
Suite와 Valohai로 YOLOv3 파이프라인 설계하기


지난 포스팅에서는 Superb AI Suite와 Valohai, 두 플랫폼이 서로를 어떻게 보완하고 있는지에 대해 다뤘는데요. 이번에는 두 플랫폼에서 사전 학습된 가중치와 전이학습(Transfer Learning)을 사용하여 컴퓨터 비전 모델을 학습시키는 파이프라인을 보여드리려고 합니다. 이번 모델에서는 실시간 객체 감지용으로 구축된 YOLOv3를 사용할 예정입니다.
이 실험에서 학습용 데이터의 관리 및 라벨링은 모두 Superb AI Suite에서 진행되었고, 라벨링이 완료된 데이터를 활용한 모델 학습 및 배치 추론 단계의 파이프라인은 Valohai 플랫폼에서 설계되었습니다.
- Superb AI Suite는 컴퓨터 비전 팀이 데이터 수집 및 라벨링부터 테이터 품질 평가 및 Export에 이르기까지, 전체 데이터 파이프라인을 자동화하고 관리할 수 있는 ML DataOps 플랫폼입니다.
- Valohai는 모든 클라우드 또는 온프레미스 하드웨어에서 완전히 자동화된 기계학습 파이프라인을 구축하고 운영할 수 있도록 지원하는 MLOps 플랫폼입니다. 컴퓨터 비전과 딥러닝 모델 개발을 지원합니다.
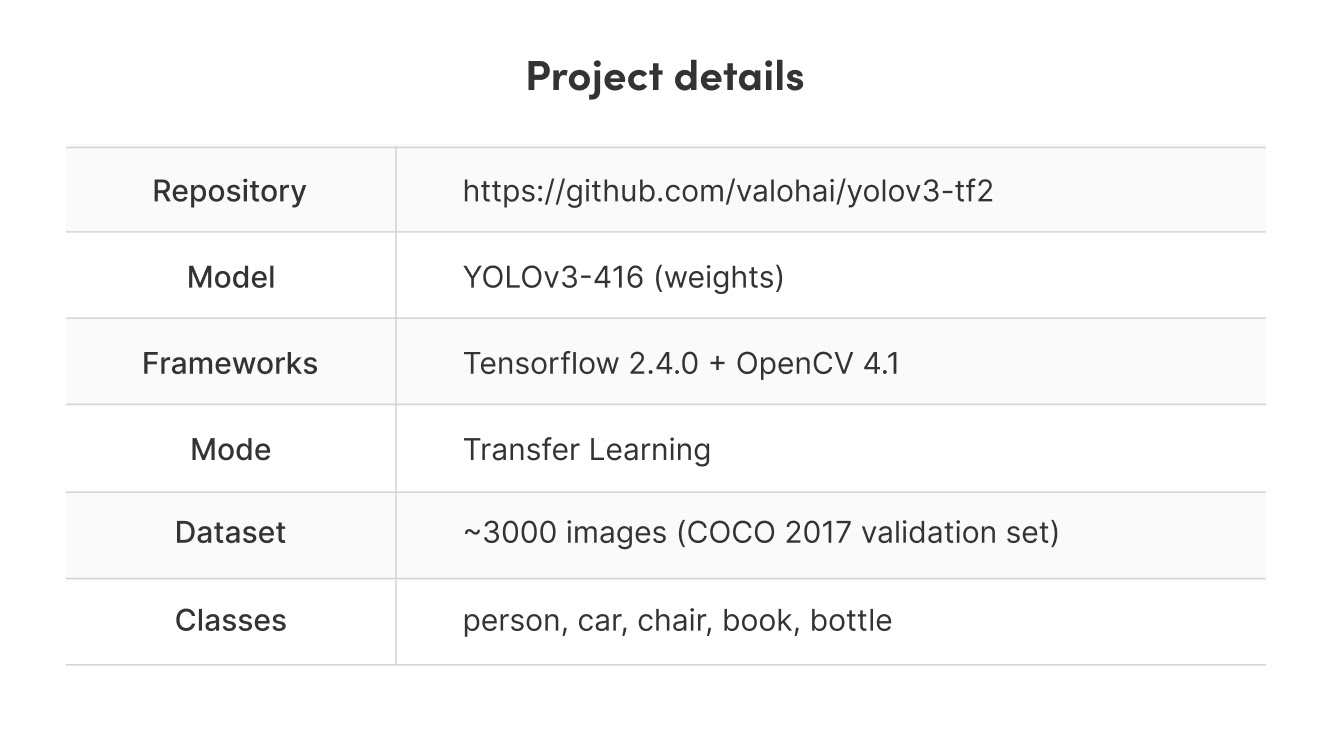
프로젝트 세부 사항
참고 : 이 파이프라인은 매우 기본적인 형태이기 때문에, YOLOv3 모델에 맞는 가중치를 사용하여 Superb AI 플랫폼의 데이터셋과 모든 종류의 클래스를 학습시키는 것은 매우 간단합니다. 이어지는 내용을 보면 이번 예시에 기본값만 사용했다는 것을 알 수 있을 것입니다.
