for labelers, as they can skip to snippets of the video where someone is speaking.
Detecting harmful text in images: One of the core teams using Halo focuses on Rosetta, a Facebook tool that detects and recognizes text in visual media, including images and video. The team annotated hundreds of thousands of images to generate millions of bounding boxes across texts from a dozen languages. The output of the corresponding trained model then served as a signal in a meta-classifier that proactively protects people from harmful content, such as posts that contain hate speech.
Auto-generating descriptions of images: Scalable annotations have also helped Facebook build automatic alt text(AAT) within the core Facebook app. The technology generates text descriptions of photos that help the visually impaired. With AAT, people can use screen readers to hear descriptions of content images. Facebook used Halo to post-process categories generated from their classification models. Creating this labeled data for AAT models helps make Facebook more accessible.
Edouard then shares his secret sauce to optimize ML training pipeline and model accuracy, which is ML Secret Sauce = Annotation Consistency + Data Iteration + Production Prediction Feedback:
Consistent data is better than big data: This means that the quality of the data is more important than the size of the data. Kili platform has built-in advanced quality control features and powerful review workflows, in which annotations can be checked and audited.
Iterating on data is better than iterating on models: It's necessary to collect data in diverse settings (different distributions) so that the ML models can be robust when evaluated on unseen environments. Kili uses a data flywheel that includes 4 phases: (1) The data is sourced and searched -> (2) The data is annotated -> (3) The data is fed to the model -> (4) The trained model is refined using active learning, a technique that samples new data inputs that are challenging for the model to make predictions on.
A small retrained model is better than a big static model: It is critical to monitor model predictions to ensure that the model performance does not drift too much. Kili is an API-first platform that seamlessly connects with your ML models and applications so that you can perform monitoring and retrain models as needed.
5 - CHALLENGES AND CONSIDERATIONS IN BUILDING AN MLOPS PLATFORM
ML is used across industries, and while a lot of emphases has been made on data preparation and building models, the actual model deployment is not as widely discussed. There are common challenges that companies across the industries face while deploying these models. Siddhath Kashiramka, Product Manager for the ML Deployment Platform at Capital One, discussed the challenges and capabilities needed to build an ML deployment platform that provides a seamless and impactful experience for all its stakeholders.
According to the now-famous 2014 VentureBeat report, 87% of the data science projects never make it to production. There are several reasons that make ML deployment hard:
The lack of necessary expertise in the organization.
The lack of availability of production-ready data.
The lack of leadership readiness/investment in ML capabilities.
The lack of end-to-end ownership of the ML deployment.
It is important to acknowledge that ML systems span across multiple teams and stakeholders:
Given a business problem, the data scientist builds a model - making decisions on the languages/frameworks/architectures, etc.
Then, the data scientist hands the model to the ML engineer for packaging and testing. The ML engineer might also do tasks such as feature and data engineering at some companies.
The ML engineer then hands the model to the software engineer for deployment and monitoring. The model will be used in upstream applications.
At certain organizations, the model compliance officer sits at the top, working with different stakeholders to ensure model governance.

Siddhath Kashiramka - Challenges and Considerations in Building An MLOps Platform (REWORK MLOps Summit 2021)
Given various hands-off steps in this process, no single team or person understands how the overall system works - resulting in lengthy and costly time to production. For example:
The ML engineer realizes that model results are not reproducible and sends the model back to the data scientist for further iteration.
The software engineer realizes that the model does not meet platform SLAs and sends the model back to the ML engineer for further optimization.
The model compliance officer realizes that edge case value is not presented in the validation set, or more information is needed on the platform incident response plan. As a result, the model stays in the experimental phase.
So how can you build an ML deployment platform, given the constraints mentioned above? Siddath presented a 3-step framework.
Step 1 is to define the capabilities needed in your organization. In particular, 6 capabilities are important for the majority of ML deployment platforms.
Real-time or batch processing: You want to factor in your data quality needs and system responsiveness/latency.
Model registry or inventory: You want to lay out the plan for the legacy versions of the model.
Governance and risk management: You want to persist detailed model metadata, document data lineage, and establish controls/versioning on files and models.
Concurrent model execution: You want to scope the demand and volume of models used and scale them to growing needs to keep the execution latency to a minimum.
Model monitoring: You want to monitor operational and model performance metrics.
Cyber compliance: You want to evaluate a systematic review of security weaknesses.
Step 2 is to align on architecture that helps achieve the business capabilities needed in your organization. Specifically for an ML system, the architecture should be backed by these engineering best practices: reproducibility, scalability, automation, discoverability, extensibility, and simplicity.
Step 3 is to use tools and deployment strategies to meet your ML goals:
Containerization helps with fast deployment and provides greater manageability.
Dark launch tests your models in production to ensure that they behave as expected.
Canary deployment rollouts models to a subset of users.
Ultimately, MLOps is as much an organizational challenge as a technical one.
ML Fairness Stage
6 - ML FAIRNESS 2.0 - INTERSECTIONAL GROUP FAIRNESS
As more companies adopt AI, more people question AI's impact on society, especially on algorithmic fairness. However, most metrics that measure the fairness of AI algorithms today don’t capture the critical nuance of intersectionality. Instead, they hold a binary view of fairness, e.g., protected vs. unprotected groups. Lea Genuit, Data Scientist at Fiddler AI, discussed the latest research on intersectional group fairness using worst-case comparisons.
First of all, Lea made a case for fairness by stating that ML systems are often biased due to a variety of complex causes like pre-existing societal biases, unbalanced training data, etc. This now-famous 2016 Pro Publica article unpacked the machine bias issue in risk assessment for criminal sentencing.
Intersectional fairness is defined to be fairness along over-lapping dimensions, including race, gender, sexual orientation, age, disability, etc. Therefore, it’s important to measure intersectional fairness in order to get a complete picture of the bias that may exist in our AI systems. However, looking at fairness one dimension at a time doesn’t always tell us the whole story. For example, consider the graph below showing decisions made by an algorithm:

