Product
Solving Data Quality with ML Observability and Data Operations

2021/12/17 | 6 min read

Ensuring high quality for structured data (with ML observability) and unstructured data (with Data Operations)
_This is a joint piece written in partnership between Superb AI and Arize AI_
1 - Introduction
As the practice of machine learning (ML) becomes more similar to that of other software engineering disciplines, it requires processes and tooling to ensure seamless workflows and reliable outputs. In particular, data quality has been a consistent focus, as poor data quality management leads to technical, architectural, and organizational bottlenecks.
Since ML deals with both code and data, modern MLOps solutions need to take care of both by incorporating tasks such as version control of code used for data transformations and model development, automated testing of ingested data and model code, deployment of the model in production in a stable and scalable environment, and monitoring of the model performance and prediction outputs. As pointed out by the Great Expectations team, data testing and data documentation fit neatly into different stages of the MLOps pipeline: at the data ingestion stage, during the model development stage, and after the model deployment stage.
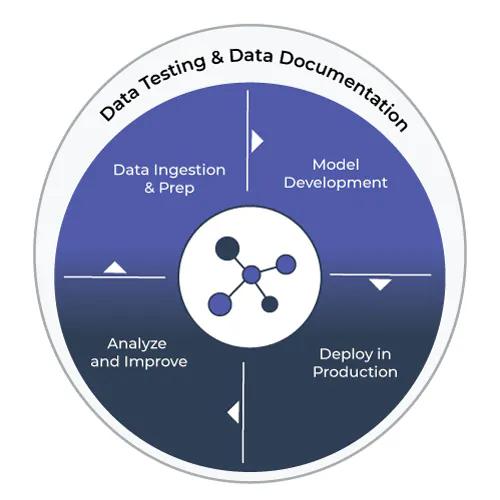
Image credit: Arize AI & Superb AI
It’s critical to recognize that data quality is a journey, not a destination. That is, data quality requires continued investment over time. For ML teams that are still in the nascent stage of dealing with data quality issues, the concept of a data quality flywheel can help kickstart their data quality journey by building trust in the data and improving the data quality in a self-reinforcing cycle.
In this blog post, we dive deep into the key dimensions of data quality and then explore the fundamental capabilities of robust data quality solutions both for structured and unstructured data. These ideas derive mainly from our experience collaborating with data and ML teams via our work at Arize AI and Superb AI.
2 - The Dimensions of Data Quality
Dimensions of data quality are the categories along which data quality can be grouped. These dimensions can then be instantiated as metrics of data quality that are specific and measurable. This excellent article from the Metaplane team drilled into the 10 data quality dimensions, broken down into intrinsic and extrinsic ones.
The intrinsic dimensions are independent of use cases, easier to implement, and closer to the causes.
1. Accuracy: Does the data accurately describe the real world? Do the entities exist and have the attributes you describe in your data model? Do events occur at the times and with the attributes you claim?
2. Completeness: How completely does the data describe the real world? There are at least two levels here. First, how complete is your data model? Second, how complete is the data itself within the data model you’ve constructed?
3. Consistency: Is the data internally consistent? If there are redundant data values, do they have the same value? Or, if values are aggregations of each other, are the values consistent with each other?
4. Privacy and Security: Is data being used in accordance with the intended level of privacy and secured against undesired access? This is especially important in our world of regular data breaches and if your company has compliance (e.g., SOC 2) or regulatory (e.g., HIPAA) requirements.
5. Up-To-Dateness: Does the data describe the real world right now? This dimension is closely related to the timeliness of the data, but is compared against the present moment rather than the time of a task.
The extrinsic dimensions are dependent on the use cases, requires cross-functional effort to implement, and are closer to the symptoms:
6. Relevance: Does the available data meet the needs of the task at hand? Do stakeholders require more data than is available to meet their use cases?
7. Reliability: Is the data regarded as trustworthy and credible by the stakeholders? Some factors that impact the reliability of data are: whether the data is verifiable, whether there is sufficient information about its lineage, whether there are guarantees about its quality, whether bias is minimized.
8. Timeliness: Is the data up-to-date and made available for the use cases for which it is intended? There are two components here: is the data up-to-date, and what is the delay to make the data available for the stakeholder?