1. Superb AI Suite에서 데이터 준비하기
먼저 Superb AI Suite에서 새로운 프로젝트를 만들어야 합니다. 프로젝트의 제목과 설명을 기입한 후, 어노테이션 유형을 선택하세요. 이번 프로젝트에서는 ‘바운딩 박스’를 사용합니다.
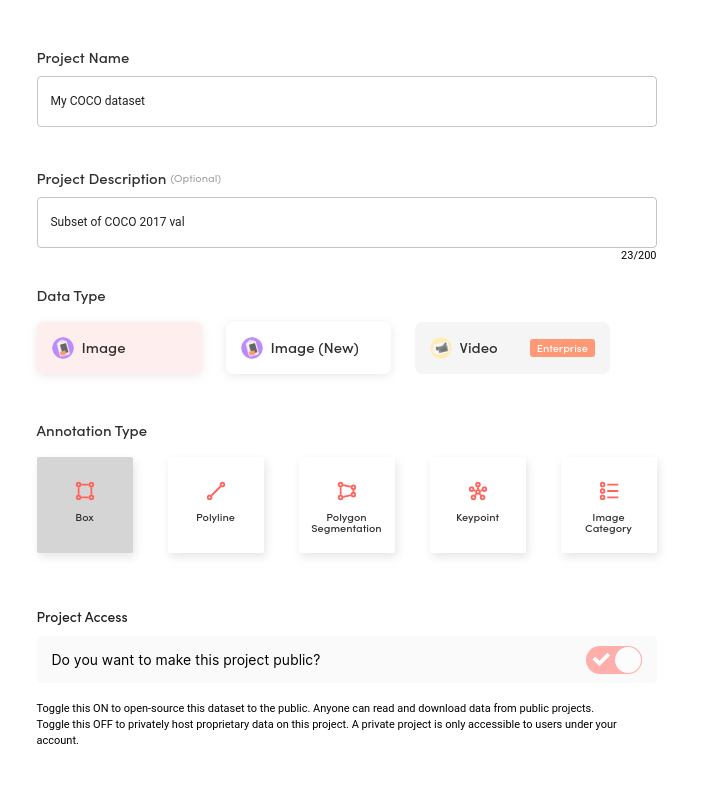
Suite - Create Project
그런 다음, 플랫폼에 업로드할 COCO 데이터셋에 맞춰 사람, 자동차, 의자, 책, 병 등 다섯 개의 클래스를 추가합니다.
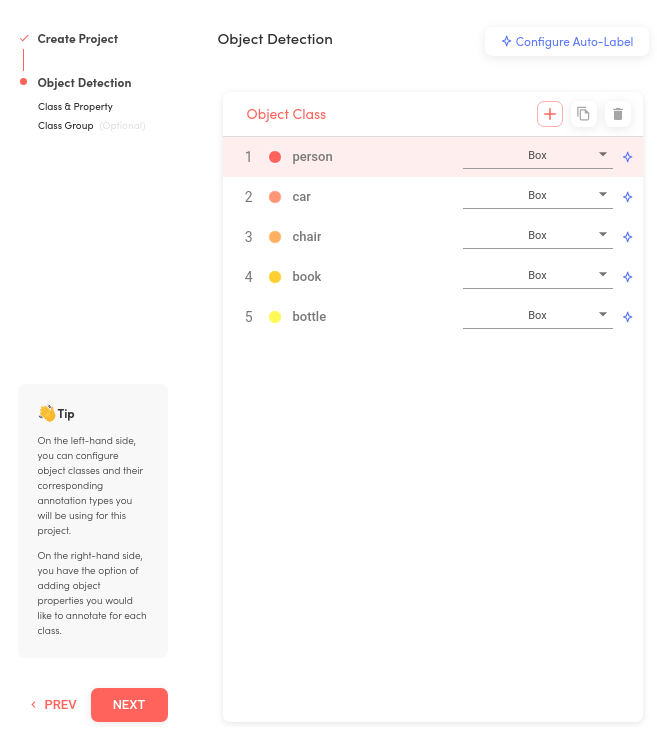
Suite - Object Detection
Superb AI의 오토라벨링 기능을 사용할 수 있지만, COCO 데이터셋에 라벨이 이미 포함되어 있어 사용하지 않아도 됩니다. Suite에서 프로젝트와 데이터셋 템플릿을 준비했으니, 이제 Superb AI SDK 및 CLI를 사용하여 실제 데이터와 라벨을 변환하고 업로드하면 됩니다. example repository의 안내를 따르세요.
