Summary:
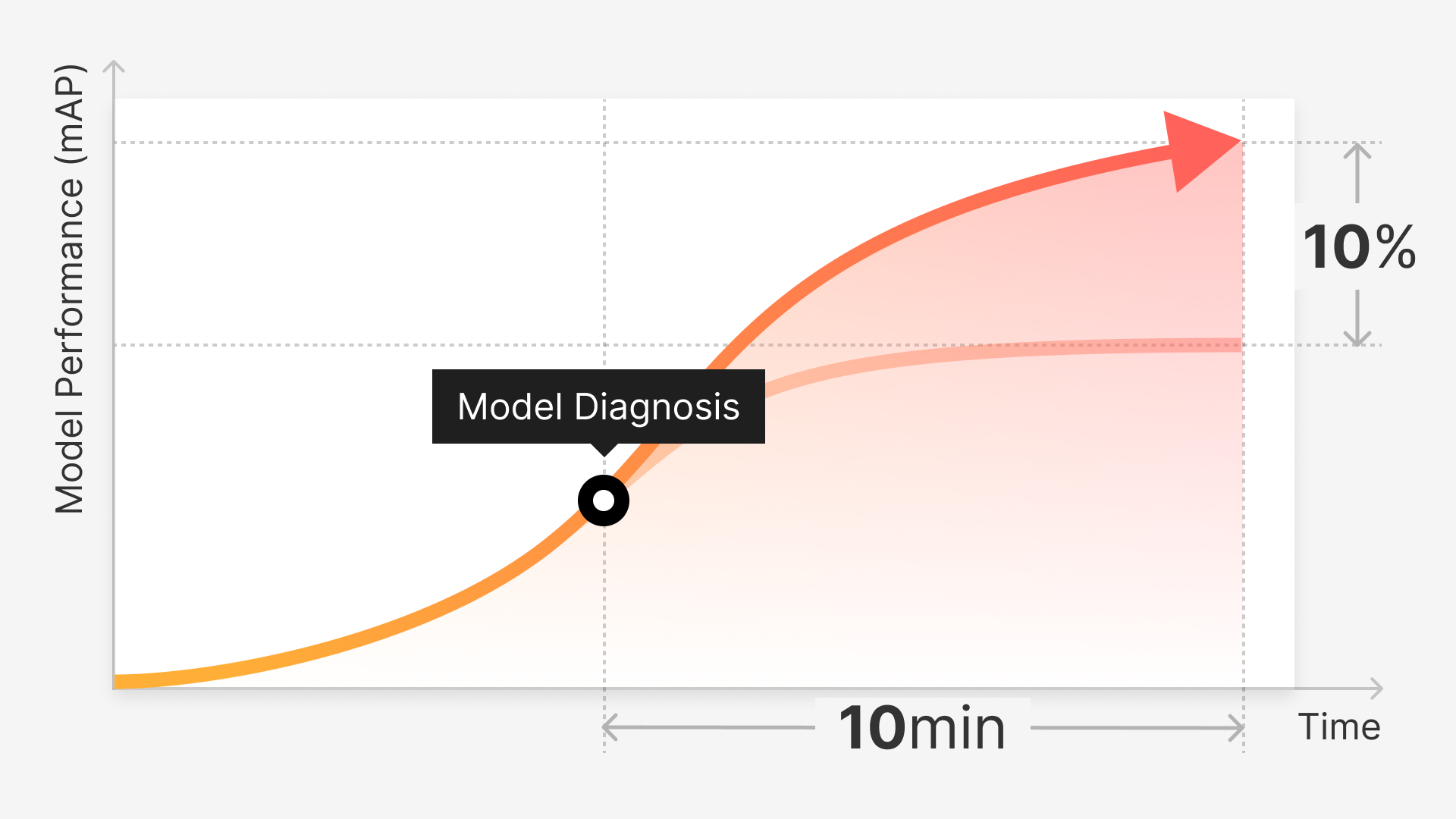
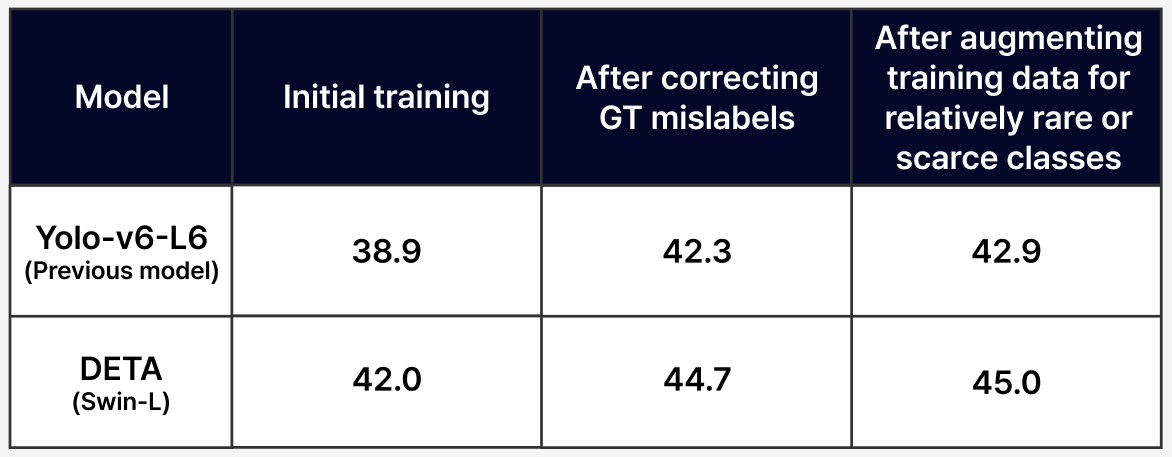
We have undertaken a thorough process of training an AI model, assessing its performance, identifying model vulnerabilities, and addressing them through Superb Platform for enhanced performance. Consequently, the model’s average accuracy (mAP) has improved from 38.9 to 42.9.
The steps in our process include:
1. Curate and process (label) data
2. Train a model
3. Diagnose the model’s performance
4. Identify and address model vulnerabilities
5. Re-train the model
6. Augment data
7. Re-train the model again, diagnose its performance, and deploy
Introduction
In our previous blog series, we discussed the importance of continuous improvement and optimization in AI model development. We also covered the definitions and applications of key metrics for diagnosing model performance.
In this article, we will guide you through the process of pinpointing and addressing model vulnerabilities through Model Diagnosis with a step-by-step approach.
In this experiment, we utilized an open-source dataset called BDD 100K.
About BDD 100K: A Large-scale Diverse Driving Video Database Dataset
Released by the Berkeley Artificial Intelligence Research, BDD 100K is a comprehensive dataset comprising 102 million images, complete with GPS, IMU, timestamp, and other metadata for use in diverse applications.
Its diverse data, primarily designed for road network applications, includes pre-labeled objects such as lanes, vehicles, people, and road infrastructure.
Experiment Objective:
We expect this experiment to provide valuable guidance for businesses facing challenges in AI model advancement post-adoption. Our goal is to aid companies who have experienced setbacks after huge time and resource investments due to subpar AI model performance or those who have failed AI adoption as they encountered performance degradation in real-world (Wild) applications compared to test environments (PoC). By sharing our findings and solutions through the Superb Platform experiment, we intend to facilitate successful AI integration into business operations.
Experiment Overview:
Continuous iteration of the following procedures is essential for companies to develop, deploy, maintain, and enhance their AI models. As we have mentioned numerously, this is a crucial part of the MLOps pipeline, which many companies (including us at Superb AI) and research institutions are now stressing as highly important.
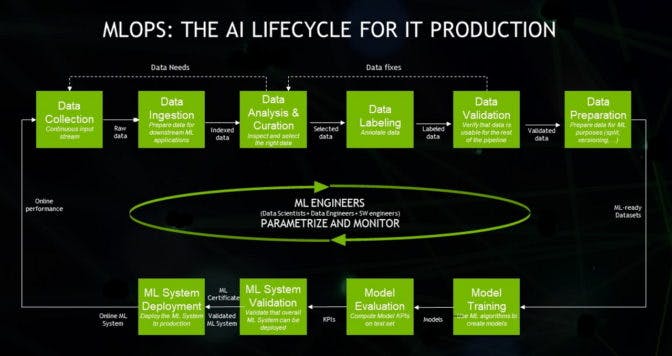
The process is comprehensive and intricate, yet we've distilled it with a focus on 'model performance improvement,' the primary goal of this experiment:
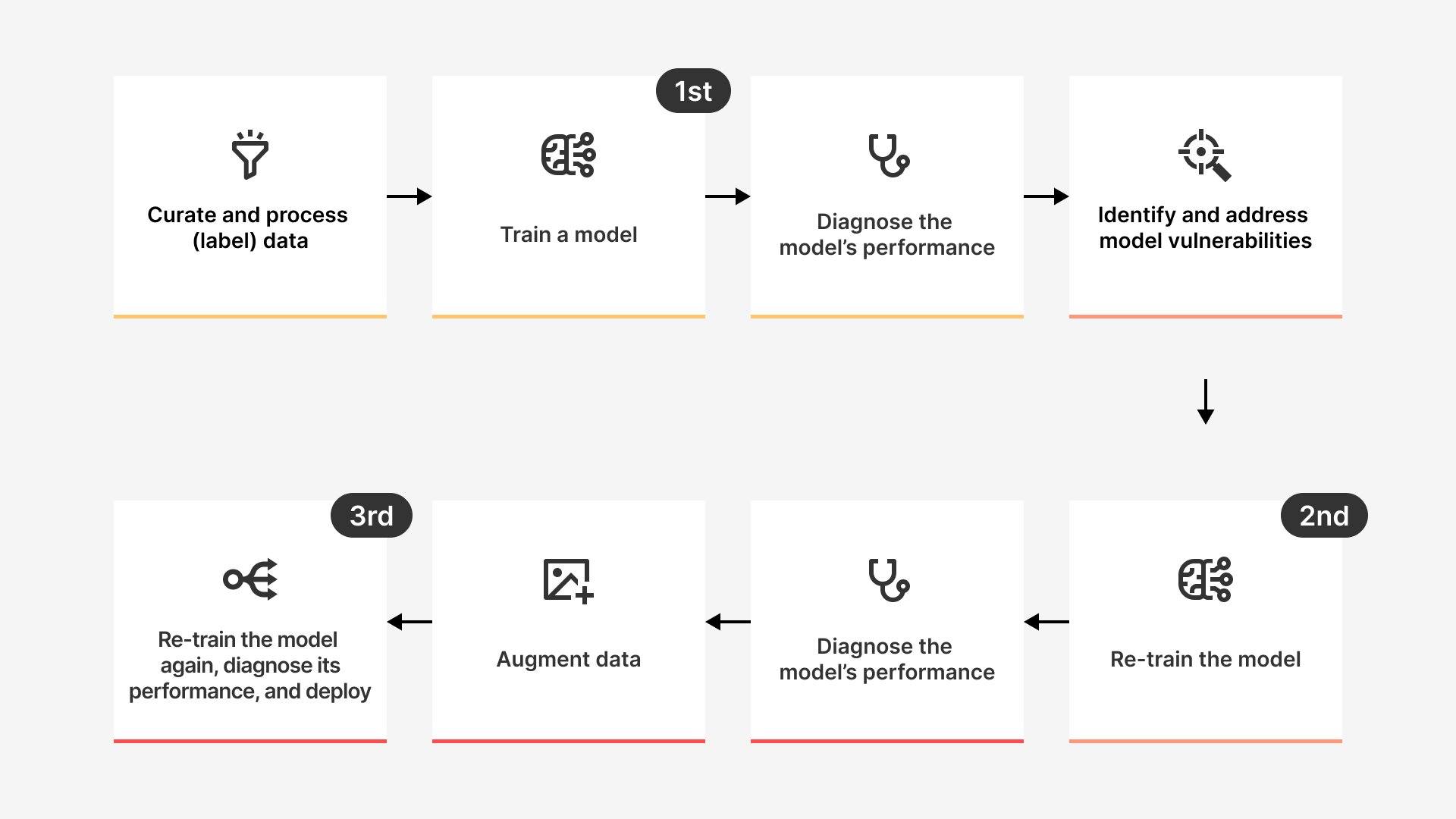
1. Data curation:
(Data processing (labeling))
2. Model training
3. Model performance diagnosis
4. Model vulnerability identification and improvement
5. Model re-training
6. Data augmentation
7. Additional re-training, model performance diagnosis, and deployment
Let's delve into how these steps collectively enhance the performance of a model in its early stages.