9. Usability: Can data be accessed and understood in a low-friction manner? Some factors that impact usability are: whether the data is easy to interpret correctly and unambiguous.
10. Validity: Does the data conform to business rules or definitions?
Now that we have the list of intrinsic and extrinsic data quality dimensions, how can we build solutions that provide tangible metrics for each of these dimensions? Let’s review them both in the structured and unstructured context.
3 - Solving Structured Data Quality with ML Observability
While machine learning models rely on high-quality data, maintaining data quality in production can be challenging. The upstream data changes and the increasing pace of data proliferation as organizations scale can drastically change a model’s overall performance. Data quality checks in an ML observability platform identify hard failures within structured data pipelines through training and production that can negatively impact a model's end performance.
In short, data quality monitors enable teams to quickly catch when features, predictions, or actuals don't conform as expected. Teams can monitor for data quality to verify that feature data is not missing, catch when data deviates from a specified range or surpasses an accepted threshold, and detect extreme model inputs or outputs.
More specifically, data quality monitoring can be broken down into two main pipelines: categorical data and numerical data.
Categorical data monitors help ML teams easily identify:
1. Cardinality Shifts: A sudden shift in the distribution of categories
2. Data Type Mismatch: Invalid values associated with their respective categories
3. Missing Data: Missing streams of data
Numerical data monitors help ML teams easily identify:
1. Out of Range Violations: Out of bounds data values
2. Type Mismatch: Invalid data types
3. Missing Data: Missing streams of data