변환 및 업로드가 완료되면 프로젝트에 3,000개가 넘는 이미지가 탑재되며, Valohai 플랫폼의 기계학습 파이프라인을 사용해 준비할 수 있습니다.
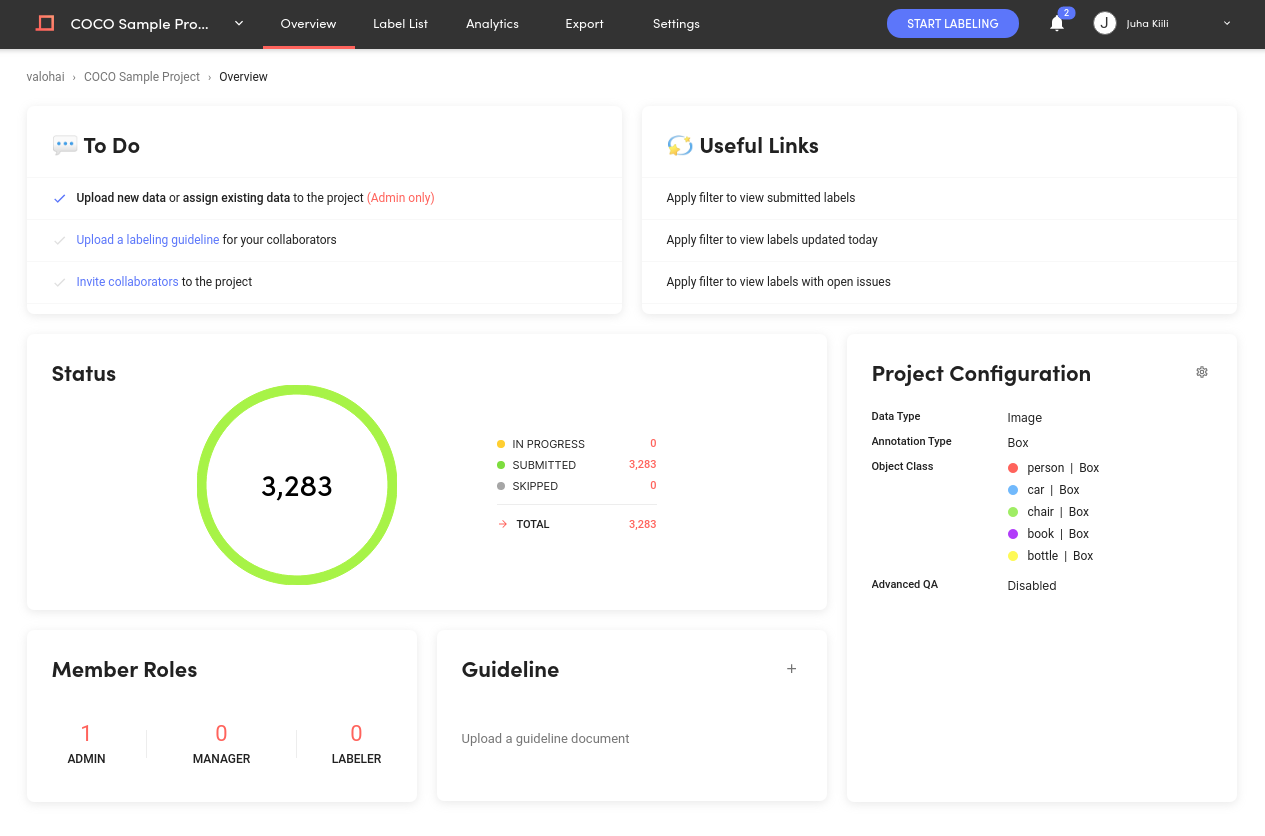
Suite - Project Overview
2. Valohai의 기계학습 파이프라인
Valohai의 기계학습 파이프라인은 프로젝트를 성공하게 하는 핵심 요소입니다. 우리의 이번 파이프라인은 4단계로 구성됩니다.