1. Data curation:
First, we utilize the 'Auto-curate - Split train/validation set' feature to select 30,000 images from the BDD 100K dataset and divide them into a training dataset and a validation dataset. We opted for a 4:1 ratio, allocating 24,000 images for training and 6,000 for validation.
The curated dataset forms a separate data group referred to as a ‘slice**.’
Why 30,000 images?
This figure stems from our previous experiment's findings, demonstrating that models trained on smaller datasets can achieve performance comparable to those trained on larger ones. Training on a smaller dataset optimizes various resource usage, including data labeling and training time.
BDD 100K dataset
size : 30,000 images
Train dataset:
Slice name: “train experiment v1”
size: 24,000 images
Validation dataset
Slice name: “validation experiment v1”
size: 6,000 images
What is Auto-Curate from Superb Curate?
Auto-Curate is a feature that automatically curates data based on user requirements, and it offers 4 options:
What is a Slice?
A slice is a subset of a dataset, serving as the basic unit for all data-related activities in Superb Curate. Users can create slices for specific characteristics or purposes.
(Source: https://docs.superb-ai.com/docs/slice)
2. Model training
With data curation complete, we proceed to model training. Superb Model currently offers 5 high-performance baseline models, enabling users to select the most suitable one based on capacity, speed, supported annotation types, and so on. In this experiment, we used the 'YOLOv6-L6' model.
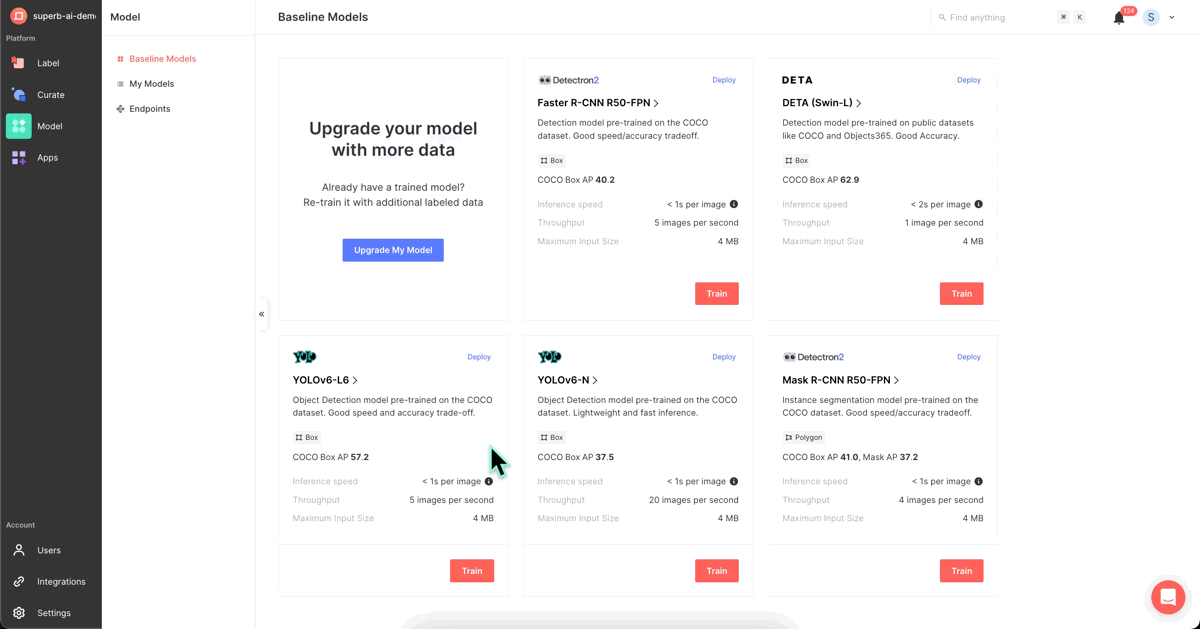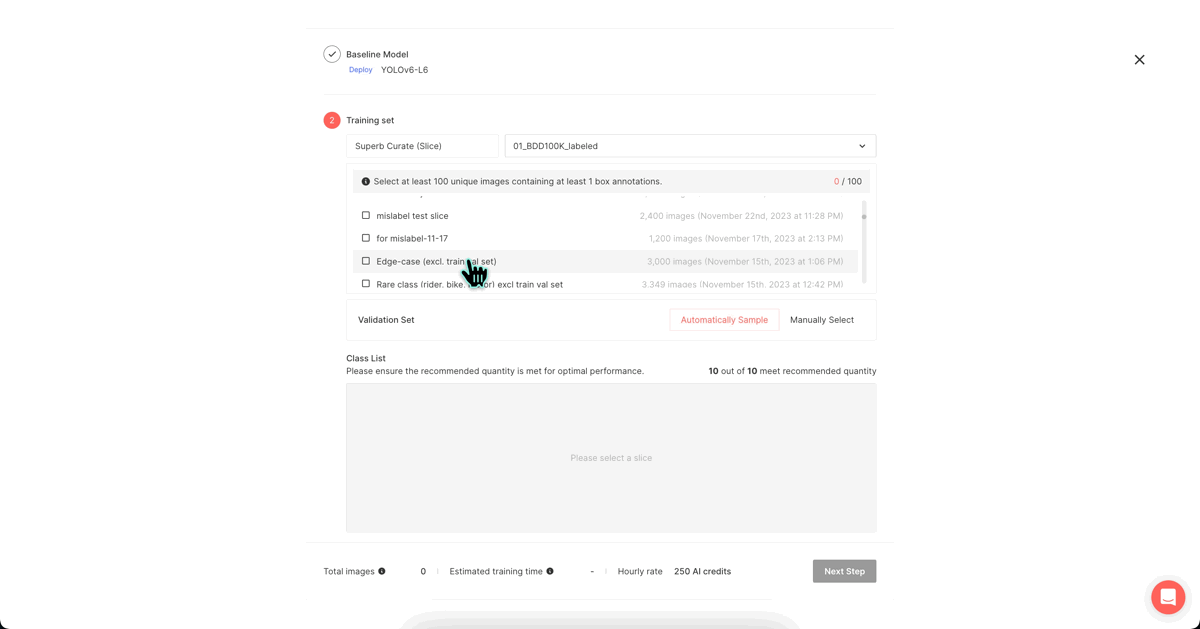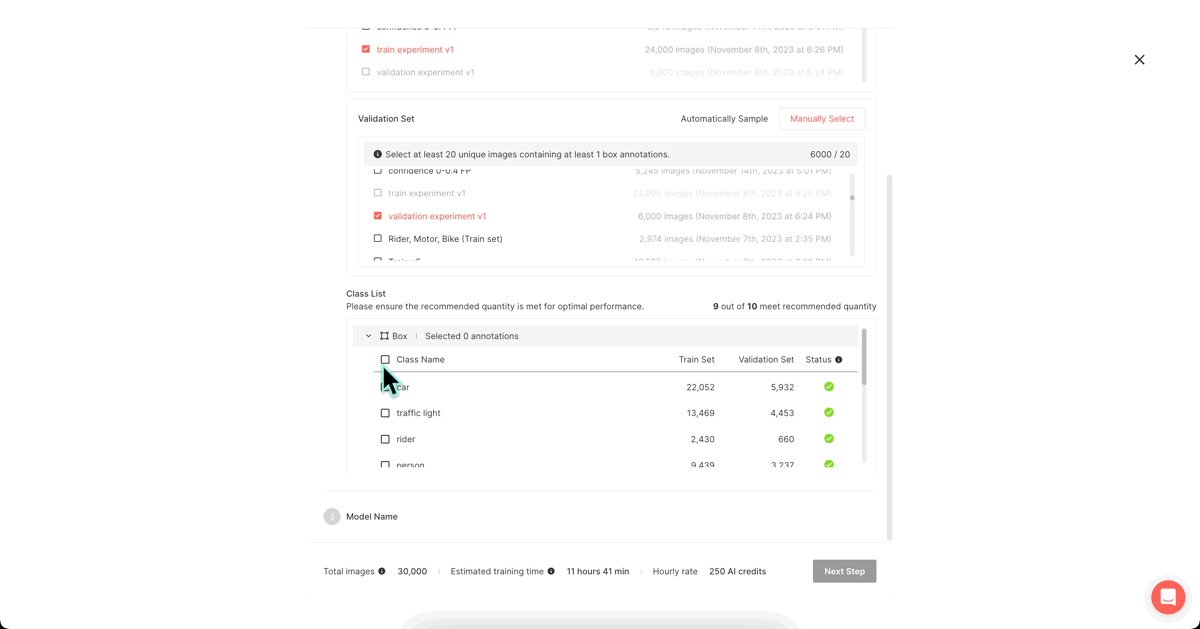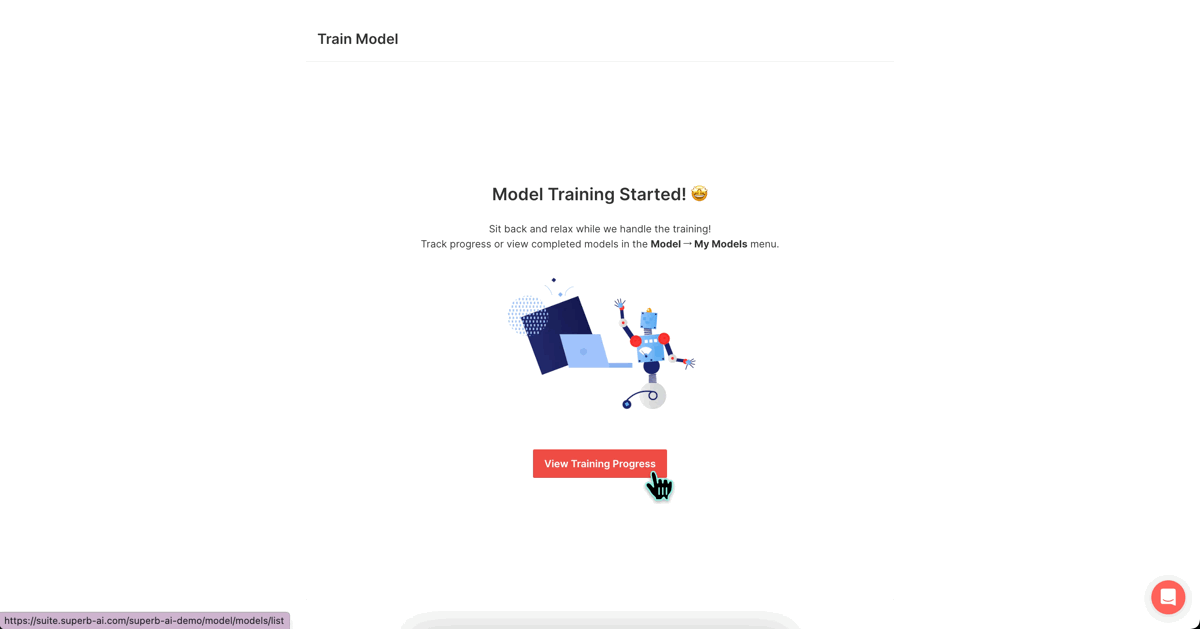
For consistency, we designated specific train and validation slices.
