
Superb AI의 오토라벨링


인공지능 산업 규모는 해마다 커지고 있습니다. 조사에 따르면, 2025년까지 전세계 인공지능 시장 산업 규모는 1조 2600억달러까지 성장할 예정입니다. 하지만 빠르게 성장하는 만큼, 인공지능 개발 단계의 효율화라는 과제가 남아있습니다.
특히 인공지능 개발의 첫 단계인 데이터 구축단계에서는 인간의 수동 반복 작업이 많이 필요합니다. 엔지니어가 모델을 설계하거나, 인공지능을 학습시키는 것은 이 데이터 구축단계가 완료된 후에야 시작할 수 있습니다. 실제로 AI 개발 시간 중 80%는 AI 모델 학습에 필요한 데이터셋을 가공·구축하는데 사용된다고 해요.
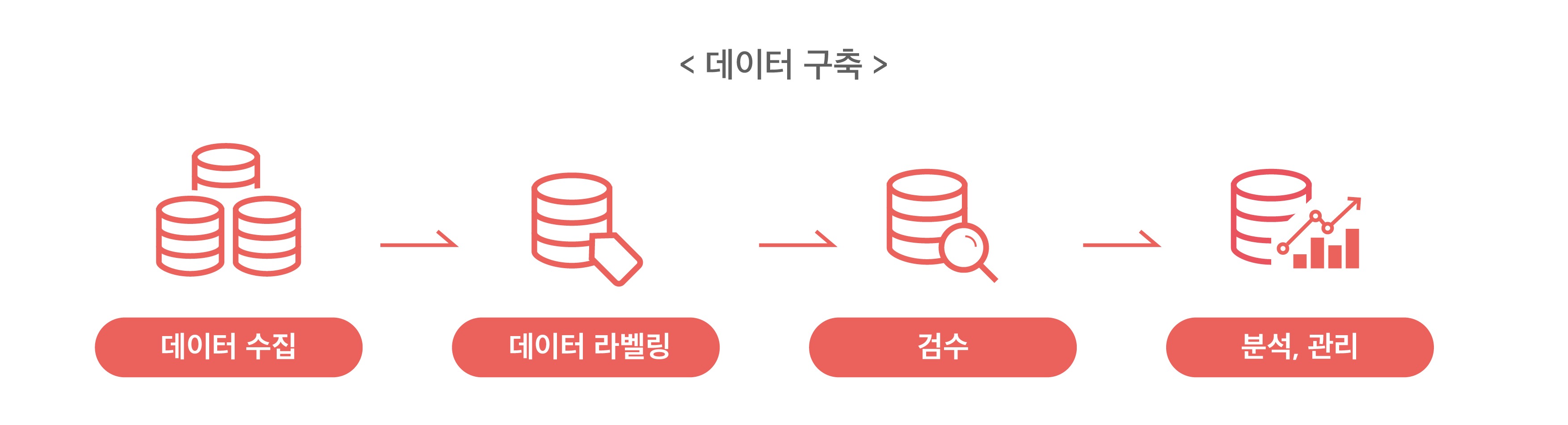
인공지능 데이터 구축의 단계
슈퍼브에이아이는 인공지능의 민주화를 목표로, 이와 같은 인공지능 개발의 병목을 해결하기 위해 노력하고 있습니다. 2020년 8월에는 5개 미국 특허 출원과 함께 이미지 내 오브젝트를 자동으로 탐지하여 라벨링하고, 일부 검수작업을 자동화시키는 Superb Auto-labeling™ 기술을 개발, Suite에 탑재하였습니다. 자체 오토라벨링 적용 실험을 통해 최대 10배의 생산성 향상 효과를 검증하였고, 한 인공지능 개발사 A와 실제 프로젝트를 수행한 결과, 매뉴얼 라벨링 대비 생산성이 7.64배 향상됨을 확인하였습니다.
매뉴얼 데이터 라벨링은…
데이터 라벨링은 이미지 속에서 라벨링할 오브젝트를 찾고, 포인트를 찍고, 객체의 종류를 선택하는 작업을 말합니다. 자세하게는 다음과 같은 과정을 거칩니다.
