
Superb AI의 2021년을 돌아봅니다


Superb AI의 2021년은 ‘성장'이라는 키워드로 요약될 수 있을 것 같습니다. 바쁘게 흘러갔던 2021년을 찬찬히 되돌아보면 매 순간이 ‘빠른 성장’을 위한 모멘텀이었음을 체감하게 됩니다. 이 가파른 성장 곡선의 포문을 연 것은 당연 2021년 1월의 Series A 투자 유치라 할 수 있습니다. 2018년 3월에 Superb AI를 창업한 후 창업 3주년 차에 들어가던 2021년에 우리는 110억의 Series A를 유치하며, 총 약 130억원의 누적 투자 유치에 성공하였습니다. 이 Series A에 힘입어 한국팀과 미국팀 양 팀에서도 연중 내내 제품 개발과 시장 발굴, 서비스 개선에 더욱 박차를 가하고 집중할 수 있었습니다.
한편, 2021년에 저희가 가장 힘을 쏟은 일은 우리의 사용자가 사랑할 수 있는 제품을 만들고, 반복 가능하고 예측 가능한 성장을 일궈내는 일이었습니다. 이를 위해서는 많은 질문을 스스로에게 던지고, 그에 대한 답을 찾아야 했습니다. 가령 우리의 고객들이 가장 필요로 하는, 즉 우리가 해결해 줘야 할 그들의 페인 포인트는 무엇일까? Suite에서 그들이 가장 좋아하는 기능은 무엇이고 또 반대로 가장 손이 가지 않는 기능은 무엇일까? 우리의 제품을 사용하고 구매할 의사 결정자와 진짜 고객을 어떻게 찾아낼 수 있을까? 제품 개발의 우선순위를 어떻게 세울까? 2021년은 이런 질문들에 대한 답을 찾기 위한 방법을 끊임없이 실험하고 찾아내는 한 해 였습니다.
또한, 우리가 도전하는 산업 영역의 큰 그림을 파악하고 전략적인 접근을 시도하는 것도 중요한 부분이었습니다. 우리는 많은 잠재적 파트너들을 찾아 헤매었고, 그들과 이야기를 했고, 또 공동의 목표를 위해 손을 잡았습니다.

Building The Product
Suite는 2021년에 이렇게 더 좋아졌습니다.
Superb AI는 컴퓨터 비전 분야의 데이터 문제 해결에 집중하고 있는 기업입니다. 2020년에는 pre-trained 모델에 근거한 오토라벨링 기능을 처음으로 Suite 내에서 선보였는데, 이 오토라벨링은 약 100개 정도의 물체에 대해 아주 높은 정확도를 보여주었으며, 이에 Suite의 독자적인 기능인 불확실성 추정(Uncertainty Estimation)기술을 덧붙여 개별 라벨링 자동화 작업에 대한 불확실성 정도를 추정할 수 있게 했습니다. 이를 기반으로 머신 러닝 개발 조직이 Suite를 통해 Active Learning 워크플로우를 효율적으로 구현할 수 있게 했습니다. 그 이후 Superb AI는 산업 분야, 기업의 규모, 기업 창립 시기와 무관하게, 다양한 분야의 컴퓨터 비전 실무자들과 많은 이야기를 나눠왔는데, 수 많은 실무자들을 만날수록 Superb AI가 더 정교한 자동화와 다양한 워크플로우 시나리오를 지원해야 한다는 생각에 더욱 확신이 들었습니다.
2021년, 1분기
1분기에는 더 정교한 자동화를 지원하기 위해, 커스텀 오토라벨링(Custom Auto-Label) 기능 개발에 전력을 쏟았습니다. 커스텀 오토라벨링은 라벨링 자동화 작업의 가능한 물체의 한계를 없앴고, 데이터셋을 구축할 때나 반복되는 데이터 작업 시의 속도를 혁신적으로 개선해주었습니다. 또한 Suite와 AWS S3와 Google Cloud Platform을 1분기에 연동 시켰고, 데이터 저장소로써 클라우드 플랫폼 서비스를 바로 연결해서 사용하거나 로우 데이터를 클라우드에서 Suite로 바로 불러들이는 것도 가능해 졌습니다.

2021년, 2분기
오토라벨링이 더 좋아졌습니다. 오토라벨링에서 키포인트 유형의 작업을 지원하게 되었고, Suite의 UI/UX 전반에 대한 개선이 있었습니다. SDK도 더 좋아졌으며 사용 예시도 더욱 보강되었습니다.