Training can be initiated by selecting the classes for training and naming the model. Anyone can effortlessly train a model once the dataset is designated. If you are training your model on Superb Model, it's important to note that higher performance models may require extended training times, up to 12 hours depending on the data volume.
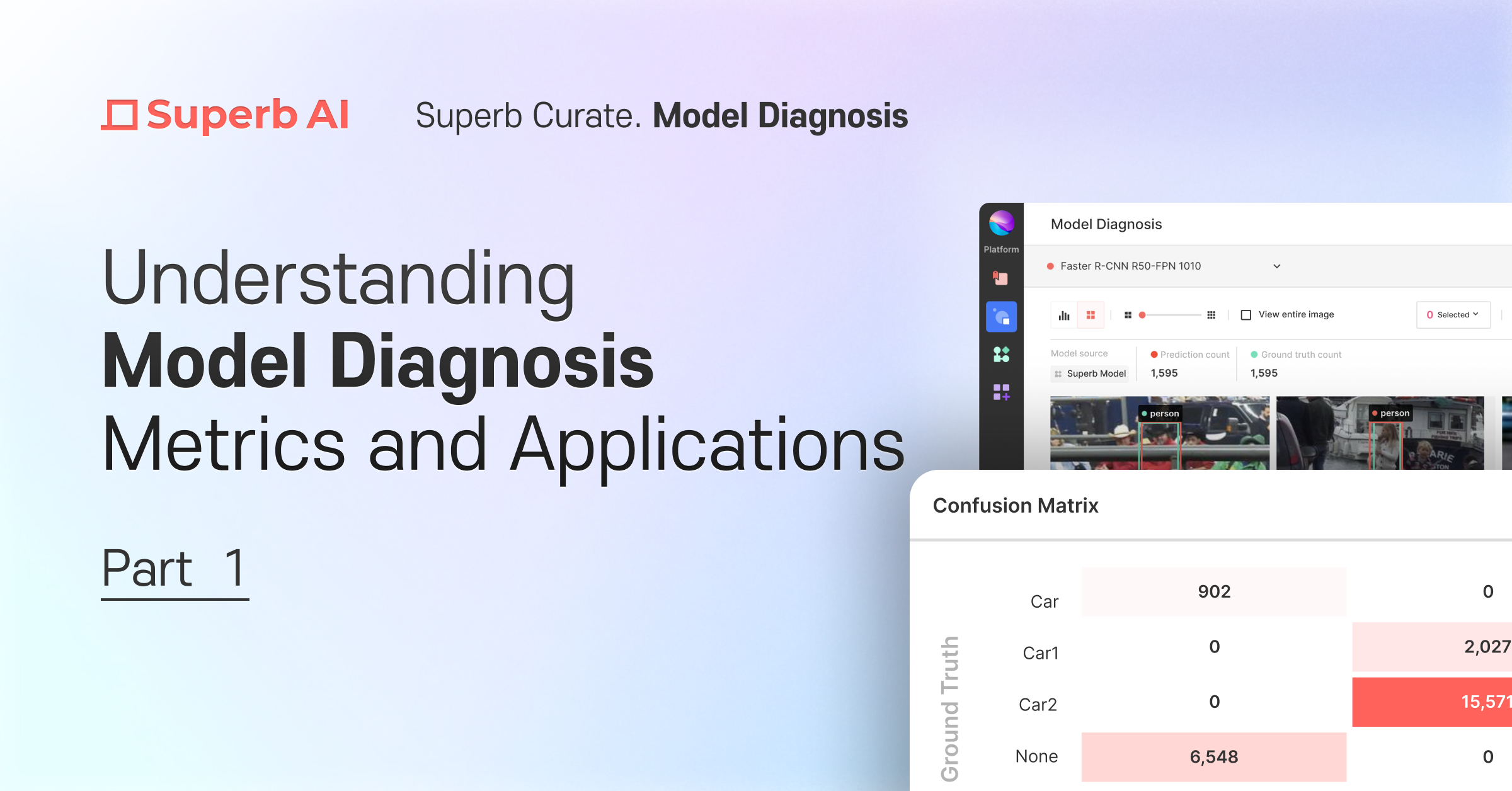
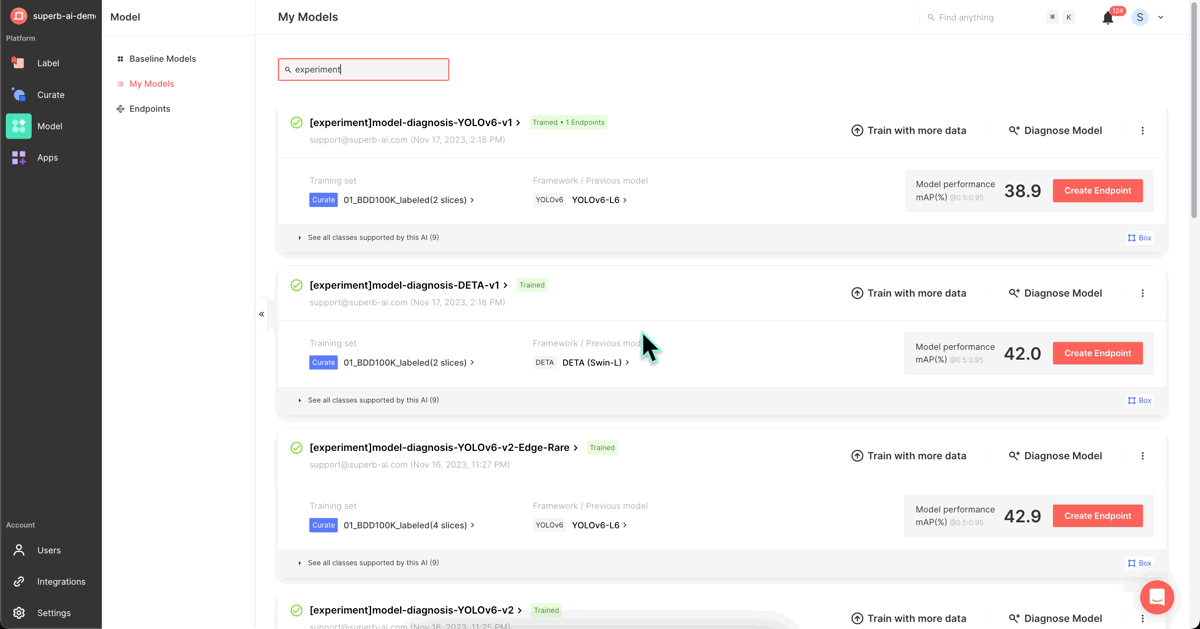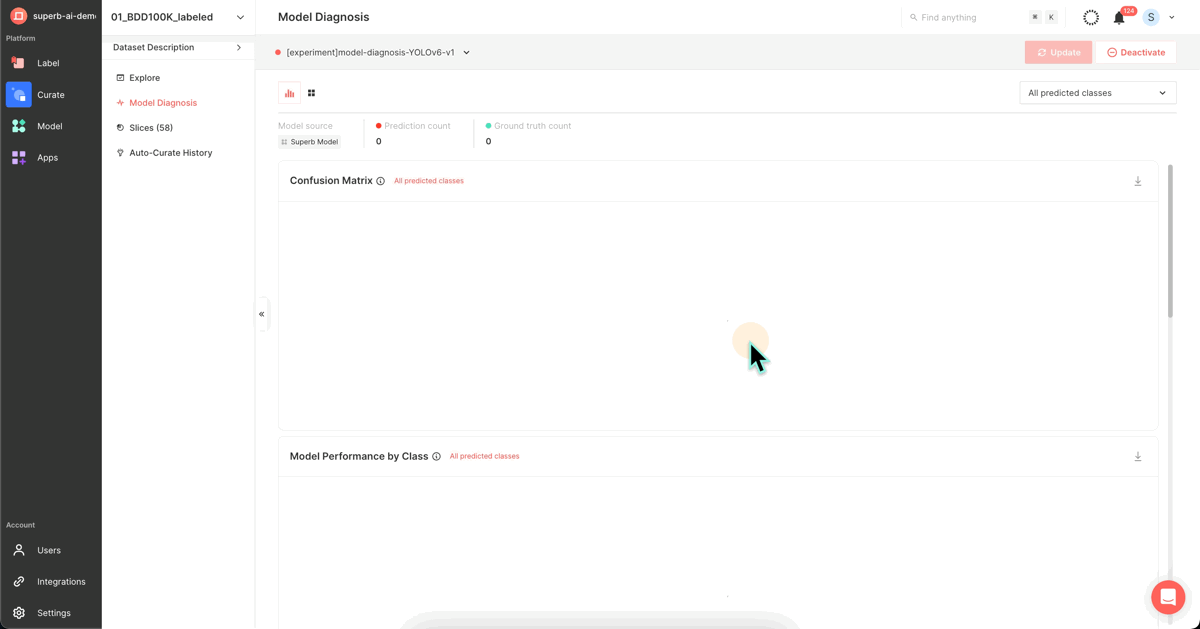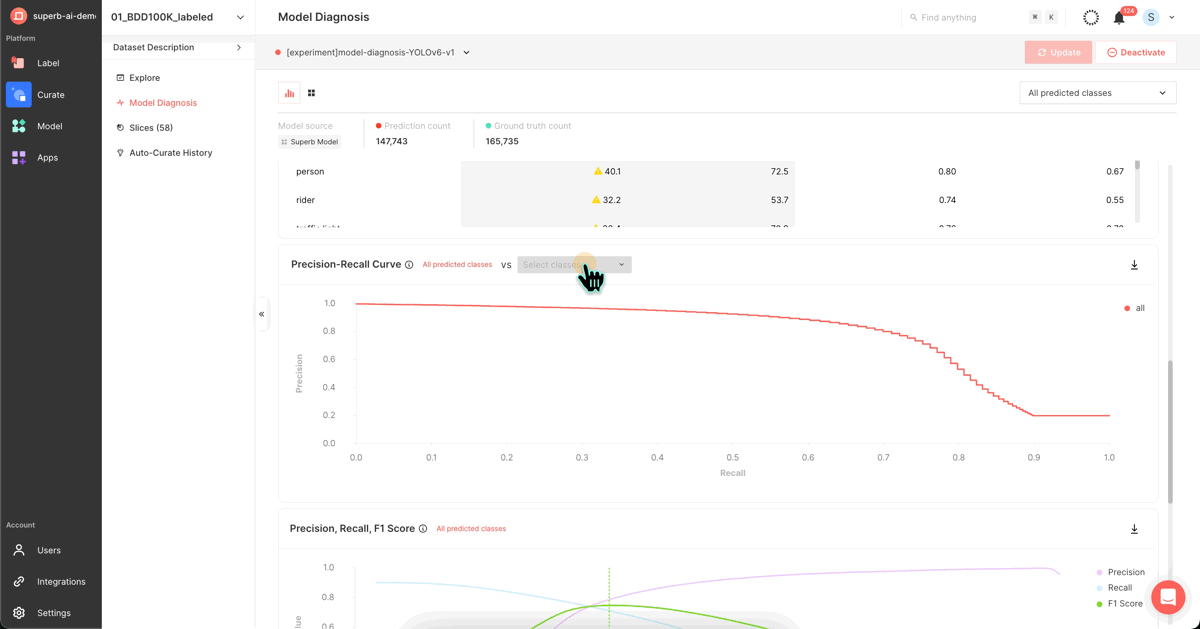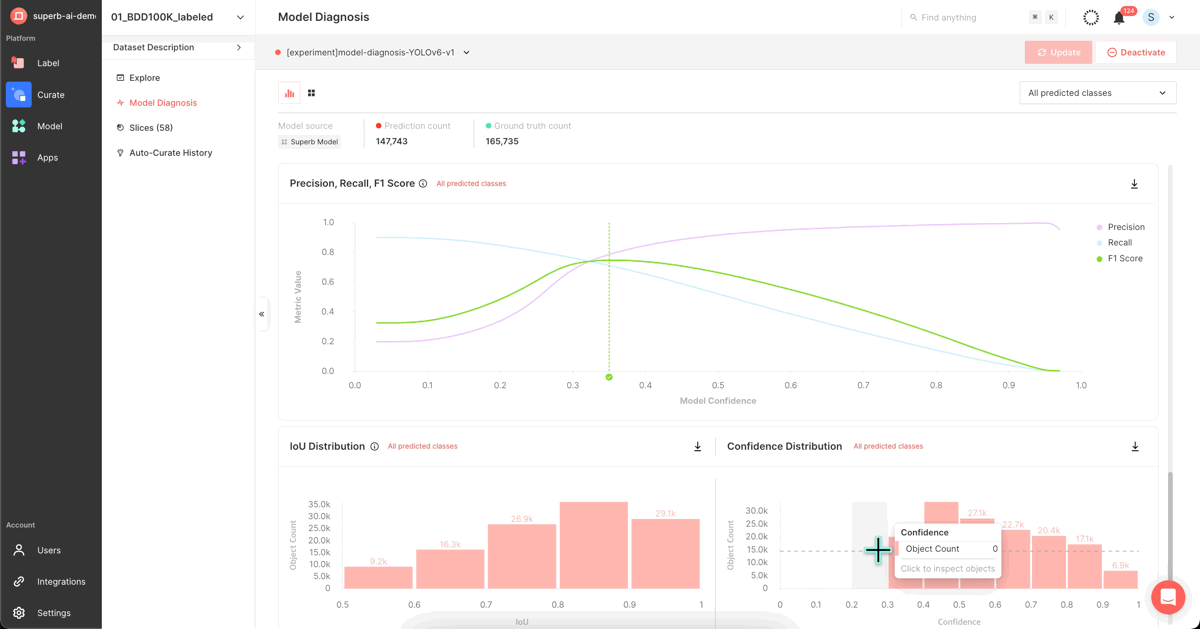