<데이터 라벨링 프로세스>
- 탐색 : 원본 데이터에서 라벨링할 물체를 찾고 확인하는 단계
- 발견 : 원본데이터 내 모든 오브젝트를 표시(바운딩 박스, 폴리곤 세그멘테이션 등)하는 작업
- 인지 : 표시한 오브젝트에 클래스(예 : 사람, 차 등) 및 속성(예 : 여자/남자, 세단/SUV 등)을 설정하는 단계
- 검수 : 라벨링 결과물 확인 및 수정을 요청하는 작업
이 중 ‘발견’ 단계는 시간이 가장 많이 소요되는 단계입니다. 특히 폴리곤 세그멘테이션(일명 ‘누끼’를 따는 작업)을 사용하는 경우, 사람이 오브젝트의 가장자리에 일일이 포인트를 찍어야 하기 때문에 소요시간이 긴 편입니다. 오브젝트에 따라 평균 라벨링 시간은 15초~1분까지 다양합니다.
검수 또한 마찬가지입니다. 라벨링 조건에 맞지 않는 어노테이션들을 일일이 찾아내야 해서, 수동으로 진행할 경우 품이 꽤 들게 됩니다. 인공지능 학습용 데이터셋의 품질을 결정짓는 과정이기 때문에, 라벨링 인력 외에 검수 인력을 따로 두는 것이 일반적입니다.

사람이 직접 매뉴얼 라벨링하는 모습
실제 매뉴얼 라벨링하는 화면을 정속으로 녹화해보았습니다. 위 이미지의 경우, 사람을 모두 바운딩 박스로 라벨링해야 하는 데이터입니다. 13명의 사람이 있는 이미지를 라벨링하는 데 2분 30초 가량이 소요됐습니다. 보통 인공지능을 학습시키는데 적게는 수만 장, 많게는 수백만장이 필요하다고 합니다. 평균 10개의 오브젝트가 있는 데이터 100만장을 라벨링할 때, 풀타임 라벨러 10명이 작업할 경우 347일, 50명일 경우에는 69일이 소요됩니다.
하지만, 서비스 수준의 인공지능을 개발할 때는 훨씬 더 복잡한 수준의 데이터를 다루게 됩니다. 위성, 자율주행 이미지와 같이 복잡도가 높은 데이터는 이미지 1개의 라벨링을 완료하는데 몇 십분까지도 걸린다고 합니다. 또 사람의 작업능률은 시간에 따라, 환경에 따라 편차가 발생할 수도 있죠.
시간을 단축해주는 오토 라벨링
이번에는 오토라벨링을 사용해봅시다. 예시로 위의 이미지를 포함한 16장의 데이터에 대해 오토라벨링을 적용해보았습니다. Superb AI Suite에서는 원하는 데이터를 선택하고 Auto-Label 버튼만 누르면 라벨링을 완료할 수 있는데요, 서버 환경이나 요청 라벨 수에 따라 달라지겠지만 보통 수 분내에 완료됩니다.
Suite에서 오토라벨링을 실행하는 화면
<Superb Auto-labeling™ 실행 단계>
1. Label list에서 라벨 선택
2. ‘Auto Label’ 버튼 클릭
3. 새로고침
4. 오토라벨링 난이도 확인 후 검수요청된 라벨 검토
다시 라벨링 프로세스로 돌아가봅시다. 오토라벨링을 사용하는 경우, 데이터 라벨링의 각 단계에서는 다음과 같은 변화가 생깁니다.