To keep an eye on model performance, ML teams can leverage an ML observability platform’s inference store to have a history of data to reference from training sets or from historical production data to set intelligent baselines and thresholds to balance the frequency of alerts and give power back to ML teams to ensure high-performing models in production.
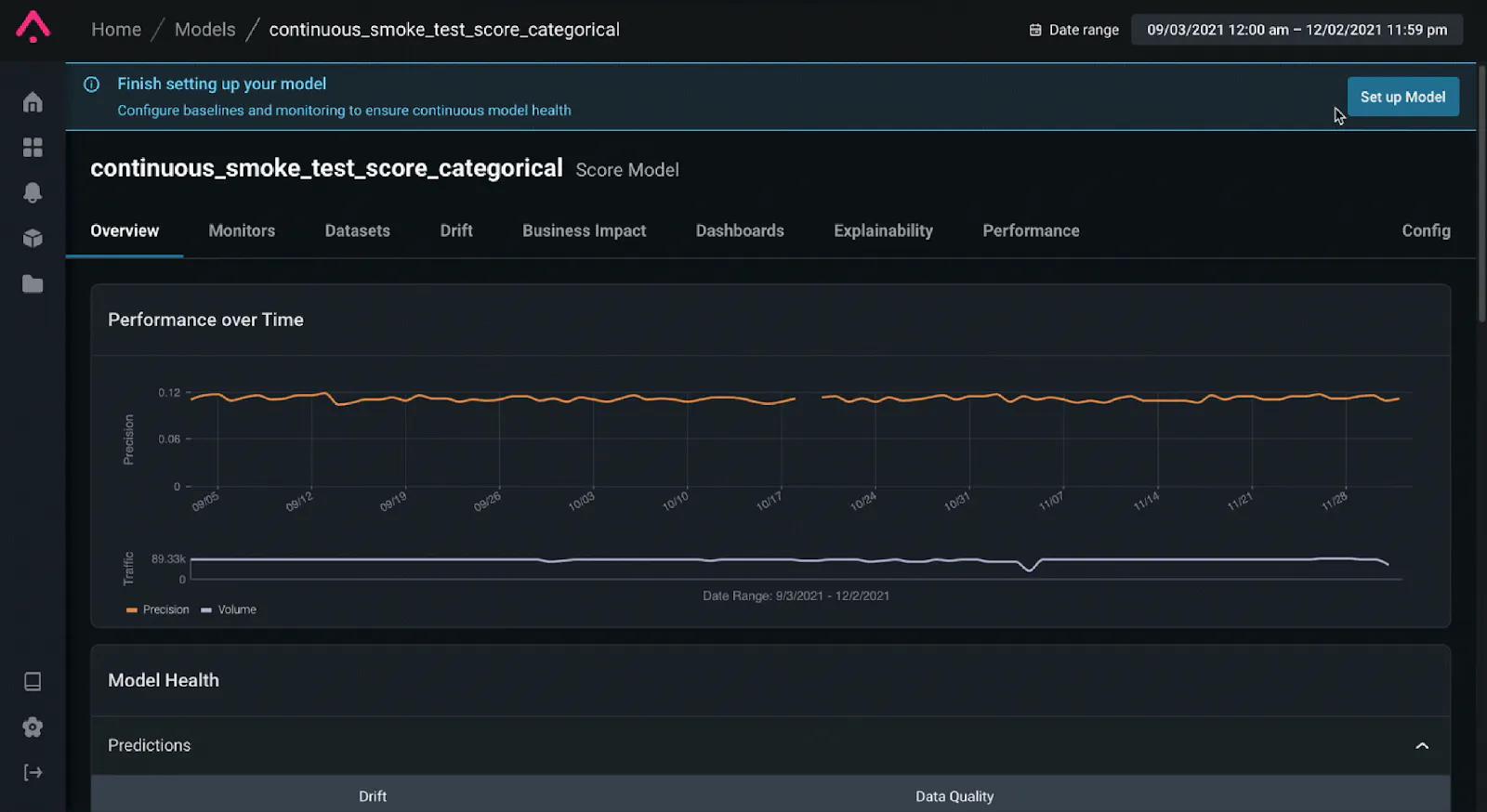
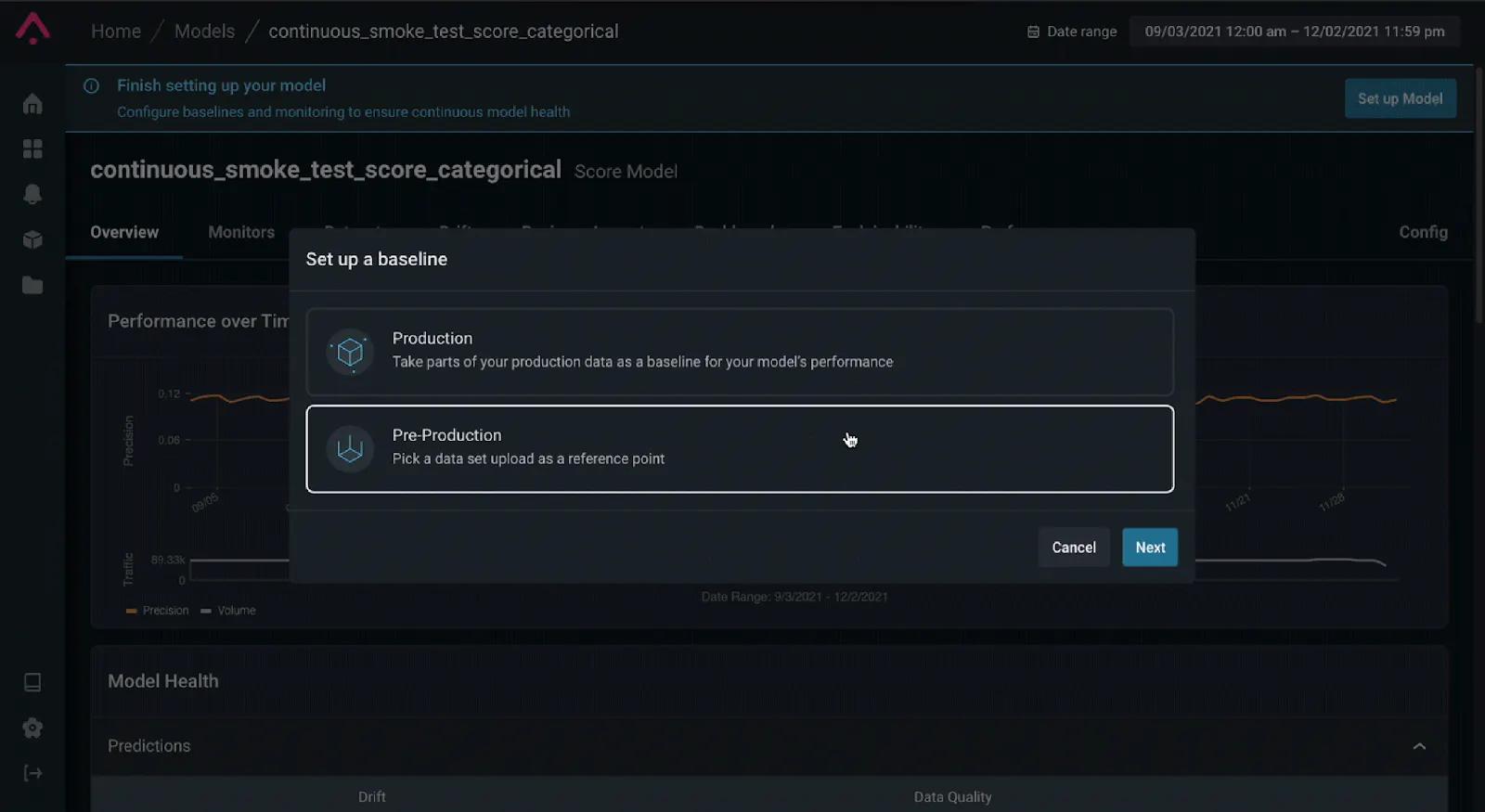
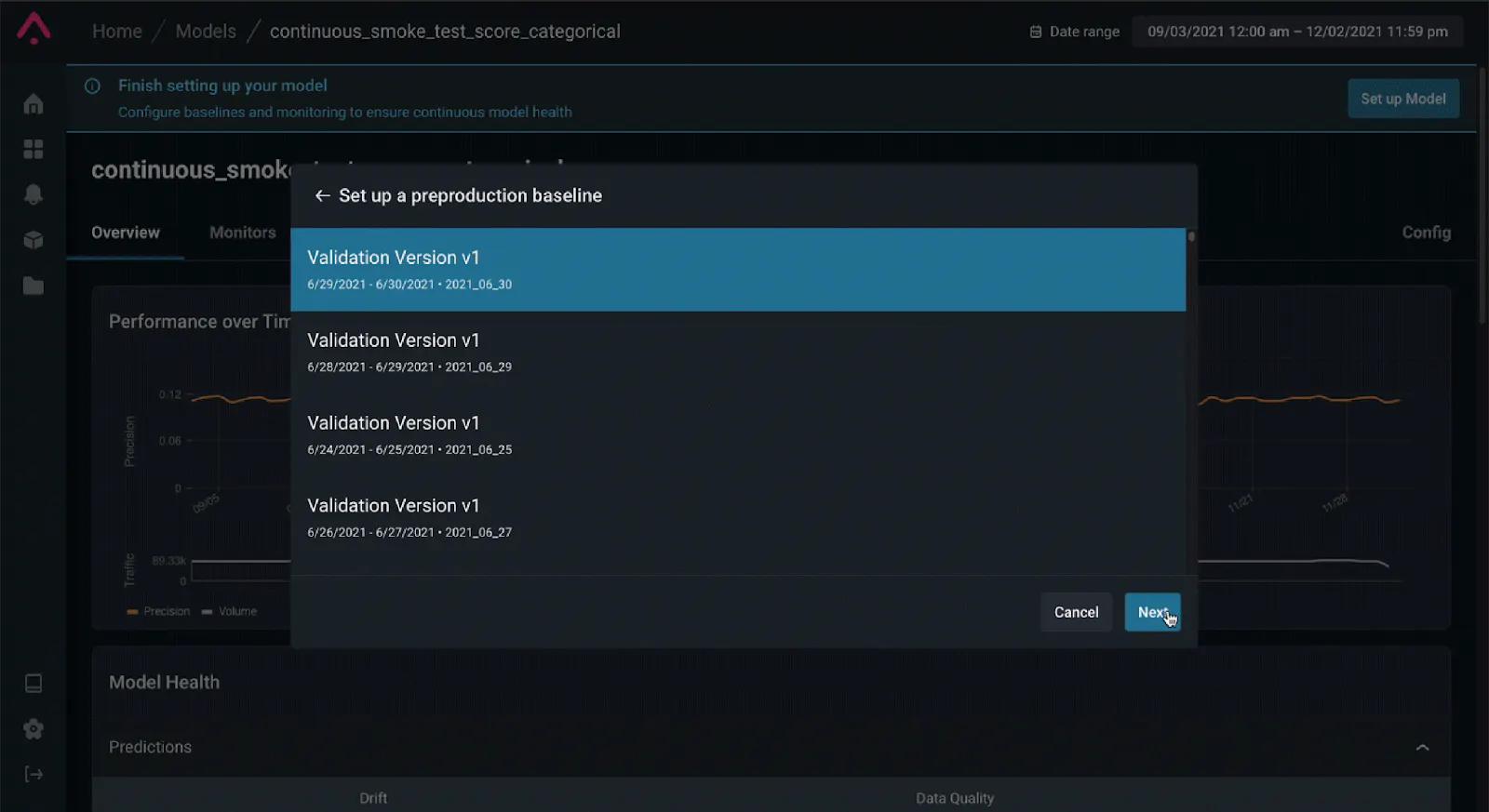
Image credit: Arize AI, setting up a baseline in an ML monitoring and observability platform
4 - Solving Unstructured Data Quality with Data Operations
In contrast to structured data, unstructured data such as text, speech, images, and videos do not come with a data model that enables a computer to use them directly. The rise of deep learning has helped us interpret the knowledge encoded in unstructured data using computer vision, language processing, and speech recognition methods. Therefore, unstructured data are used increasingly in decision-making processes. Although decisions are commonly based on unstructured data, data quality assessment methods for unstructured data are lacking.