3. Model performance diagnosis
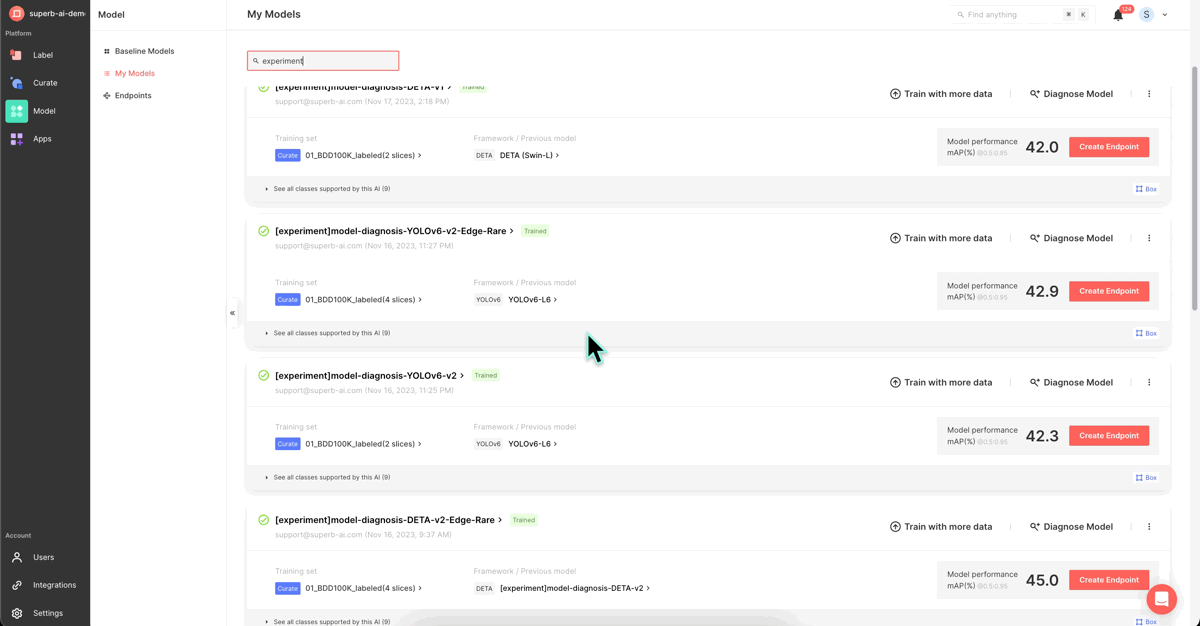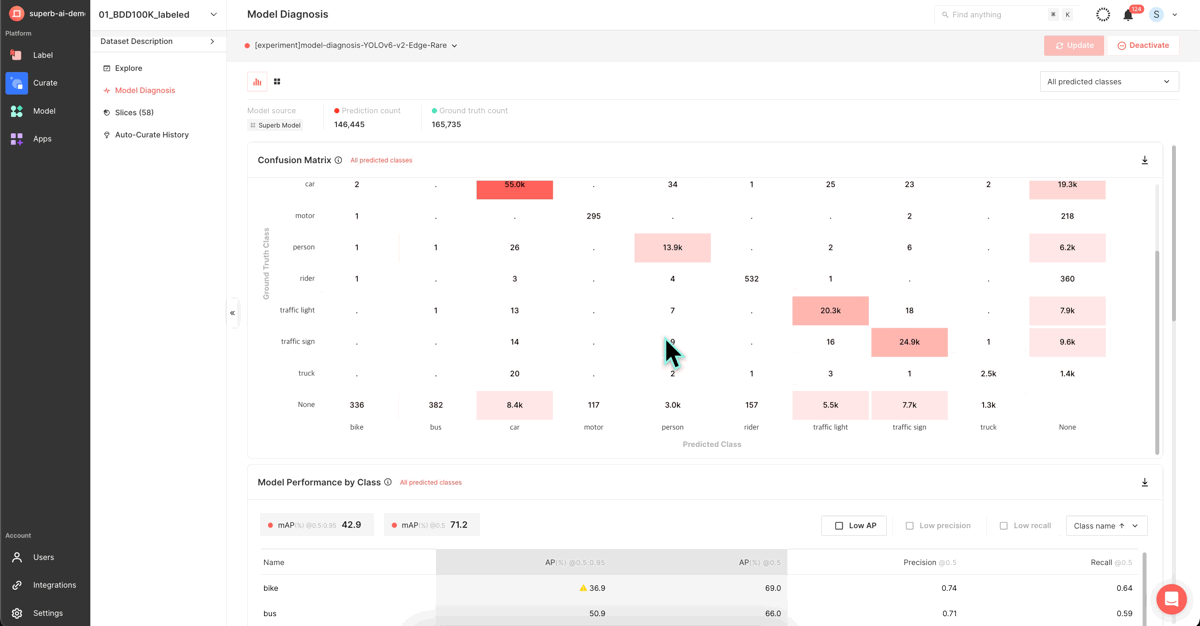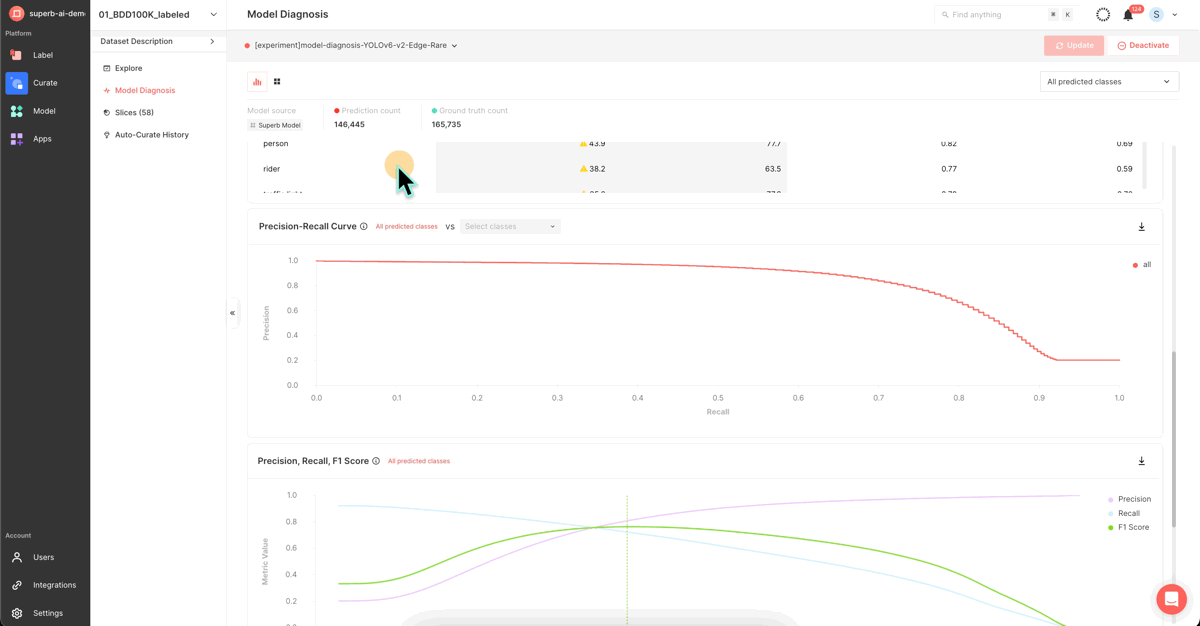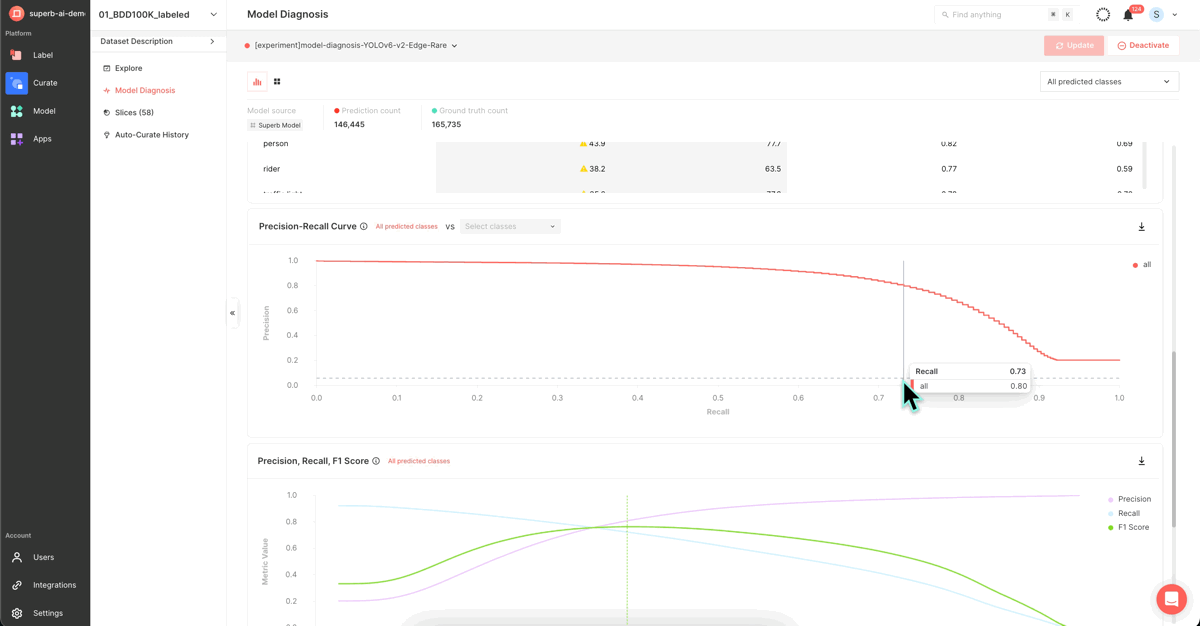
After completing the model training, you can utilize this screen to assess your trained model's performance. This page presents a variety of metrics and graphs that depict your model's performance, ranging from the widely-used mAP to PR Curve, IoU, F1 Score, Confidence, and Confusion Matrix.