Lea Genuit - ML Fairness 2.0 - Intersectional Group Fairness (REWORK ML Fairness Summit 2021)
This type of problem has been referred to as “fairness gerrymandering.” The dark blue circles represent people the algorithm passed, while the light blue circles denote the people it failed. The same number of women passed as men, and the same number of Black people passed as White people. This one-dimensional assessment hides the bias in the system: all Black women and White men failed while all Black men and White women passed. We need an intersectional measure of fairness in order to catch this kind of imbalance across subgroups.
Lea and her colleagues at Fiddler came up with the worst-case disparity framework, which is included in a workshop paper at AAAI 2021 called “Characterizing Intersectional Group Fairness with Worst-Case Comparisons.”
Based on the Rawlsian principle of distributive justice, this framework aims to improve the treatment of the worst treated subgroup.
Its goal is simple: Find the largest difference in fairness between two subgroups (the “worst-case disparity”) and then minimize this difference.
This framework first selects a fairness metric f_metric, then computes the fairness metric for each subgroup in the data, f_metric(group_i), and finally finds the min/max ratio. To ensure intersectional fairness, its goal is for this ratio to be close to 1.
Recently, Fiddler introduces the Model Performance Management framework, a centralized control system at the heart of the ML workflow that tracks and watches the model performance at all the stages and closes the ML feedback loop. By adding fairness to this MPM framework, you will continuously and cautiously measure model bias in each step - from the training and validation phases in the offline environment to the monitoring and analysis phases in the online environment.

Lea Genuit - ML Fairness 2.0 - Intersectional Group Fairness (REWORK ML Fairness Summit 2021)
In the last part of the talk, Lea previewed Fiddler's new methodology to assess ML fairness called Bias Detector.
It provides a curated solution for 4 key group fairness metrics (disparate impact, demographic parity, equal opportunity, and group benefit) with effective coverage.
It uses intersectional fairness to measure fairness across protected classes.
It utilizes the worst-case disparity framework above to assess group fairness across protected classes.
It has a rich, intuitive managed experience to help users understand fairness implications from group metrics to data metrics and individual technical metrics.