All the dimensions presented in section 2 are relevant to structured and unstructured data. The three dimensions that we think are most relevant to dealing with unstructured data are Accuracy, Relevance, and Usability. If we think about processing unstructured data, the key elements include the input data, the real world, the data consumers, the task, and the knowledge extracted. Based on these elements, the quality of data D can be determined by comparing it to 3 classes of ideal data set: the data representing the real world D1 (Accuracy), the data optimized for the task D2 (Relevance), and the data expected by the current data consumers D3 (Usability).
1. Accuracy is hard to measure because the real-world dataset D1 is often unknown. Creating D1 requires human labeling - which can be costly, time-consuming, or impossible. The solution is to abstract away from details by using rules to check the general conformance of data points with expected patterns or build D1 manually for a part of the dataset. We can represent D1 by a standard ground-truth dataset with the accurate labels annotated manually by human experts.
2. Relevance can be assessed as the similarity between D and D2. Usually, D2 will be similar to D3 because the consumers want to use the data to accomplish the task. Consider a doctor searching for the size of a brain tumor using a machine. If he only finds information on the color of the tumor, the data quality is low.
3. Usability can be assessed as the degree of similarity between D and D3. For instance, consider an object detector used to detect cars on the road. If it was trained on a sunny day and is applied during a rainy night, D and D3 are not similar, and data quality is low. Since many different data consumers are often involved in interpreting unstructured data, this dimension is crucial for unstructured data.
Modern solutions to verify the quality of unstructured data should have these broad capabilities:
1. Profiling: Users can understand what a dataset is about in one view. The tool should enable summary statistics of key metadata about the dataset (size, count, source, recency, etc.)
2. Cleaning: Users can check for duplicates, remove outliers, fix structural errors, and check for missing values. If practical, the tool should help the users automatically and quickly accomplish these tasks.
3. Labeling: Users can create ground-truth labels with ease, distinguish between easy and hard labels, ensure label consistency, and audit the correctness of the labels. The tool should enable these tasks, which can be done manually with human-in-the-loop or automatically with automated labeling.
4. Intuitive UI: Users have access to built-in functions to streamline end-to-end data quality tests and monitoring. The tool, therefore, must have a user-friendly interface for both technical and non-technical users to interact with.
