Insight
Active Learning 101: A Complete Guide to Higher Quality Data (Part 1)

Tyler McKean
Head of Customer Success | 2022/03/10 | 11 min read

Active learning is the secret weapon to getting better models into production, and keeping them in top shape - but one that is often underutilized or missing altogether. Part 1 of this series answers the question of: what is active learning and why it is relevant to labeling training data for computer vision applications.
Introduction
Machine learning (ML) has proven effective in automating and accelerating business processes, but building an efficient ML model is an intricate and detailed undertaking. In machine learning, there are three primary methods used by ML engineers to build a highly functional model: supervised learning, unsupervised learning, and reinforcement learning. The most popularly implemented method is through supervised learning, mainly because of its ability to emulate human behavior and actions through training data, which are used to instruct an algorithm to carry out tasks such as classification. Supervised learning, then, is the closest machines come to acting like the scientists who trained them, giving it an edge over other popular algorithms used in machine learning. The main drawback to building a machine learning model through supervised learning, however, is the dedicated time required to do so, as models require large amounts of hand-labeled data. ML practitioners often use active learning, a subset of supervised learning, to train their model to reach an acceptable performance level.
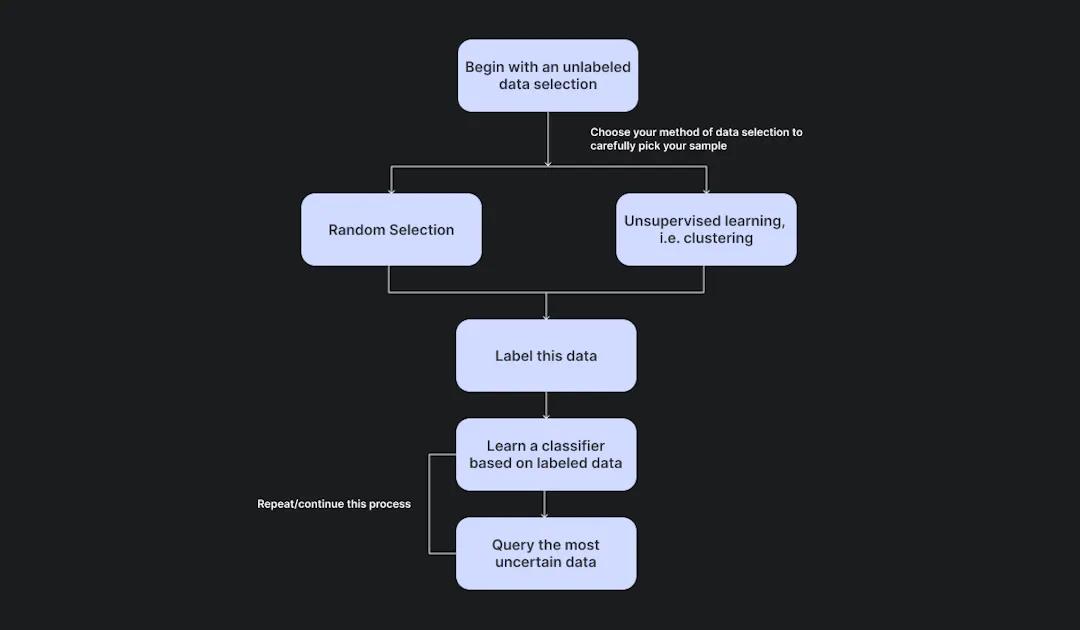
Active Learning: A Quick Overview

Active Learning workflow for Computer Vision AI Platforms
The large quantities of labeled data required in traditional supervised learning algorithms has led to slow-downs for many ML teams looking to build working models, giving way to modified and streamlined approaches such as active learning. In contrast to the large quantities of data required in conventional supervised learning models, active learning models only need a small amount of trained data to operate. In active learning, ML teams properly label a small sample of data to train their model, which in turn learns to identify specific patterns and behaviors. Through each phase of development, the model identifies any uncertainties when labeling raw data. From there, a human steps in, corrects any errors and retrains the model. This process is repeated until the model achieves its highest level of accuracy.
The human-in-the-loop component of data labeling for machine learning algorithms gives way to fatigue and error, which is why traditional supervised learning has its drawbacks. When active learning is used, a human merely steps in to guide the data to ideal performance, meaning that less data is required. As this process is repeated, your model’s performance is improved drastically over time. Through active learning, your model is taught to understand a specified outcome or behavior that is unwavering and certain. For ML practitioners looking to build a model with specific, repeated behavior, then active learning is a preferred method.
Beyond Active Learning: Different Approaches to Computer Vision
Machine Learning Algorithms
While active learning utilizes less data than other types of supervised learning, there are other approaches in which to train your model. Depending on your end goal, it is best to explore each machine learning strategy and evaluate which approach will yield the best results. In certain instances, active learning is not the best strategy for your particular model, and it is important to understand which algorithm to use instead, the differences between them, and the benefits of each.
Reinforcement Learning