2021년, 3분기
매뉴얼 라벨링 검수 워크플로우를 지원하기 위한 여러 가지 기능이 개발되었습니다. 이는 라벨러, 검수자 사이의 비효율적이고 반복적인 검수 과정을 매끄럽게 가다듬기 위한 노력이었는데, 그 동안 많은 조직에서 이 반복되는 과정 속에서 불필요한 고통과 높은 비용을 감수하고 있었습니다. 라벨 할당, 제출, 리뷰와 검수와 같은 단계를 매끄럽게 만들어 데이터 작업의 효율을 높였을 뿐만 아니라 데이터 작업 결과물의 일관성 향상에 도움을 드릴 수 있었습니다. 또한 3분기에는 고객이 생성한 커스텀 오토라벨링의 성능을 확인할 수 있는 성능 지표(Performance Metrics)를 제공하기 시작했고, 멀티 폴리곤 세그멘테이션 지원도 시작 되었습니다.
2021년, 4분기
자동화 기능이 더욱 강해지고, 번거로운 일들의 손을 더 덜어드렸습니다. 커스텀 오토라벨링에서 분류(classification) 기능을 제공하기 시작했고, 학습용 데이터(train data)와 검수용 데이터(validation data)를 분류할 수 있게 되었습니다. 그리고 오토라벨링 UI도 새롭게 바뀌어, 더욱 예쁘고 편리해졌습니다. 다양한 컴퓨터 비전 분야의 과업에서 그라운드 트루스(Ground Truth) 데이터로 활용할 수 있는 공개 데이터셋을 큐레이션하여 제공하였습니다.
다가올 2022년의 Suite 로드맵
2022년에 Superb AI는 라벨링과 관련된 더 고도한 기능을 세상에 내어놓기 위해 집중할 예정입니다. 예를 들어 컨센서스 라벨링 워크플로우를 위한 기능을 제공하거나, 라벨링 작업 도구 UI를 더 직관적으로 만드는 것과 같은 것들이 있겠습니다. 더 다양한 컴퓨터 비전 과업을 다룰 수 있게 돕고, 고객들이 다루고 있는 다양한 데이터 유형을 지원하기 위한 기능도 차근차근 준비하고 있습니다. 내부 성능을 높이기 위한 리팩토링 작업 또한 계획되어 있습니다. 이를 통해 대규모 작업의 속도가 더욱 빨라지고, 데이터 검색 성능이 높아지고, Analytics의 동기화도 거의 실시간으로 가능할 것으로 예상하고 있습니다.
하지만 우리가 해야 할 일이 데이터 라벨링 작업의 고도화에만 국한된 것은 아닙니다. 물론, 데이터 라벨링은 우리에게 매우 중요한 부분이지만, Superb AI는 데이터 중심의 인공지능 개발에서 컴퓨터 비전 과업을 지원 하기 위한 DataOps 플랫폼과 서비스를 세상에 내어 놓기 위해 용기 있게 한 발짝 앞으로 나아갈 예정입니다. 데이터 분석 분야에서 DataOps 원칙과 원리를 찾기 위해 끊임 없이 탐험하고, 기업에서 활용하는 컴퓨터 비전 기술 속에서 데이터 도전과제를 찾아내고, 고품질 데이터 작업을 통해 문제를 해결하기 위한 구조적이고 조직적이고 본질적인 해결책을 찾아나설 것입니다. 이미지 검색과 비디오 검색과 같은 DataOps 기능을 개발하고, 메타데이터에 대한 분석을 제공하며, 데이터 전처리와, 라벨링 오류 탐지(mislabel detection)와 디버깅, 워크플로우 자동화, 데이터 엔지니어를 위한 데이터 버저닝과 브랜칭 등등 다양하고 도전적인 과제들을 해결할 준비를 마쳤습니다. 늘 발전하는 Suite를 기대하세요!
Building Industry Partnerships
2021년 3월, Superb AI는 인공지능의 표준 스택을 만들어가기 위해 설립된 AI Infrastructure Alliance에 가입했습니다. 이 연합은 인공지능 개발 인프라 생태계 속에서 다양한 역할을 하고 있는 서비스와 기술을 매끄럽게 연결하여 엔지니어링 표준을 만들려는 포부를 갖고 출발한 것입니다. Superb AI가 AI Infrastructure Alliance에서 함께 진행한 가장 규모있는 첫 프로젝트는 현실 세계의 AI/ML 워크플로우에 대해 모두가 알 수 있도록 청사진을 함께 그리는 것이었습니다.