5. Advanced capabilities for specific use cases such as real-time ingestion, metadata management, governance, etc.
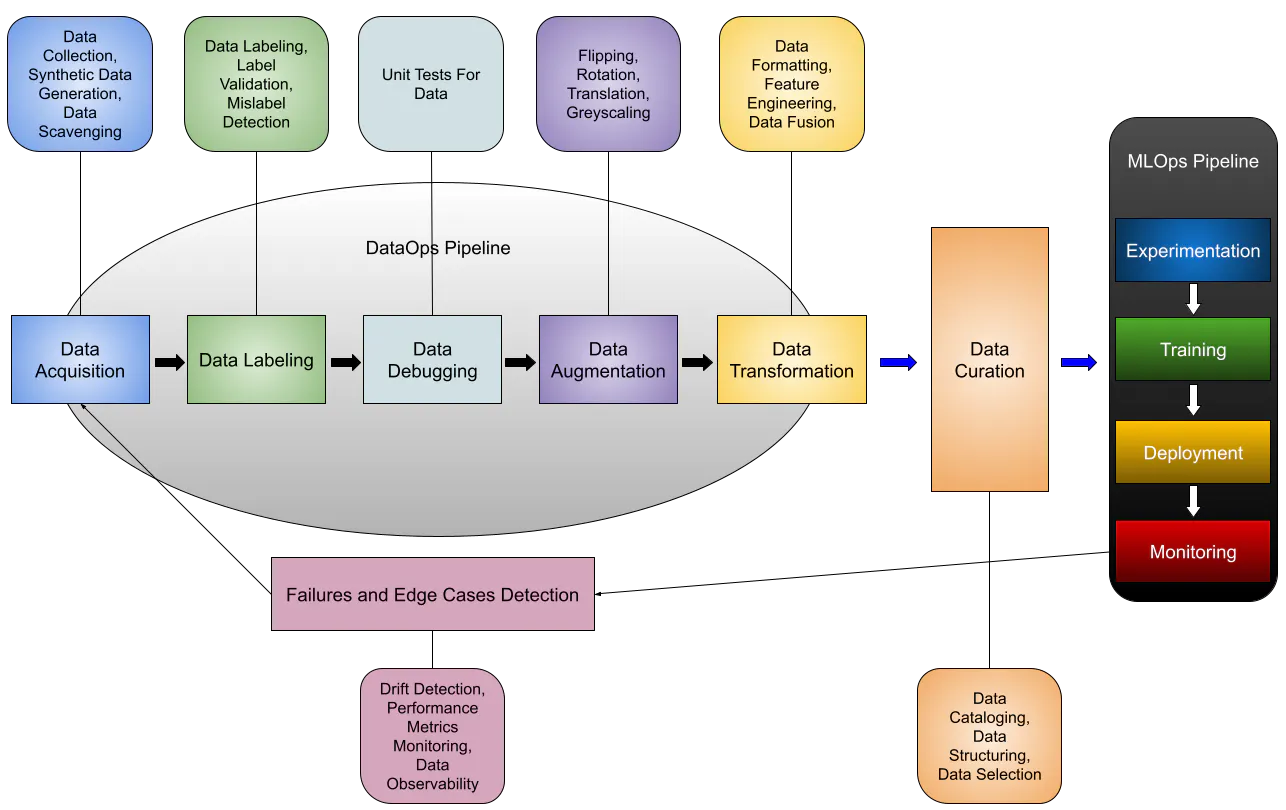
Image credit: Superb AI, the ideal DataOps pipeline for the Modern Computer Vision stack
All of these can be baked into a Data Operations platform, which helps bring rigor, reuse, and automation to the development of ML pipelines and applications. DataOps can transform the data quality management process from ad-hoc to automated, from slow to agile, and from painful to painless.
5 - Conclusion
In this post, we discussed the key dimensions of data quality and explored the broad capabilities of ML observability and Data Operations platforms as viable data quality solutions. Investing in data quality in your organization can pay dividends for years into the future with your ML initiatives.
Curious about how to ensure high quality to unlock the potential of your company’s structured and unstructured data? Request a trial of Arize AI’s ML Observability platform, or schedule a demo to examine Superb AI’s DataOps offerings today!
Related Posts

Product
How to Build & Deploy an Industrial Defect Detection Model for a Lucid Vision Labs Camera

Sam Mardirosian
Solutions Engineer | 15 min read

Product
How to Build & Deploy a Safety & Security Monitoring AI Model for an RTSP CCTV Camera
Sam Mardirosian
Solutions Engineer | 15 min read

Product
How to Use Generative AI to Properly and Effectively Augment Datasets for Better Model Performance

Tyler McKean
Head of Customer Success | 10 min read

About Superb AI
Superb AI is an enterprise-level training data platform that is reinventing the way ML teams manage and deliver training data within organizations. Launched in 2018, the Superb AI Suite provides a unique blend of automation, collaboration and plug-and-play modularity, helping teams drastically reduce the time it takes to prepare high quality training datasets. If you want to experience the transformation, sign up for free today.