4. Model vulnerability identification and improvement (using Superb Curate’s ‘Model Diagnosis’ and ‘Auto-Curate,’ and Superb Label’s ‘Labeling’ feature)
The mAP of our model, following the initial training, stood at 38.9. We will now focus on identifying vulnerabilities in our model from a data-centric perspective, rectifying poor-performing data, and enhancing the mAP score.
A quick and easy method to pinpoint vulnerable data is to use Superb Curate.
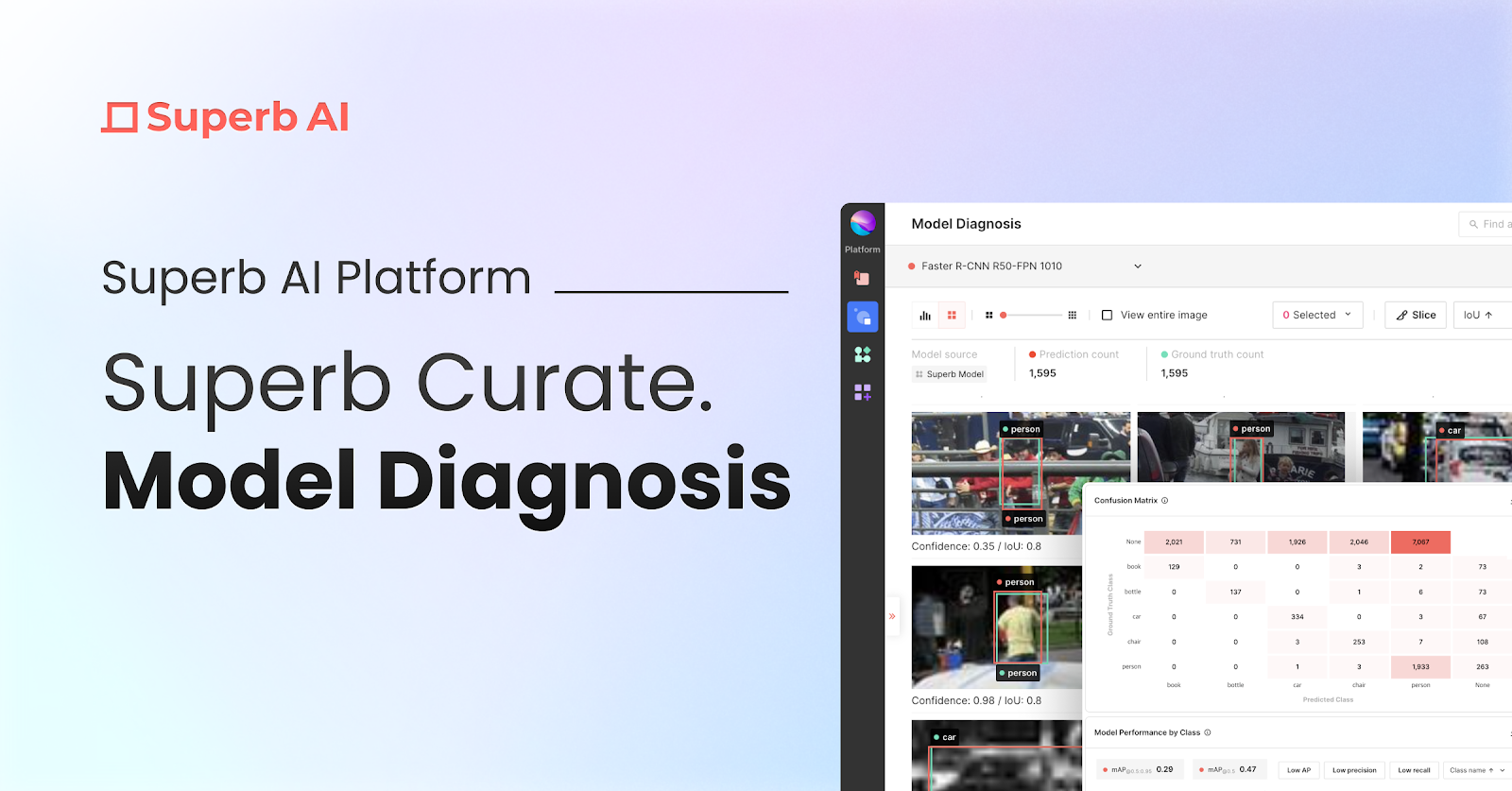
1) Using Superb Curate’s ‘Model Diagnosis’
Through Superb Platform's Grid View and Analytics View and the diverse filter options provided, you can visually identify vulnerable data, edit or augment them, and thus improve model performance. The following filter options allow you to examine the data and isolate them into a ‘slice’:
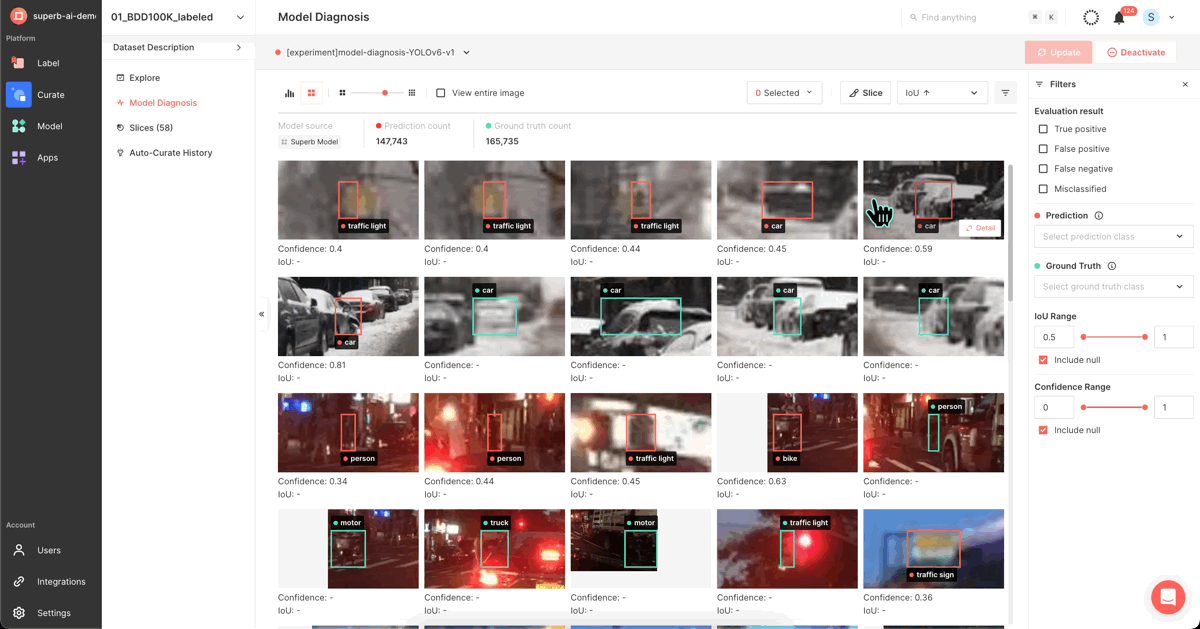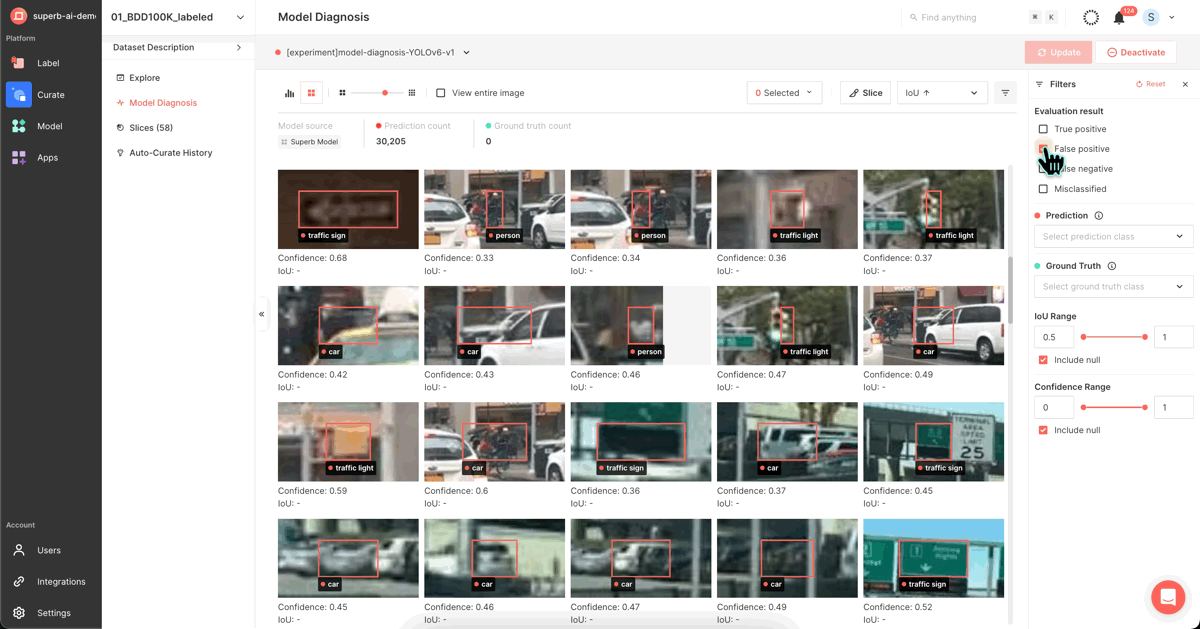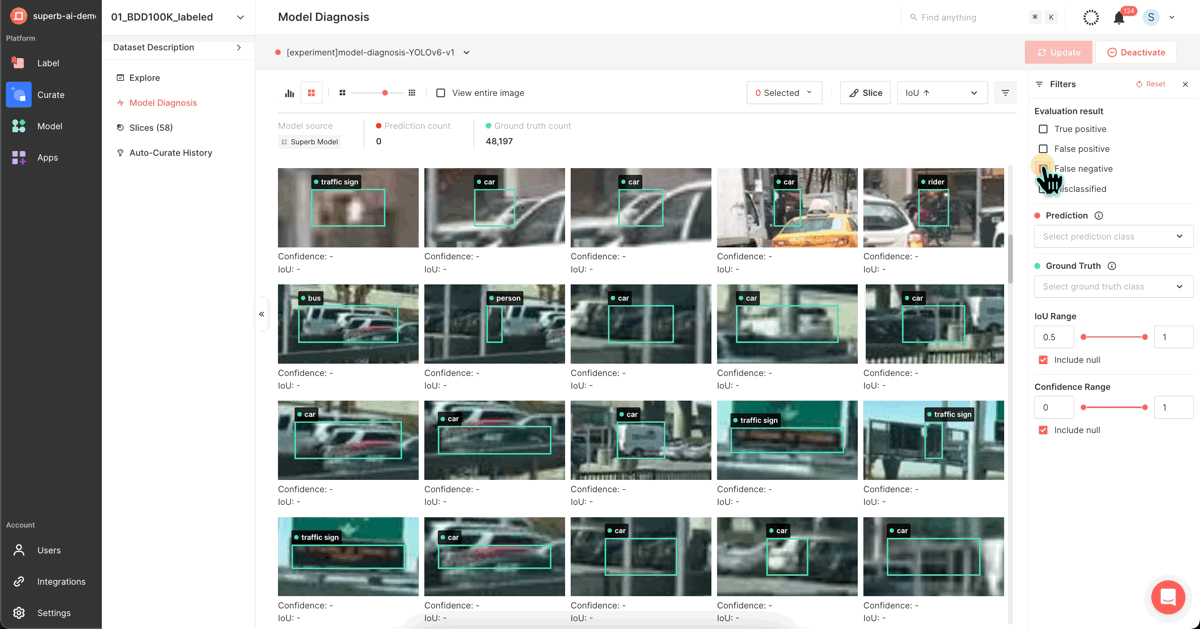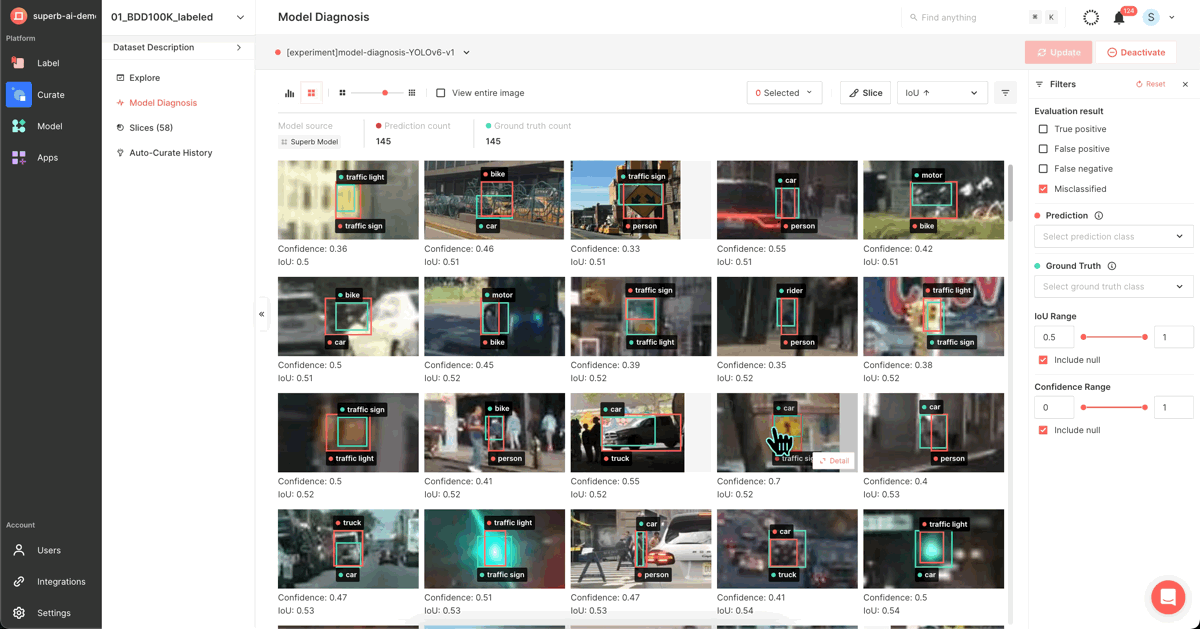
2) Using Superb Curate’s ‘Auto-Curate - mislabeled data’
Mislabeled data from the train set (Ground Truth) (=find mislabel, name: mislabel test slice)
In this experiment, we will send the slice containing II-1) mislabeled train data to Superb Label to correct labeling and use the updated data for re-training.
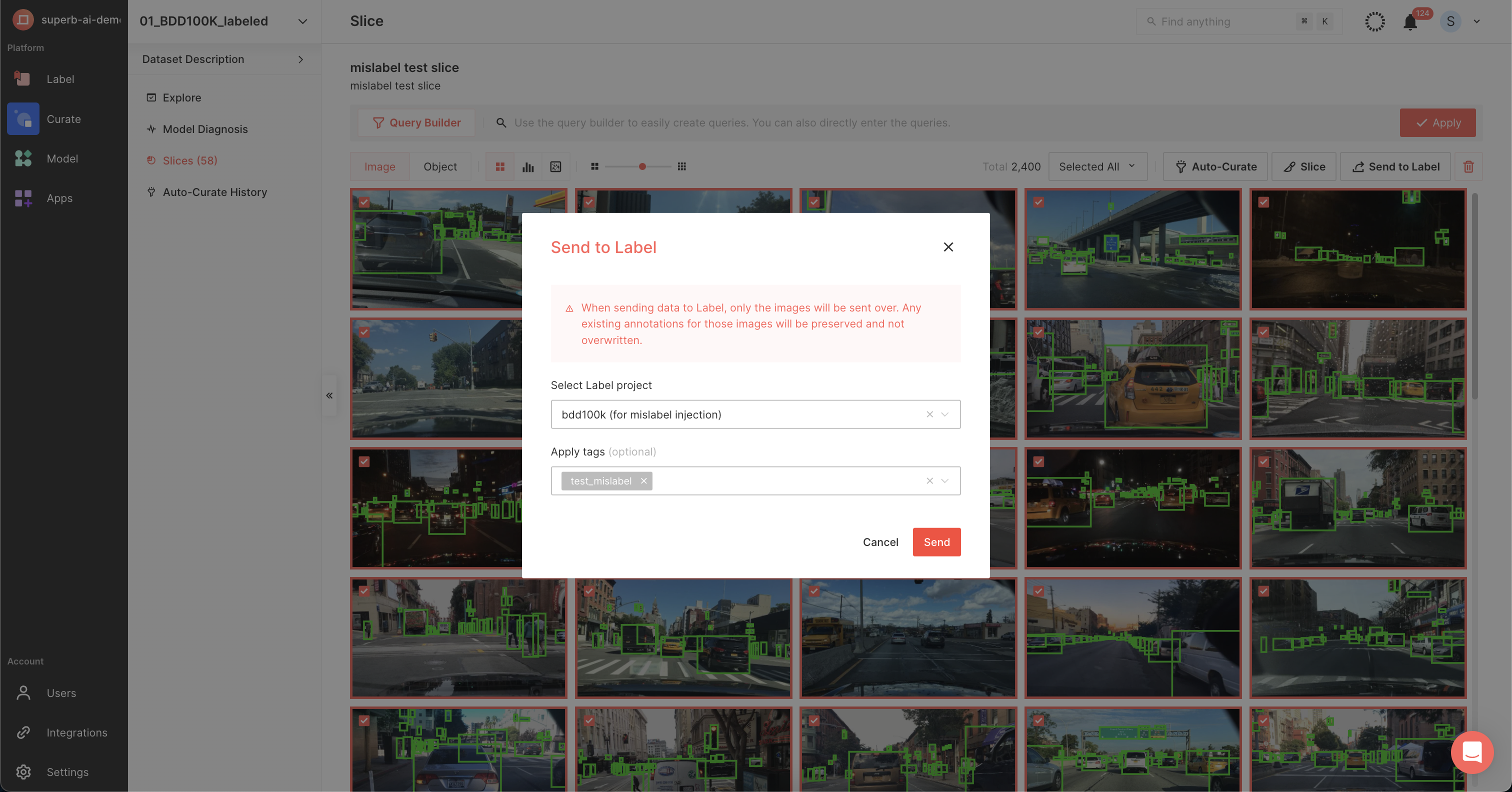
Since the model is trained with incorrect data, addressing the mislabels will lead to an increased model performance metric.
Let’s proceed to Superb Label and open the slice requiring correction.
Upon examining the actual data points, we found that ‘car’ was mislabeled as ‘traffic light,’ and ‘traffic light’ as ‘rider.’ Our objective is to identify and rectify such mislabeled Ground Truth data.