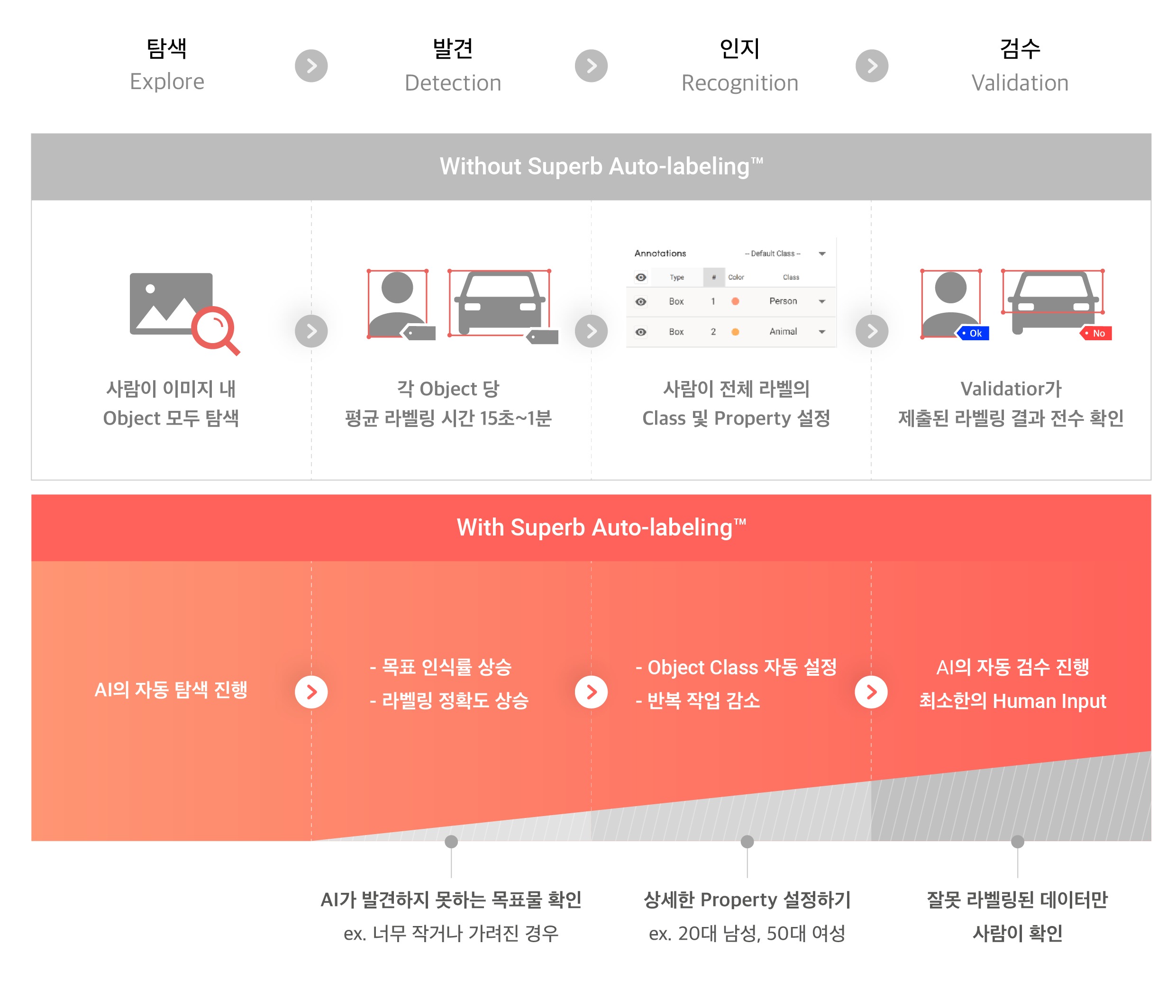
Without/With Superb Auto-labeling™
- 탐색 : 원본 데이터에서 라벨링할 물체를 찾고 확인하는 단계
→ 오토라벨링이 탐색을 진행합니다.
- 발견 : 원본데이터 내 모든 오브젝트를 라벨링(바운딩 박스, 폴리곤 세그멘테이션 등)하는 작업
→ 오토라벨링이 pre-labeling을 진행합니다.
- 인지 : 표시한 오브젝트에 클래스(예 : 사람, 차 등) 및 속성(예 : 여자/남자, 세단/SUV 등)을 설정하는 단계
→ 오토라벨링이 오브젝트 클래스를 자동으로 설정합니다. 사람이 클래스를 일일이 선택하는 작업이 줄어듭니다.
- 검수 : 라벨링 결과물 확인 및 수정을 요청하는 작업
→ 라벨링이 완료된 데이터에 대해 오토라벨링이 한 번 더 검수를 진행하며, 확실하지 않은 어노테이션에 대해서는 알림을 줍니다. 라벨러는 이 알림을 확인하고, AI가 발견하지 못한 오브젝트 확인 및 라벨링 작업만 수행하면 됩니다.