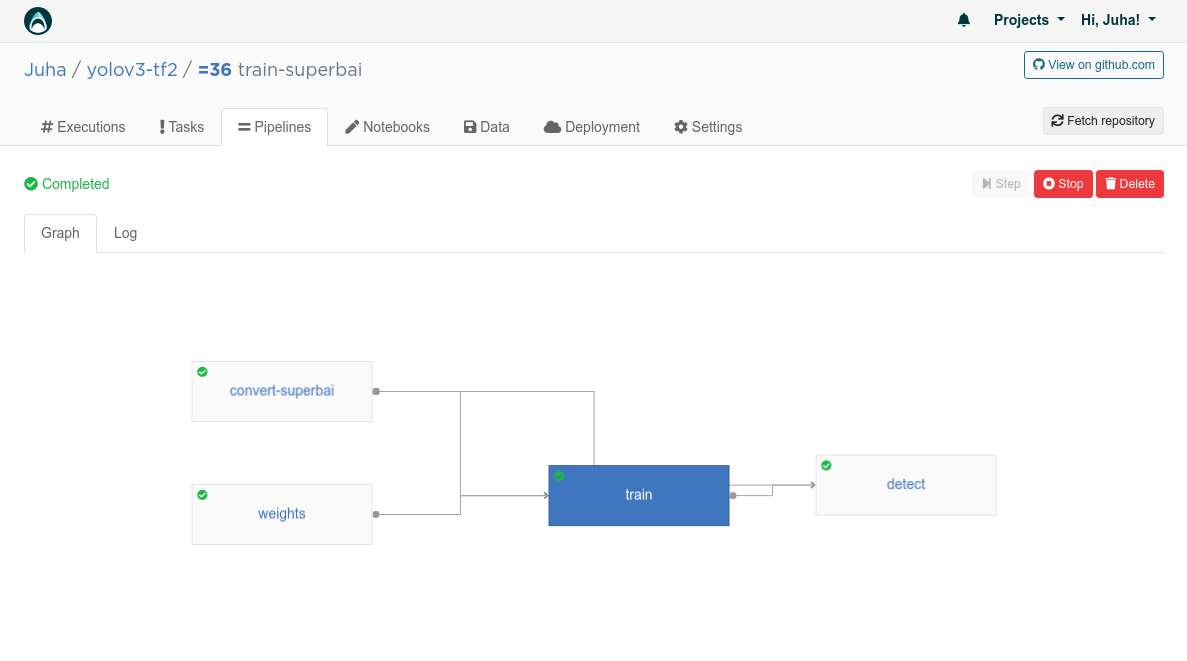
Valohai - Pipelines
convert-superbai 단계에서는 Suite에서 가져온 데이터를 Superb AI에서 제공하는 태깅 기능을 사용해 학습용 및 검수용 데이터셋으로 구분하고, 최종적으로 두 데이터셋을 .tfrecord 파일로 변환하여 모델에 입력할 수 있게끔 했습니다.
weights(가중치 설정) 단계에서는 Joseph Redmon의 웹사이트에서 사전 학습된 가중치를 다운로드하고, 이를 Tensorflow 체크포인트로 변환한 다음, 하나의 이미지에 대한 추론을 실행하여 올바르게 작동하는지 최종적으로 검증했습니다.
학습 단계에서는 하이퍼파라미터 값으로 모델을 GPU 환경에서 학습시킵니다(이 단계를 제외하면 모두 CPU 환경을 기본으로 합니다).
마지막으로, 검출(detect) 단계에서는 지난 단계에서 입력된 이미지 데이터셋으로 새롭게 학습시킨 모델에 대한 추론(inference)을 진행합니다. 이 과정을 끝내면 최종적으로 원본 이미지 위에 바운딩 박스와 라벨들이 렌더링된 새로운 버전의 이미지들이 결과물로 나오게 됩니다.
각 단계는 보통 하나의 파이썬 파일로 이뤄져 있습니다. 다음 내용은 weights 단계의 weights.py 소스 코드들입니다. 여기에는 파라미터 weights_num_classes(사전 학습된 모델에 사용된 클래스 수)와 인풋 가중치(실제 사전 학습된 가중치)가 하나씩 포함되어 있습니다.
import numpy as np
from yolov3_tf2.models import YoloV3
from yolov3_tf2.utils import load_darknet_weights
import tensorflow as tf
import valohai
params = {
"weights_num_classes": 80,
}
inputs = {
"weights": "https://pjreddie.com/media/files/yolov3.weights",
}
valohai.prepare(step="weights", default_parameters=params, default_inputs=inputs)
physical_devices = tf.config.experimental.list_physical_devices('GPU')
if len(physical_devices) > 0:
tf.config.experimental.set_memory_growth(physical_devices[0], True)
yolo = YoloV3(classes=valohai.parameters('weights_num_classes').value)
load_darknet_weights(yolo, valohai.inputs('weights').path(), False)
# Sanity check with random image
img = np.random.random((1, 320, 320, 3)).astype(np.float32)
output = yolo(img)
path = valohai.outputs('model').path('model.tf')
yolo.save_weights(path)
Valohai SDK에서는 valohai.prepare() 함수를 호출할 때 파라미터와 인풋이 전달됩니다. Valohai CLI는 이 호출을 분석해서 이 단계의 파라미터화에 필요한 구성을 자동으로 생성합니다.