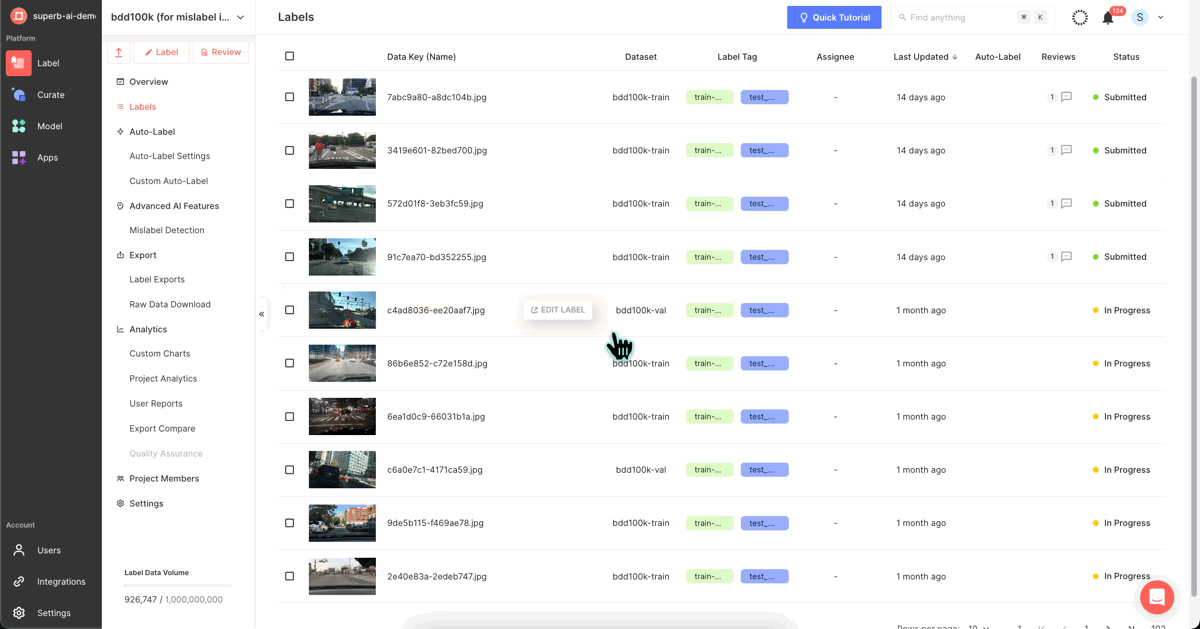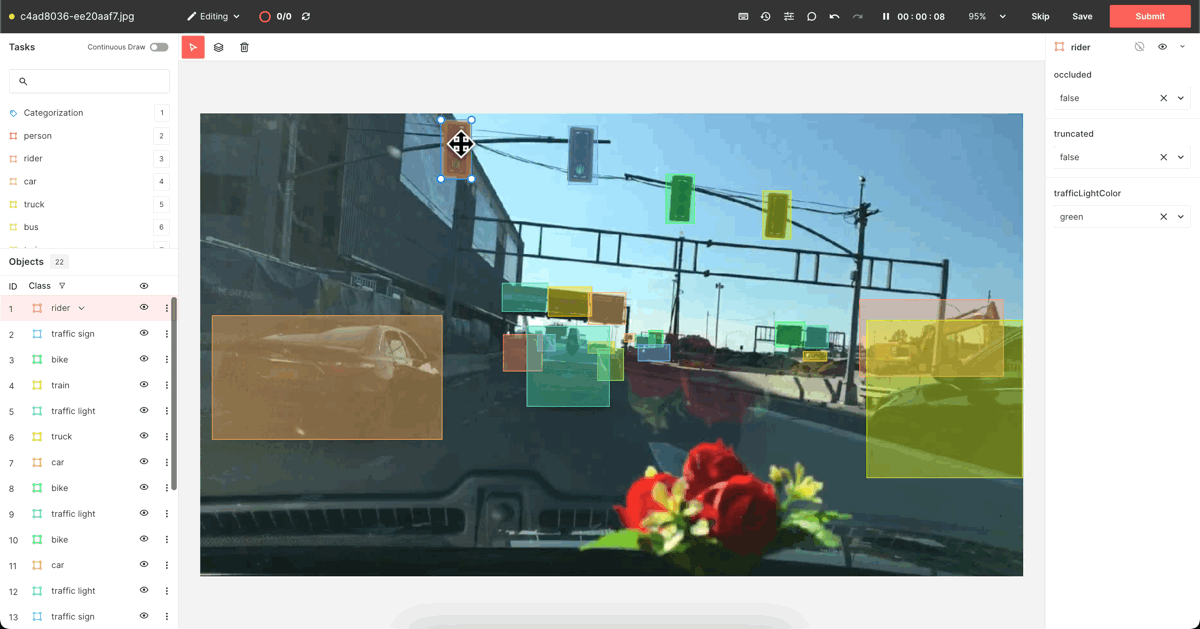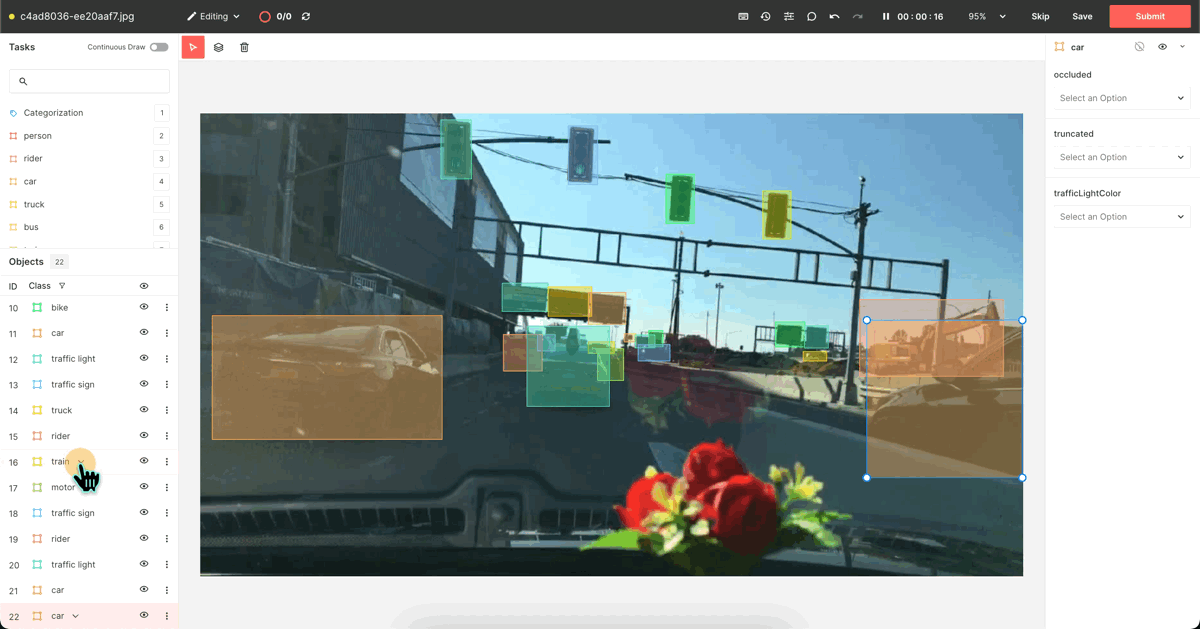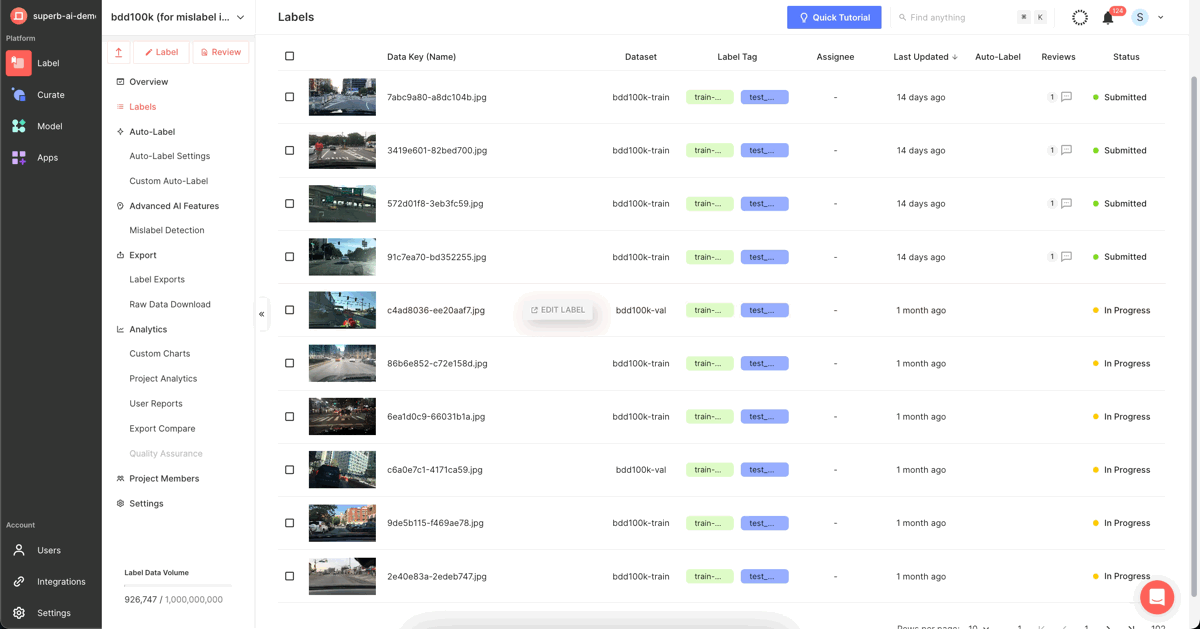
After successfully correcting all data, we will send the slice back to Superb Curate to prepare for re-training, using the “Send to Curate” feature (modified label slice).