Lea Genuit - ML Fairness 2.0 - Intersectional Group Fairness (REWORK ML Fairness Summit 2021)
Overall, here are the 4 key differentiators of Fiddler's Bias Detector:
Real-Time Fairness: Users can measure fairness on production data as well as on static datasets.
Integrated Into Monitoring: Users receive real-time fairness alerts and address the issue when they matter.
Built-In Explainability: Users can understand the impact of features on specific fairness metrics.
Risk Mitigation: Users can trackback to any past incident or analyze future predictions to minimize risk.
Note: Congrats to Fiddler on their recent $32M Series B round led by Insight Partners!
7 - ML OBSERVABILITY: A CRITICAL PIECE IN ENSURING RESPONSIBLE AI
Aparna Dhinakaran, Chief Product Officer of Arize AI, delivers an insightful talk covering the challenges organizations face in checking for model fairness, reviewing the approaches organizations can take to start addressing ML fairness head-on, and explaining how practical tools such as ML Observability can help build ML fairness checks into the ML workflow.
Various challenges exist with model fairness checks in practice:
There is a lack of access to protected attributes for modelers.
There is no easy or consistent way to check for model bias.
There is often a significant tradeoff between model fairness and business impact.
The responsibility is diffused across individuals, teams, and organizations.
So what are the common causes of bias in ML systems? Here are the major ones:
Skewed Sample: The police department tends to dispatch more officers to the place that was found to have a higher crime rate initially and is thus more likely to record crimes in such regions.
Tainted Examples: If a system uses hiring decisions made by a manager as labels to select applicants rather than the capability of a job applicant, the system trained using these samples will replicate any bias from the manager's decisions.
Proxies: Even if a sensitive attribute (e.g., race/gender) is not used for training an ML system, there can be other features that are proxies of that sensitive attribute (e.g., zip code).
Sample Size Disparity: If the training data coming from the minority group is much less than those coming from the majority group, it is less likely to model perfectly the minority group.
Limited Features: Features may be less informative or reliably collected for a minority group(s).
Before getting into measuring fairness, let's take a look at the concepts of protected attributes. Based on Mehrabi et al., 2019, the most common ones include sex, age, race, pregnancy, color, disability status, religion, citizenship, national origin, veteran/familial status, and genetic information. The same paper also provides the most common fairness definitions:
Fairness Through Unawareness: An algorithm is fair as long as any protected attributes are not explicitly used in the decision-making process.
Equal Opportunity: The equal opportunity definition states that the protected and unprotected groups should have equal true positive rates.
Predictive Rate Parity: Both protected and unprotected (female and male) groups should have an equal probability of being assigned to a positive outcome given a set of legitimate factors.
Demographic Parity: The likelihood of a positive outcome should be the same regardless of whether the person is in the protected group.
Equalized Odds: The protected and unprotected groups should have equal rates for true positives and false positives.
Counterfactual Fairness: A decision is fair towards an individual if it is the same in both the actual and counterfactual worlds where the individual belongs to a different demographic group.
Fairness Through Unawareness is probably the most commonly used definition in a business context. The issue is that model can learn from proxy information which hides the protected classes, so you still end up leaking in biases without being aware of them.
In large feature spaces, sensitive attributes are generally redundant given the other features. If a classifier trained on the original data uses the sensitive attribute and we remove the attribute, the classifier will then find a redundant encoding in terms of the other features. This results in an essentially equivalent classifier in the sense of implementing the same function.
What about small hand-curated feature spaces? In some studies, features are chosen carefully to be roughly statistically independent of each other. In such cases, the sensitive attribute may not have good redundant encodings. That does not mean that removing it is a good idea. Medication, for example, sometimes depends on race in legitimate ways if these correlate with underlying causal factors. Forcing medications to be uncorrelated with race in such cases can harm the individual.
Another popular way to frame fairness is by group or individual fairness.
In group fairness, groups defined by protected attributes receive similar treatments or outcomes. Group attributes are usually defined by law in practice, but it could be anything — “protected attributes.” Laws and regulations make it easier to measure group fairness. However, there is always a tradeoff between fairness and accuracy that we need to take into account.
In individual fairness, similar individuals receive similar treatments or outcomes. This makes intuitive sense but is difficult to put into practice. How to establish similarity between individuals differs by context and is difficult to measure. The credit score of two individuals matters more when evaluating mortgage applications but less so in evaluating MBA applications. It is impossible to set a standard definition of individual fairness that applies to all contexts.
Before any data scientist can work on the mitigation of biases, we need to define fairness in the context of our business problem by consulting the following Fairness Tree:

Aparna Dhinakaran — ML Observability: A Critical Piece in Ensuring Responsible AI (REWORK ML Fairness Summit 2021)
Aparna then proposed 3 strategic ways to address ML fairness in practice:
Organizational Investment: Create structure, awareness, and incentives for identifying ethical risks.
Define an Ethical Framework: Create a data and AI ethical risk framework tailored to your industry.
Establish Tools for Visibility: Optimize guidance and tools for model owners. Monitor impact and engage stakeholders.
From an organizational perspective, these are the questions to be answered:
Strategy: What's the top-down strategy? What are the P0 areas to check? How is success defined?
Resources: What existing infrastructure can teams leverage? What's needed for success at each step?
Teams: Which teams or functions will drive this effort? Do they have the expertise required?
Programs: How will the objectives be carried out? What incentives and training are needed to drive awareness and action?
Processes: How should teams and programs interact and engage? What steps are required to audit and resolve issues?
Tools: What software tools will best equip teams to carry out the work?
The diagram below shows where bias creeps into the machine learning process and where interventions could be made. The use of ‘creeps in’ is intentional. Most developers do not intentionally build bias into the models, so tackling bias with a fairness pipeline is a reasonable way to go:
During pre-processing, we tackle the biases present in data.
During in-processing, we train models to disregard sensitive attributes or penalize them when they're 'unfair.'
During post-processing, we modify an existing model's outputs.