이 파이프라인은 pipeline.py에 정의되어 있으며, 여기서도 새로운 SDK를 사용합니다.
import valohai
def main(old_config):
pipeline = valohai.Pipeline(name="train-superbai", config=old_config)
# Define nodes
convert = papi.execution("convert-superbai")
weights = papi.execution("weights")
train = papi.execution("train")
detect = papi.execution("detect")
# Configure pipeline
convert.output("classes.txt").to(train.input("classes"))
convert.output("train/*").to(train.input("train"))
convert.output("test/*").to(train.input("test"))
convert.output("classes.txt").to(detect.input("classes"))
weights.output("model/*").to(train.input("model"))
train.output("model/*").to(detect.input("model"))
return pipeline
3. Valohai에서 파이프라인 세팅하기
먼저 Valohai에서 새 프로젝트를 생성하고, 프로젝트 설정에서 GitHub에 업로드 된 example repository를 연결하세요.
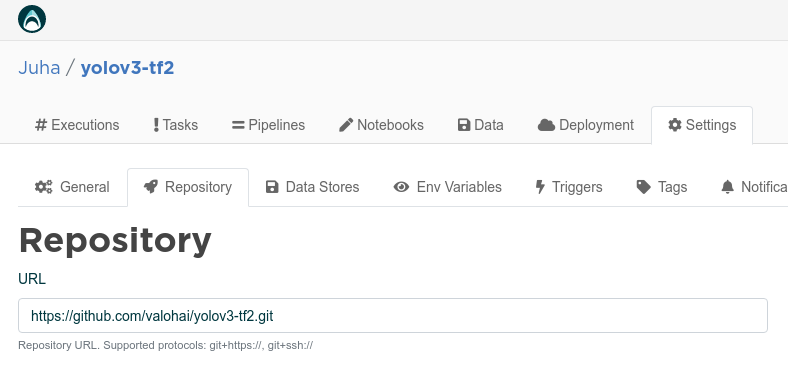
Valohai - Settings - Repository
이제 파이프라인 탭에서 새 파이프라인을 생성하고, 드롭다운 목록에서 train-superbai를 선택할 수 있습니다.
4. Superb AI Suite와 연동하기
파이프라인을 실행하기 전에, 데이터를 가져올 위치를 지정해야 합니다. 데이터 인풋으로 가져와야 하는 이미지와 라벨은 각각 개별 URL로 생성되어 있어 아래 그림과 같이 해당항목에 각 URL을 넣어주면 됩니다.
Images: Settings > General (Superb AI Suite)

Labels: Export > Export History (Superb AI Suite)

Pipeline Inputs (Valohai)
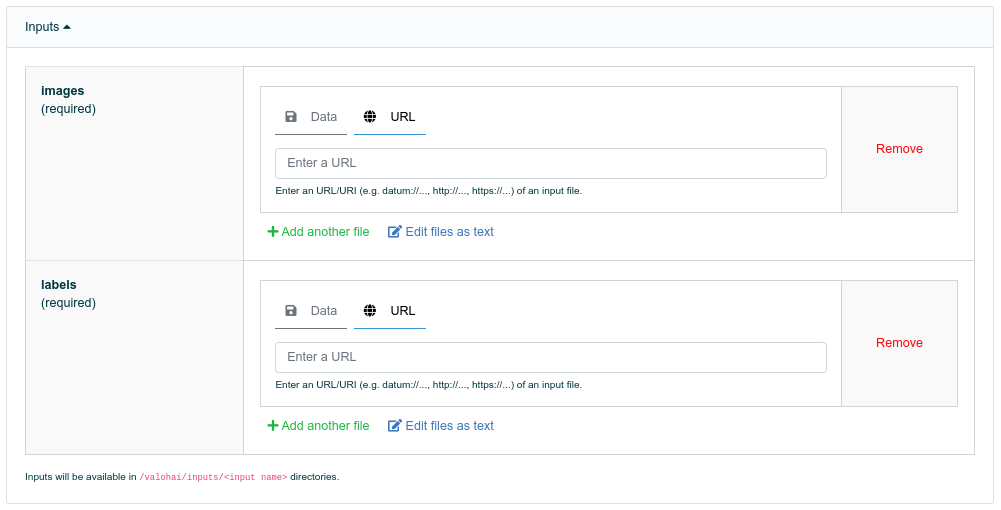
5. 파이프라인 실행하기
데이터셋을 Superb AI Suite와 연동했으므로, 파이프라인을 실행하는 일만 남았습니다.