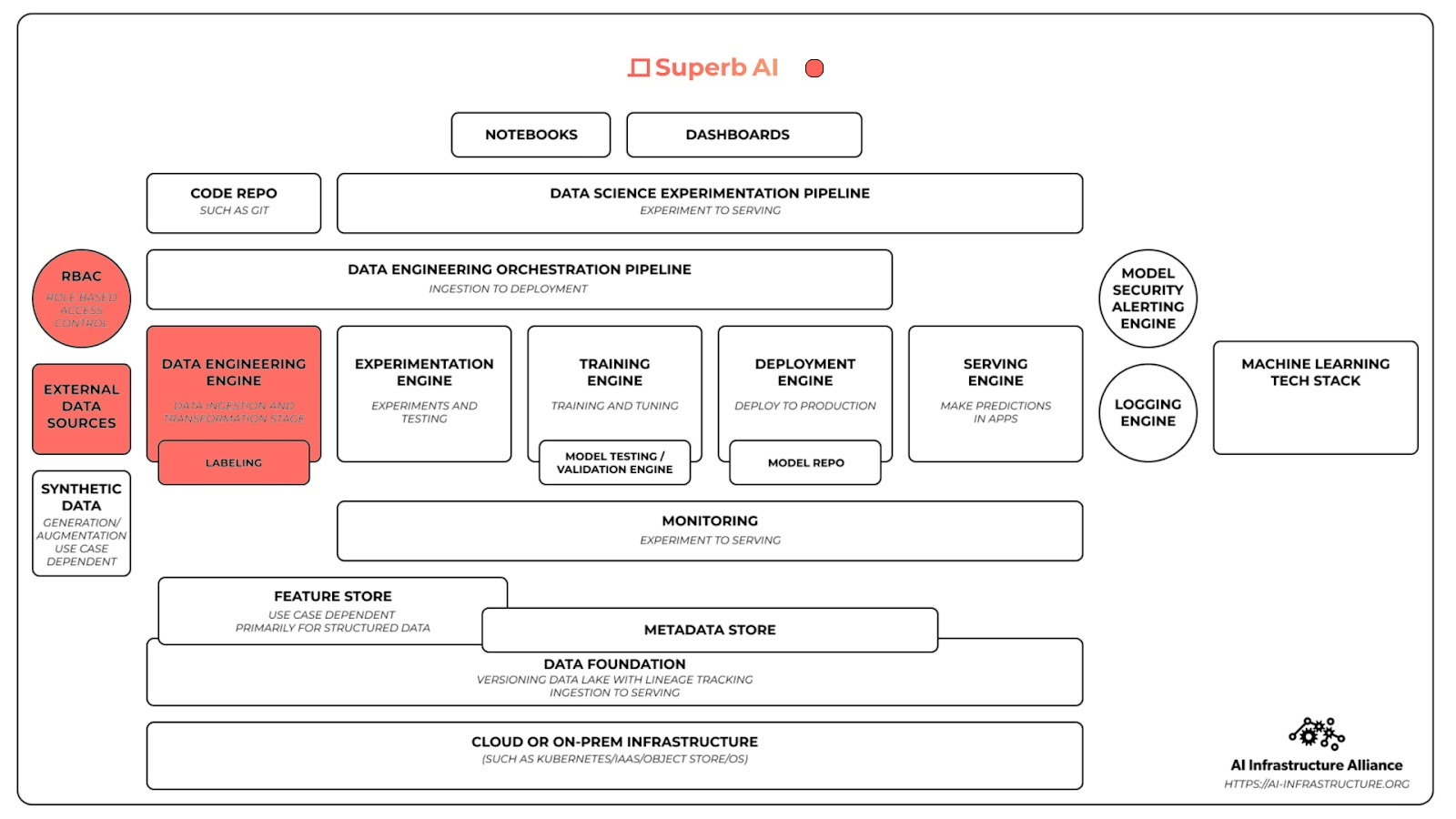
위의 도표에서 확인할 수 있다시피, Superb AI는 데이터 엔지니어링 엔진 부분에 기여합니다. 이는 데이터 가져오기(data ingestion)과 데이터 변환(data transformation), 데이터 라벨링과 같은 단계가 포함됩니다. 이 관점에서, 우리는 AIIA 파트너 중 다음과 같은 파트너들과 함께 자연스럽게 손을 잡게 되었습니다.
1. Valohai는 강력한 MLOps 플랫폼을 제공하고 있는 기업입니다. 머신 러닝 개발에서 또 다른 페인포인트로 언급되는 파이프라인 오케스트레이션과 모델 배포를 다룹니다. Valohia와 Superb AI가 어떻게 힘을 모았는지를 이 글을 살펴 봐주세요.
2. Pachyderm은 데이터 버저닝과 데이터 파이프라인 구축 등을 통해 머신 러닝 개발을 위한 데이터 파운데이션을 제공합니다. 데이터 중심의 접근을 실현하기 위해 두 솔루션을 어떻게 연계하여 사용할 수 있을지 이 글을 살펴 봐주세요.
3. WhyLabs는 우리가 머신 러닝 배포 과정에서 놓치고 있는 것이 무엇인지 모니터링 하는 것을 도와주는 서비스입니다. AI 관찰가능성을 높여주는 WhyLabs와 투명한 데이터 관리를 돕는 Suite가 만나 데이터 믿음직한 데이터 운영을 가능하게 하는 워크플로우 구축에 대한 사례를 여기에서 보실 수 있습니다.