이와 같이 Superb Auto-Labeling은 라벨링 뿐 아니라 데이터 난이도를 측정하여 일부 검수 기능도 대신해줍니다. 난이도를 쉬움, 중간, 어려움으로 나누고, 스스로 판단하기 어려운 오브젝트에 대해서는 사람의 검수를 요청합니다. 해당 어노테이션은 노란색으로 표시되며 상세보기 페이지 상단에서 알림을 볼 수 있습니다. 이렇게 되면 난이도가 낮은 데이터는 Superb Auto-Labeling에게 맡기고, 사람은 복잡하고 어려운 데이터를 처리하는데 집중할 수 있게 됩니다. 단순 반복작업은 줄어들어 고난이도의 영역을 인간이 담당하는 거죠.
오토라벨링, 데이터 작업의 생산성을 높이다
실제 Suite의 오토라벨링을 활용한 고객 사례를 소개합니다. 까다로운 데이터를 다루는 분야에서, 세계적으로 인정받는 기술력을 지닌 인공지능 개발사 A입니다. 우리는 A사를 통해 오토라벨링을 사용하지 않은 경우와 사용한 경우에서 확연한 생산성 차이를 확인할 수 있었습니다.
“라벨러 1인의 작업 생산성 7.64배 높이다”
슈퍼브에이아이는 2020년 A사와 동일한 데이터 프로젝트를 여러 번에 걸쳐 진행했습니다. 첫 프로젝트는 100% 매뉴얼 라벨링으로 이뤄졌습니다. 오토라벨링 기능을 사용하지 않았을 때, 라벨러 1명이 1시간 동안 평균 6.57개의 이미지 데이터를 처리 한 것으로 확인되었습니다. 오토라벨링 기능이 구현된 후, 동일한 데이터 작업을 진행 했을 때 1명의 라벨러는 1시간 동안 평균 50.25개의 이미지를 처리할 수 있었습니다. 무려 7.64배 빠른 속도의 작업이 가능했습니다.
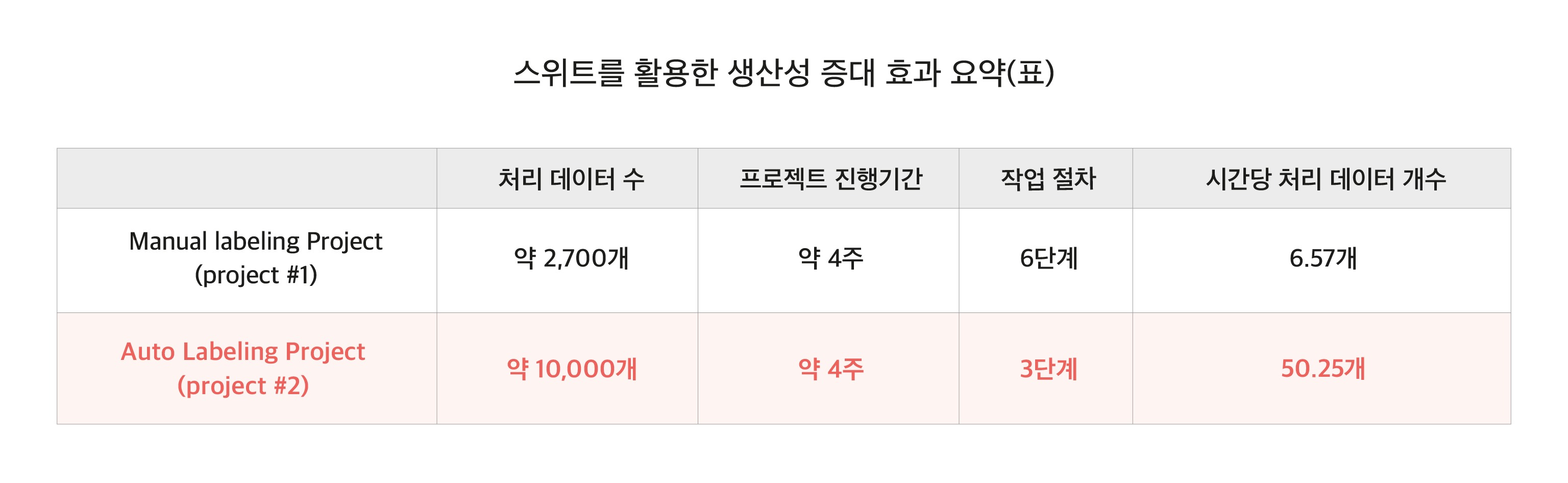
“작업 단계를 절반으로 줄이다”
7.64배의 작업 효율 향상이 가능했던 이유는, 작업 단계를 절반으로 줄일 수 있었기 때문입니다. 오토라벨링을 활용하지 않았던 첫 번째 프로젝트의 경우, 1차 라벨링 → 1차 검수 → 수정 → 1차 최종 검수 → 수정 → 2차 최종 검수, 총 6단계의 과정으로 진행 되었습니다. 손으로 도형을 직접 그리고 라벨링 해야 하는 1차 라벨링의 단계에서 절대적인 시간이 소요되었음은 물론, 검수자가 검수를 진행하고 작업자가 수정을 해야 하는 단계가 반복적으로 수행 되어야 했습니다. 하지만 오토라벨링을 활용한 후에는 절대적인 시간이 필요한 1차 라벨링 작업은 아예 불필요 해졌으며, ‘(스위트의 오토라벨링 & 검수 요청) → 1차 수정 → 최종 검수 → 수정’의 3단계로 작업 절차가 절반으로 줄어 들었습니다.