Valohai는 파이프라인의 각 단계에 대한 모든 인풋, 파라미터, 로그 및 메트릭을 기록합니다. 다음은 인풋, 파라미터, 도커 이미지, 환경, 그리고 파이프라인 각 단계의 실행을 위한 기타 정보입니다.
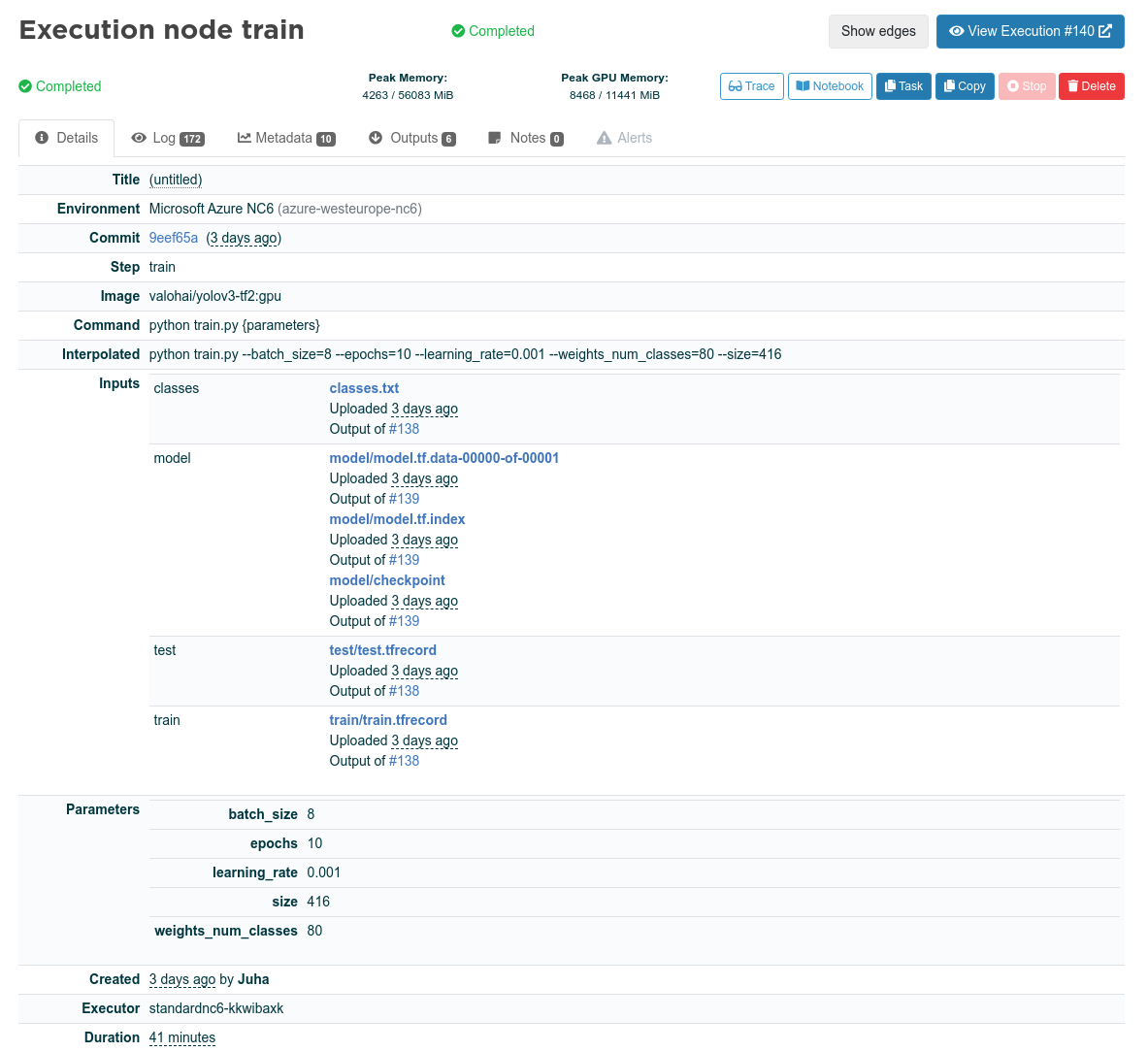
Valohai - Execution node train - details
다음은 학습용 코드로 출력한 전체 로그 중 일부입니다.
Valohai - Execution node train - Log
학습용 코드에서 출력한 메트릭입니다. Valohai는 출력된 모든 JSON을 메트릭(Valohai에서는 ‘메타데이터’라고 함)으로 분석합니다.