Aparna Dhinakaran — ML Observability: A Critical Piece in Ensuring Responsible AI (REWORK ML Fairness Summit 2021)
Aparna's startup, Arize AI, focuses specifically on ML Observability, considered a critical piece in Responsible AI. You can't improve what you don't measure; so an ideal ML observability platform should have these functions:
Model validation before the model is deployed.
Dynamic analysis tools for troubleshooting.
Post-deployment monitoring (e.g., drift, performance, data quality).
Explainability capabilities for model decisions.
Note: Aparna is currently writing an AI Ethics series for Forbes. Her latest Q&A with Manish Raghavan on minimizing and mitigating algorithmic harm is a nice read.
8 - RESPONSIBLE AI @ TWITTER
At Twitter, Responsible AI is a company-wide initiative and concern called Responsible ML. Leading this work is the ML Ethics, Transparency, and Accountability (META) team: a dedicated group of engineers, researchers, and data scientists collaborating across the company to assess downstream or current unintentional harms in the algorithms we use and to help Twitter prioritize which issues to tackle first. Ariadna Font Llitjós, Director of Engineering for Twitter's META, shared where they are today and where they are headed.
There are two major work streams for META's Responsible ML work:
Equitable algorithms take responsibility for algorithm decisions to ensure equity and fairness outcomes. Their standards of creating risk and impact assessments fall under this workstream.
Algorithmic choice seeks to enable user agency. This workstream includes explainability to ensure transparency about their decisions and how they arrive at them.

Ariadna Font Llitjós — Responsible AI @Twitter (REWORK ML Fairness Summit 2021)
The META Team composes of different roles and experiences. The researchers have ML, CS, Math, Physics, Statistics, Political Science, and HCI backgrounds. The engineers have ML, software, privacy, and security backgrounds. Data scientists and user researchers are also included.
The META team partners with various other Twitter functional departments such as Trust and Safety, Legal, Communications, Privacy and Security, Software Development Standards, Policy, and Health.
Here's a bit about the META team's history:
META was founded in the first half of 2019 as a strategic engineering investment.
By the second half of 2019, they started to engage in internal and external research collaborations with support from key academic partners.
In the first half of 2020, the team increased execution bandwidth and explored new research areas, given the recruitment of Rumman Chowdhury.
In the fall of 2020, they moved beyond analysis to intervention and invested heavily in automation.
The first half of 2021 is dedicated to setting the stage for the company-wide adoption of Responsible ML practices.
Looking forward to the second half of 2021, the META team seeks to advance adoption across product areas for high-impact standards.
The most interesting ongoing work that the META team is doing is a gender and racial bias analysis of their image cropping (saliency) algorithm.
To give some context, in September 2020, a Twitter user reported that Twitter automatically cropped the image of black faces to only show the white faces. Was the Twitter algorithm racist?
Twitter started using its saliency algorithm in January 2018 to crop images. The purpose is to improve the consistency in the size of photos and allow users to see more photos on their own Timeline. The basic idea is to use these predictions to center a crop around the most interesting region. A region having high saliency means that a person is likely to look at it when freely viewing the image. The initial results showed that there were no racial or gender biases.
Twitter quickly responded to this issue in a blog post in October 2020 by recognizing representation harm and committing to fixing it. Representational harm occurs when systems reinforce the subordination of some groups along the lines of identity; or when technology reinforces stereotypes or diminishes specific groups.
In March 2021, the META team beta tested uncropped images in the Twitter timeline and image preview. After getting initial user feedback, the team rollout the full product launch in May 2021. Additionally, they wrote a blog post sharing learnings and actions taken while releasing the code and full academic paper.
The main conclusion is: Not everything on Twitter is a good candidate for an algorithm. In this case, how to crop an image is a decision best made by people.
Overall, this work reflects the META team's blueprint for accountability (by answering to Twitter users), transparency (by sharing their audit), collaboration (by sharing their code), and change (by updating the product roadmap). In the future, the META team will be working on two other exciting projects: (1) a fairness assessment of Twitter's Home timeline recommendations across racial sub-groups; and (2) an analysis of content recommendations for different political ideologies across seven countries. Include the hashtag #AskTwitterMETA on your tweet if you want to follow along this journey.
Note: Twitter META is hiring! Apply to these engineering managers and staff engineer roles.
9 - BIASES IN GENERATIVE ART - A CAUSAL LOOK FROM THE LENS OF ART HISTORY
Generative art refers to art that in part or in whole has been created by an autonomous system (i.e., any non-human system that determines the features of an artwork). From chemical and mechanical processes to computer programs and AI, there are various ways to generate art. There are online marketplaces and auction houses such as OpenSea, WeeArt, Artblocks, Etsy, Christies, Sotheby, Le Grand Palais, etc. There are user-friendly tools such as Cartoonify, Aiportraits, DrawThis, etc. In general, the generative art industry is predicted to grow exponentially. A recent research showed that there would be an increase in the number of generative art buyers that care about diversity in the next decade.
With rapid progress in AI, the popularity of generative art has grown substantially. From creating paintings to generating novel art styles, AI-based generative art has showcased a variety of applications. However, there has been little focus concerning the ethical impacts of AI-based generative art. Biases in training data and algorithms could result in discrimination based on sensitive attributes. Additionally, algorithms could stereotype artists and not reflect their true cognitive abilities (Zhu et al., 2017).
Ramya Srinivasan, AI Researcher at Fujitsu Laboratories, investigated biases in the generative art AI pipeline right from those that can originate due to improper problem formulation to those related to algorithm design. Biases in generative art can have long-standing adverse socio-cultural impacts. Historical events and people may be depicted in a manner contrary to original times. Owing to automation bias, this could contribute to bias in understanding history and even hinder the preservation of cultural heritage.
Ramya quickly walked through some background terminology about generative art:
Art movement refers to tendencies or styles in art with a specific common philosophy influenced by various factors such as culture, geography, political-dynastical markers, etc., and followed by a group of artists during a specific period of time.
Genre is based on the theme and depicted objects (landscapes, portraits, etc.).
Art material is the substance used to create artwork (charcoal, paint, etc.).
Artist style is characterized by cultural backgrounds, art lineage/schools, and other subjective aspects (such as the artists' cognitive skills, beliefs, and prejudices).