5. Model re-training (Superb Model’s “Train with more data” feature)
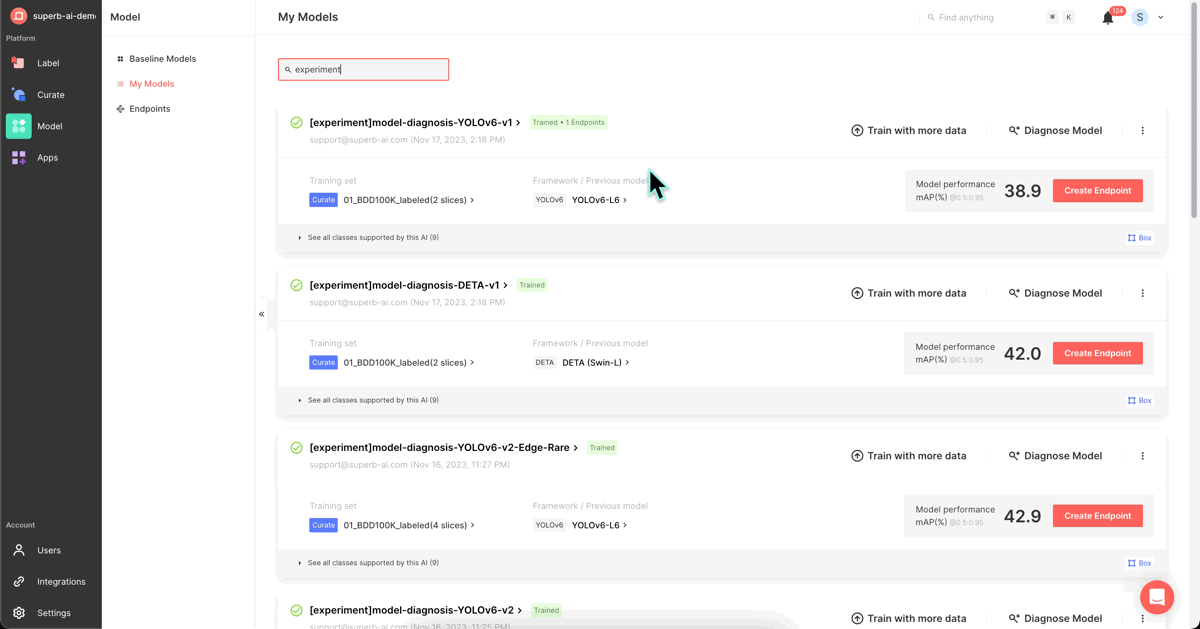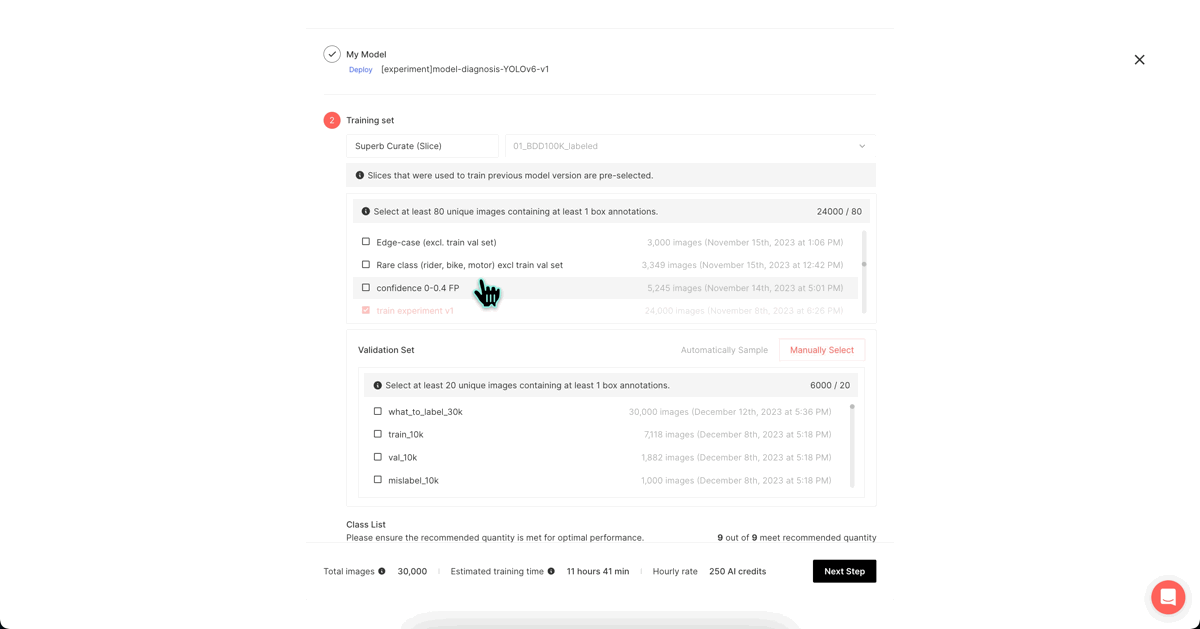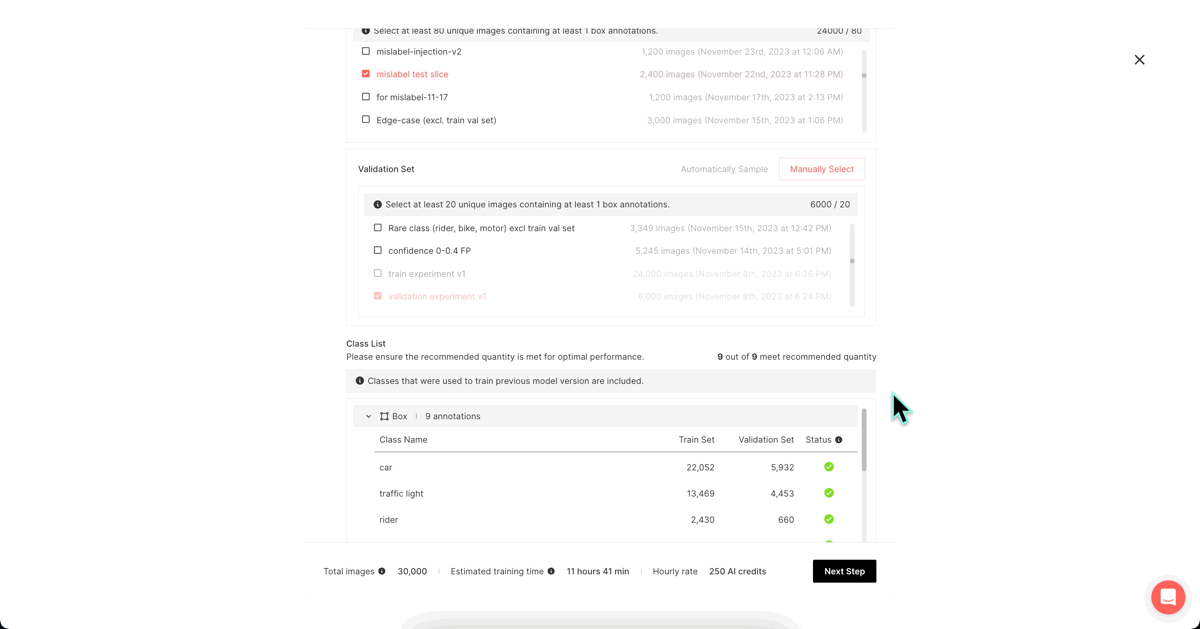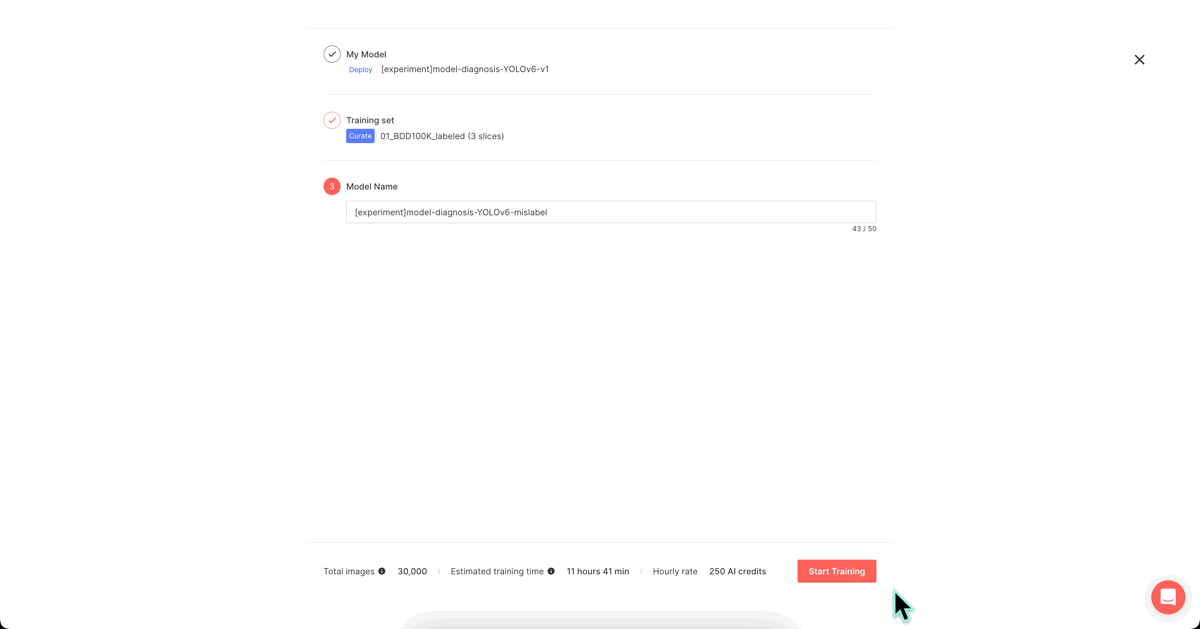
We augmented the mAP 38.9 model from Step 2 with the refined dataset from Step 4 and initiated re-training to enhance performance. (Name: [experiment]model-diagnosis-YOLOv-6v2)
6. Data augmentation for rare classes (Superb Curate’s ‘Query’ and ‘Auto-Curate - Edge Case’ features)
Following Step 5, the mAP value rose to 42.3, signaling a substantial performance improvement. To further enhance this, we can revisit the model's performance metrics.
Add more ‘rare class’ data (using Superb Curate’s ‘Query’ feature): Our analysis revealed a relative scarcity of training data for ‘bike,’ ‘motor,’ and ‘rider.’ By augmenting data for these 3 classes and re-training, we expect to further improve performance. We selected approximately 3,000 images from an unused pool of 8,000 ‘bike,’ ‘motor,’ or ‘rider’ images for this purpose and created a slice to use for additional training.
Add edge cases (using Superb Curate’s ‘Auto-Curate - Edge Case’): As an alternative approach, we can consider training the model with additional edge case data. From the unused data and those not qualifying for 6-1), we automatically selected 3,000 edge case data for further training through Auto-Curate.
7. Additional re-training, model performance diagnosis, and deployment (Superb Model’s ‘Train with more data’, Superb Curate’s ‘Model Diagnosis’)
We added the two data slices from the above steps to the training dataset using Superb Model’s ‘Train with more data’ feature and commenced additional re-training. If the mAP value rises beyond 42.3 post-retraining, it would indicate another successful performance enhancement.
The mAP value has increased from 42.3 to 42.9, marking another milestone in model performance improvement! Beyond this metric, you can analyze model performance from multiple perspectives using various performance metrics.
Visit the ‘Model Diagnosis’ feature for an intuitive understanding of the performance gap between the first version of your model (mAP 38.9) and the latest version (42.9). This feature provides insights using Confusion Matrix, PR Curve, and other diverse indicators and graphs.
Can We Opt to Change the Type of the Trained Baseline Model?
You can opt to try out other models offered In Superb Model to find the baseline model that best fits your dataset. However, it’s important to note that the data-centric approach, which involves diagnosing model performance, identifying vulnerabilities, and addressing them, remains consistent across different models. We chose the DETA (Swin-L) model from Superb Model and followed the aforementioned process. As observed, the patterns and trends in accuracy improvement are similar.

Conclusion
Excluding the time for data processing and model training, it took only 3 hours to analyze and identify model vulnerabilities, and devise solutions. With Superb Curate’s Model Diagnosis, you can quickly identify incorrectly classified data or the most frequent types of errors, minimizing the trial and error often associated with interpreting and combining performance metrics. This feature also facilitates rapid insights into performance improvement opportunities, helping you understand which data needs augmentation or correction. In other words, you can quickly determine whether performance issues stem from labeling errors, insufficient edge cases, or a lack of data for specific classes. Our experiment further demonstrates that an MLOps cycle embodying a “true data-centric approach” can be established through Model Diagnosis.
The key to building an effective MLOps pipeline is accelerating the cycle to enable as many iterations as possible. Superb Platform is designed for users to execute the entire MLOps cycle seamlessly in one integrated environment, saving time and resources that would otherwise be spent switching between different tools and platforms including external ones.
Are you experiencing problems with AI adoption and model improvement, or interested in analyzing performance changes following improvement actions?
If you wish to learn how Superb Platform can further enhance model performance, please don't hesitate to contact us. We are eager to provide you with a product demo tailored to your data and industry and to explain the benefits of the data-centric approach in more detail. We assure you, Superb Platform is the best solution for those seeking to commercialize AI models.