4. Arize AI는 머신러닝팀에게 발생하는 이슈를 재빨리 발견하고 그 이면에 있는 문제를 트러블슈팅하는 걸 도와주는 플랫폼을 제공합니다. 어떻게 정형, 비정형 데이터의 품질을 보증할 지에 대한 두 솔루션의 접근법을 살펴보세요.
2022년의 우리의 목표는 더 많은 솔루션과 Suite를 연동하고, 더욱 다양한 마케팅 활동을 통해 이 파트너십을 더욱 튼튼하게 이어가는 것입니다. 모델 실험 엔진(model experimentation engine), 데이터 과학 노트북(data science notebooks), 피쳐 스토어(feature stores) 등 AI와 데이터 생태계에서 중요한 역할을 하고 있는 더 많은 스타트업과 관계를 맺고 나아가고자 항상 주변을 살피고 있습니다.
Superb AI Team의 2021년 여정
모두에게 숨 가쁜 시간들이었지만, 이 시간들을 다시금 찬찬히 되짚어 봅니다. 매 순간, 최선을 다한 구성원들과 Suite를 만들어준 고객들 파트너들에게 감사함을 느끼게 됩니다.
2021년 1월
약 110억원의 Series A를 성공적으로 달성했습니다.
Superb AI의 고품질 데이터 구축 노하우를 담아 데이터 라벨링 전문성 강화 프로그램 2021 (Webinar)를 진행했습니다.
2021년 2월
데이터 라벨링 프로젝트의 현실적 장벽인 크라우드 소싱 노하우를 담은 크라우드소싱 관리 백서를 출간 해서 무료로 배포 했습니다.
2021년 3월
AI Infrastructure Alliance에 가입했습니다.
AIIA의 일원인 Valohai와 손을 잡고 실리콘밸리의 ML옵스 백서(한국어)를 제작하여 무료로 배포했습니다. 국내에 ML옵스에 대한 가이드가 전무한 상황에서 ML옵스의 개념과 실제 도입 사례, 도구 소개 등 핵심적인 개념을 간결하게 소개했습니다.
2021년 5월
인공지능 데이터의 중요성이 널리 인식됨에 따라, Superb AI 김현수 대표가 90년대생 최연소로 4차산업혁명위원회 위원으로 선정되었습니다.
2021년 6월
국내 유일의 ML옵스 커뮤니티인 MLOps KR 커뮤니티를 후원하고, 이정권 CTO가 기술 발표도 하고 네트워킹 세션도 진행했습니다. 데이터 중심의 인공지능(Data-Centric AI)개발에 대한 커뮤니티의 관심을 느낄 수 있었고, 생태계에 기여할 수 있어 기뻤습니다.
2021년 7월
월간 Superb AI 세미나를 시작했습니다! 고품질 데이터 구축에 관한 노하우, 데이터 중심 인공지능(Data-Centric AI)과 DataOps, MLOps 등 유익한 정보들을 매달 선정하여 웨비나를 운영하고 고객들을 만나고 있습니다.
2021년 8월
글로벌 수준의 데이터 보안 인증인 SOC2 Type Ⅱ인증을 받았습니다. Superb AI 한국 오피스가 강남역으로 이사왔습니다. 더 많은 사람들과 더 큰 꿈을 달성하게 해줄 오피스는 여기에서 둘러보실 수 있습니다.
Superb AI가 유익한 MLOps 소식들을 모아 MLOps Insight 뉴스레터를 발송하기 시작했습니다. MLOps Insight라는 이름의 뉴스레터로 매달 여러분의 우편함을 찾아갑니다.
2021년 11월
MIT Technology Review가 선정한 젊은 혁신가인 IU35에 제가 선정되었습니다. 인공지능 개발의 장벽인 데이터 문제를 해결하겠다는 기업가 정신과 Suite의 기술 혁신을 높게 평가한 결과입니다.
2021년 12월
한국의 여러 기업들을 만난 결과로, “한국의 기업들은 Data-Centric에 얼마나 준비되어있을까?” 백서를 발간했습니다. 한국의 인공지능 데이터 시장의 전반적인 상황을 훑어보실 수 있습니다.
Thank You
Suite와 함께 하는 모든 팀에게 감사함을 전합니다. Superb AI는 머신 러닝 시스템을 위한 학습용 데이터를 관리하기 위한 효율적인 방법을 찾고 있을 뿐 만 아니라, 머신 러닝 실무자들이 급박한 변화하게 비즈니스 환경속에서 신뢰롭게 데이터를 구축하기 위한 협업을 개선하는 것을 목표로 삼고 있기도 합니다. 우리와 같은 문제 의식과 공감을 갖고 있는 우리의 고객들 또한 Superb AI를 더 좋은 플랫폼으로 만들어주고 있습니다. 감사합니다!