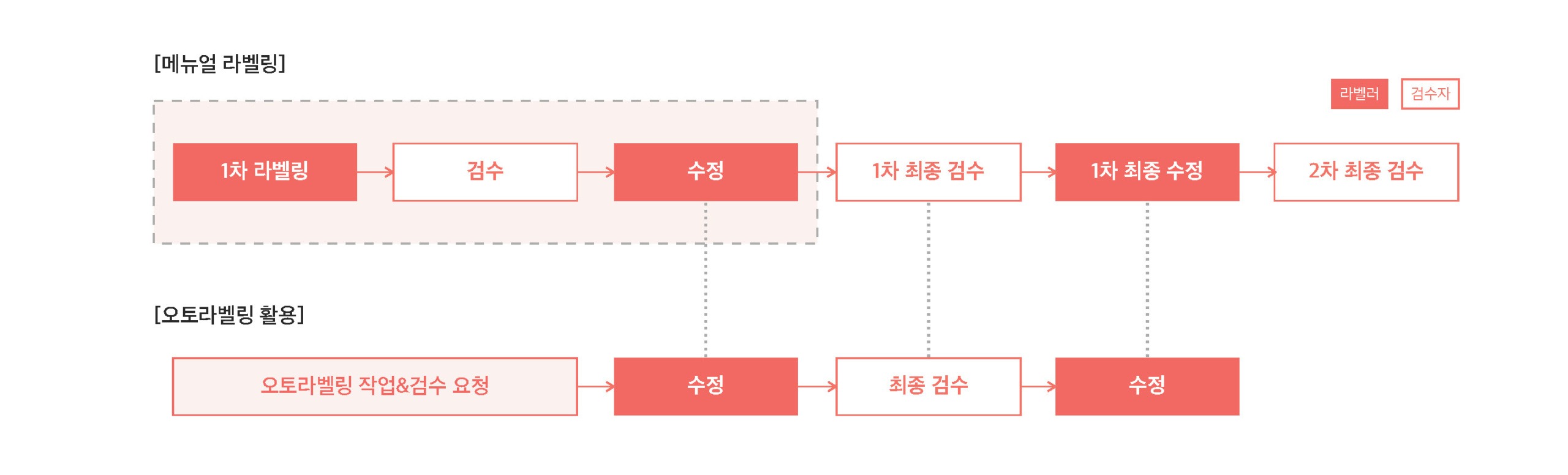
작업단계 : 매뉴얼 라벨링 vs. 오토라벨링
스위트의 오토라벨링, 더 강력해 질 겁니다
Superb AI는 스위트의 오토라벨링을 지속적으로 고도화합니다. 오토라벨링을 수행할 수 있는 객체의 수를 큰 폭으로 확대하고, 일반적이지 않고 데이터의 수가 부족할 수 밖에 없는 객체도 오토라벨링을 지원할 수 있는 기술을 준비 중입니다. 2020년 말에는 Enterprise plan 고객을 대상으로 고객사의 데이터에 특화된 Custom Auto-labeling을 선보일 예정입니다.