Ramya Srinivasan - Biases in Generative Art — A Causal Look from the Lens of Art History (REWORK ML Fairness Summit 2021)
Ranya then went through a method to visualize biases in generative art by leveraging directed acyclic graphs (DAGs). DAGs are visual graphs for encoding causal assumptions between variables of interest, where a node is a variable of interest, and directed edges denote causal relations. DAGs serve as a tool to test for various biases under such assumptions and facilitate domain experts such as art historians to encode their assumptions and, hence, serve as accessible visualization and analysis tools. Based on different expert opinions, there can be multiple DAGs, and it is possible to analyze for bias across these scenarios.

Ramya Srinivasan — Biases in Generative Art — A Causal Look from the Lens of Art History (REWORK ML Fairness Summit 2021)
Ranya next illustrated 4 different biases through case studies, which are surveyed academic papers, online platforms, and tools that claim to generate established art movement style and/or artists' styles. In particular, art movements and artists considered in the analysis were determined by the experimental setups reported in SOTA models and platforms. These biases include problem formulation bias (design asymmetry, exaggerated drawings, imaginary cropping of figures and areas of unshared colors), selection bias (tools like Aiportrait was trained using mostly white Renaissance portraits), confounding bias (material, genre, and art movement are confounders in determining the influence of the artist on the artwork), and transportability bias (also known as style transfer bias where unobserved confounders influence the artists).

Ramya Srinivasan — Biases in Generative Art — A Causal Look from the Lens of Art History (REWORK ML Fairness Summit 2021)
Ranya concluded the talk by outlining a few pointers that would be useful to consider while designing generative art AI pipelines:
There is a need to analyze the socio-cultural impacts of a generative art tool before its deployment.
There is a need to question if an algorithm can even solve a given problem (for example, can an artist's type be modeled?).
There is a need to define guidelines relating to the accountability of generative art.
It is crucial to involve domain experts in the generative art pipeline to better inform the art creation process.
Finally, it is beneficial to outline details of generative models to facilitate better communication between researchers and developers of such models.
That's the end of this long recap. If you enjoy this piece, be sure to read my previous coverage of REWORK's Deep Learning Virtual Summit back in January and REWORK’s AI Applications Virtual Summit in May. I would highly recommend checking out the list of events that REWORK will organize in 2021! Personally, I look forward to the Deep Learning Summit in September!
My team at Superb AI is developing an enterprise-level training data platform that is reinventing the way ML teams manage and deliver training data within organizations. If you are a practitioner/investor/operator excited about best data management practices to successfully build and manage MLOps and ML Fairness pipelines, please reach out to trade notes and tell me more! DM is open 🐦