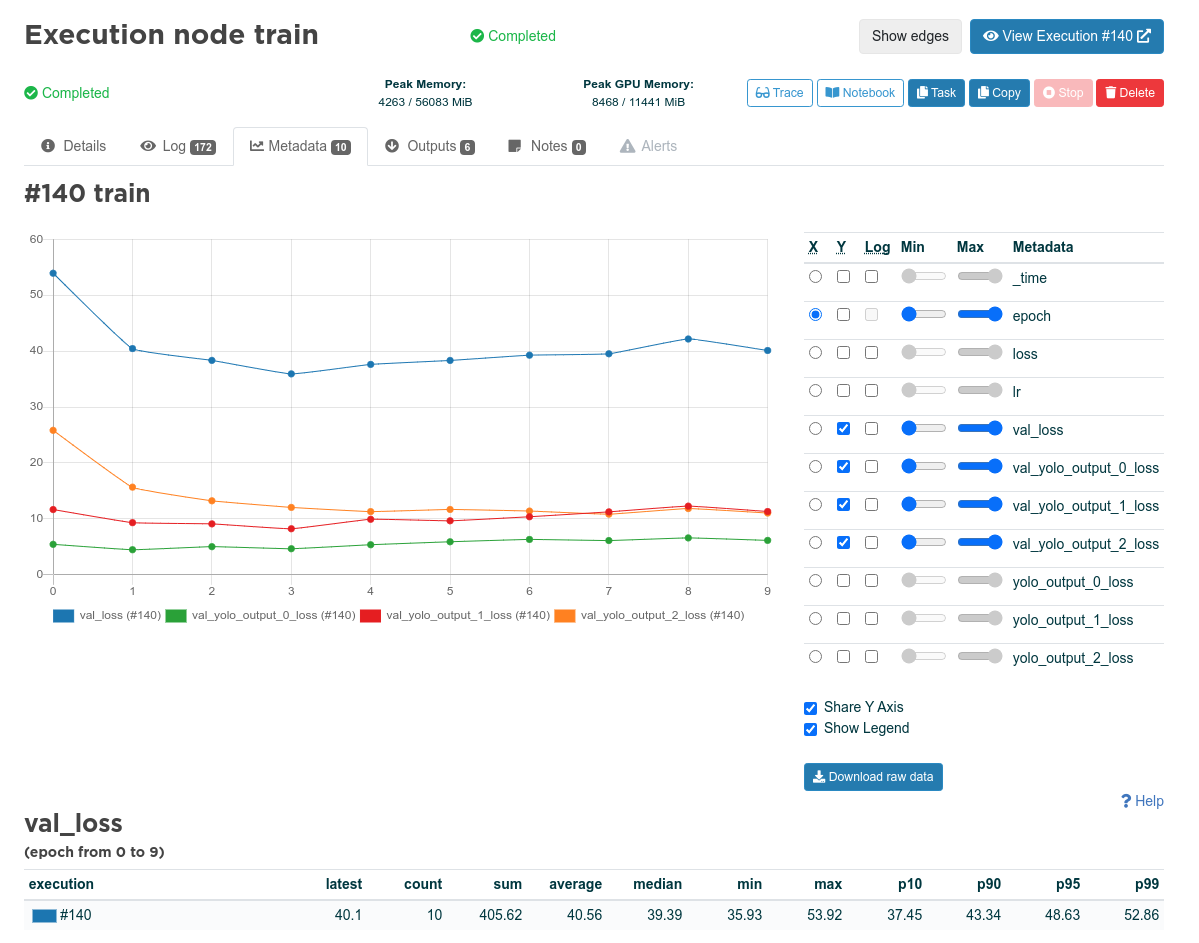
Valohai - Execution node train - Metadata
마지막으로, 검출(detect)단계의 Output 탭에서는 모델이 실제로 어떻게 작동하고 있는지 이미지를 보며 검사할 수 있습니다.
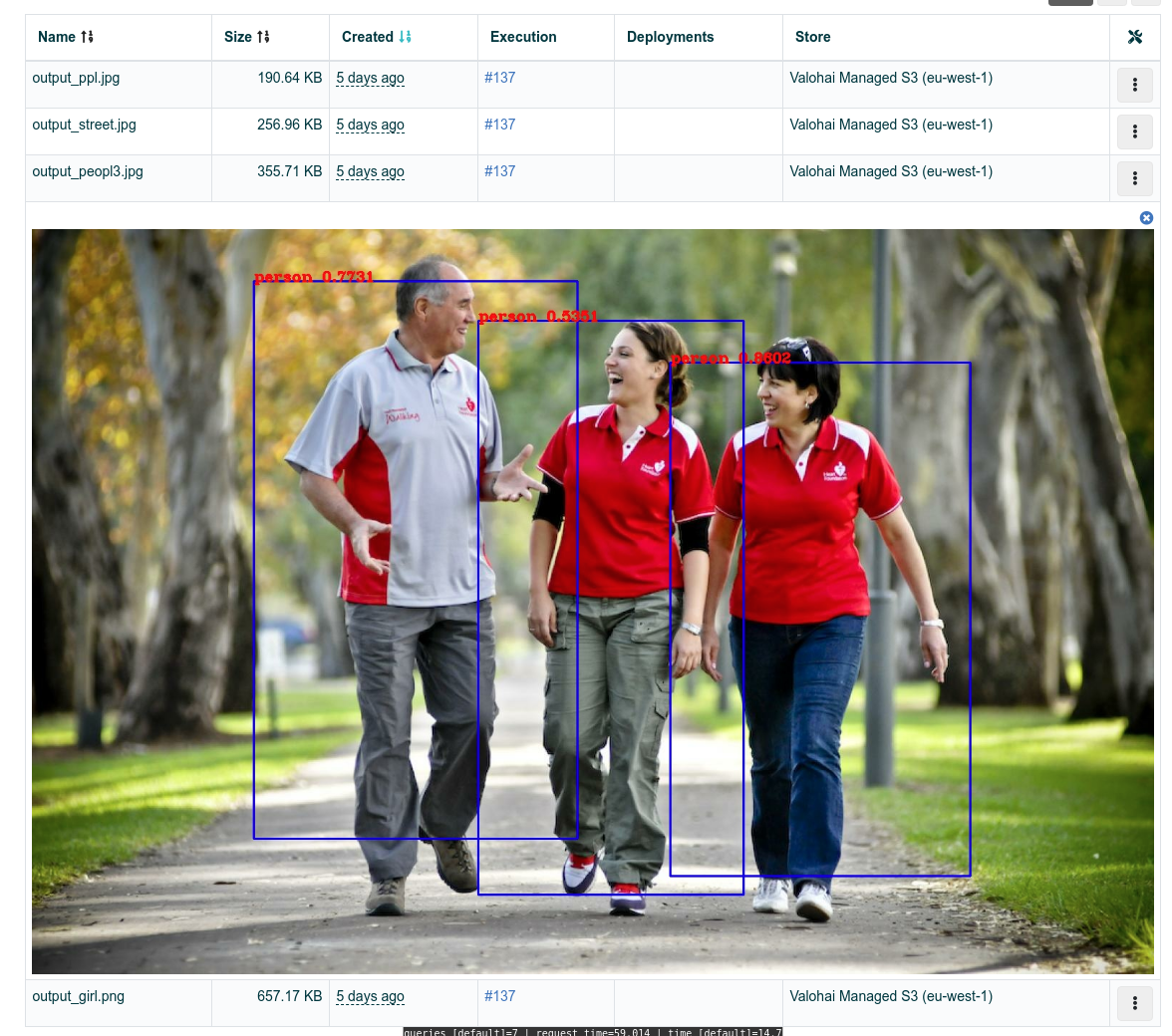
6. 라벨링 반복하기

데이터와 관련있는 모델 최적화 지점을 파악하면, Superb AI Suite의 SDK로 모델의 결과값을 빠르게 전송해서 model-assisted labeling을 위한 반복 사이클을 시작할 수 있습니다.
YOLOv3 모델을 위한 End-to-End 파이프라인 만들기, 어렵지 않습니다.
이 포스팅에서 데이터 관리를 위한 Superb AI, 모델 생애주기 관리를 위한 Valohai라는, 2개의 다른 목적을 가진 플랫폼을 활용해서 어떻게 End-to-End 파이프라인을 구축했는지를 다뤘습니다. 이 실험 전체를 수행하는데 몇 시간만 투자하면 되지만, 모델을 학습시킬 때마다 선행한 작업의 가치가 복합적으로 증대되었습니다.
학습용 데이터셋은 시간이 지나면서 더욱 개선됩니다. 학습 파이프라인과 독립적으로 다시 라벨링을 하거나 데이터를 교체할 수도 있습니다. 마찬가지로, 무중단 시스템 운영을 위해서 End-to-End 파이프라인의 변화 없이, 학습 파이프라인의 코드도 반복 수정할 수 있습니다. 또한, Valohai의 학습 파이프라인은 학습용 데이터셋과 모델링의 복잡도가 증가할 때 더 강력한 GPU로 인스턴스로 쉽게 확장 가능합니다.