Diagram of reinforced learning model for computer vision platforms
Outside of active learning and supervised learning algorithms, we have models that rely heavily on its previous action to make its next move. Think game theory and chess, or any gaming use case. Reinforcement learning is the best method in building an action-reliant model that successfully makes its own decisions. Though active learning relies on human guidance to steer a model into the correct action, reinforcement learning models rely on its own actions to modify its behavior. For example, a robot learning to walk may initially fall. Using that result as negative reinforcement, that same robot will modify its behavior until it moves seamlessly. Reinforcement learning and active learning sound similar in how they rely on previous actions, but reinforcement learning algorithms are more independent of human guidance and aren’t trained to complete a specific task but instead explore a menu of actionable options. In supervised and active learning, however, the expected outcome is defined; models are likely trained to perform object detection and classification tasks and is beneficial when a specific pattern or object identification is consistent.
Deep Learning
Deep learning, on the other hand, references existing data to make predictions outside of that dataset. It is almost entirely autonomous and works to uncover patterns in order to make those predictions. For example, if your deep learning model is fed thousands of pictures of dogs, it will take into account the general shape, size, and structure of those images. From there, it will be able to classify the images into two categories: dogs and not dogs. Based on its findings, it can then identify dogs outside of that dataset.
The benefits of each type of machine learning is entirely dependent on your project. Today, we are focusing on active learning, its subtypes, and the value it presents to machine learning practitioners
Popular Types of Active Learning
Active learning proves advantageous for machine learning practitioners who wish to forgo the process of collecting thousands of labeled datasets. Though a common sentiment is that more data = better results, it’s often the quality that trumps the overall quantity. The approach of using active learning over traditional supervised learning has granted a faster, easier, and less cost-prohibitive method of building machine learning models. But there are also different strategies for querying data within active learning that ML practitioners and data scientists must consider.
Random Sampling
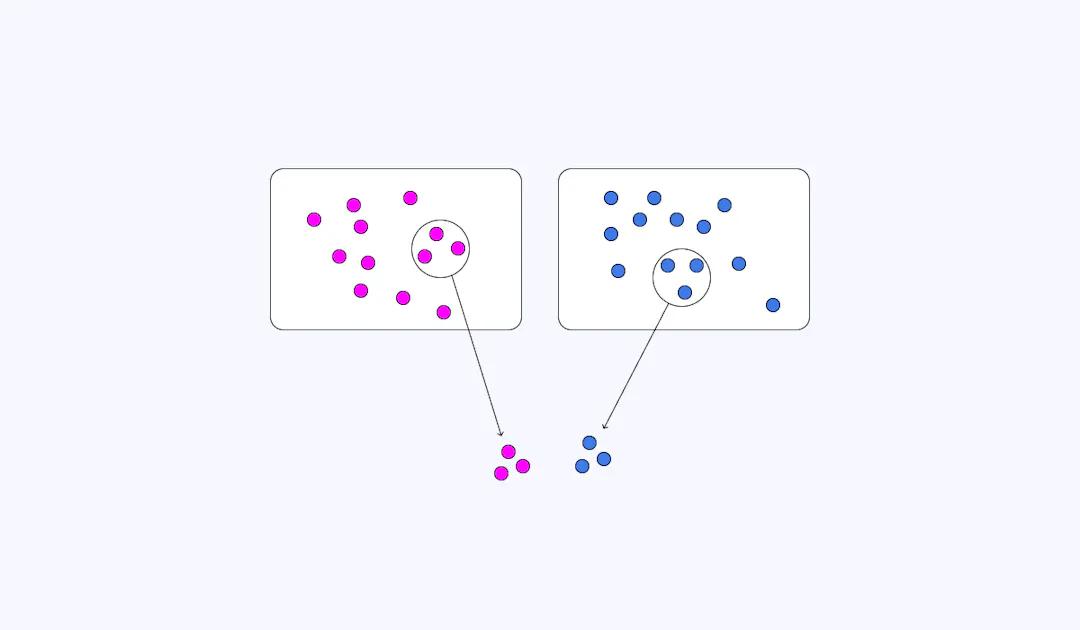
Graphic example of random sampling
Perhaps the most familiar method of data collection and sampling is through random sampling. In this practice, the data selected to be queried is chosen at random, where there is no human influence in which data are pulled for query. The idea behind this technique is to grant each piece of data an equal opportunity in being selected, so that we are presented with a true representation of our data and can avoid bias. In machine learning and elsewhere, random sampling is implemented as a strategy to learn about an entire dataset or population with only a small amount of data. One of the reasons in which random sampling is so popular among data scientists is because of its simplicity. Choosing data at random requires no knowledge of the items being researched or labeled, making it incredibly easy to implement. In addition, random sampling does not involve prior classification, thus reducing the likelihood of errors.
Pool-Based Sampling
Visual of pool-based sampling for computer vision tools.
With each active learning algorithm, the machine oversees some unlabeled data, which it then queries a human to QA. From here, the person can adjust the labeling parameters and make any changes based on predictions made by the machine. In pool-based sampling, the machine uses informativeness, meaning that the data contains valuable information and should be labeled. When measuring informativeness, we look at how useful the data is and determine which examples should be included in training our model. After a pool of data is selected for labeling, ML professionals will choose to train a portion of it, typically 80%, and then validate the remaining 20%. In this approach, it is paramount to understand which examples yield the lowest prediction precision value, as that data will help improve performance. In other words, the images with the lowest levels of accuracy can be used to help train your model in the future. From here the training data is used to run through the remaining images in the model and measure the precision value of each image. By identifying the lowest performing image sets, we can then use our trained data to make any corrections, thus improving our model.
Stream-Based Selective Sampling
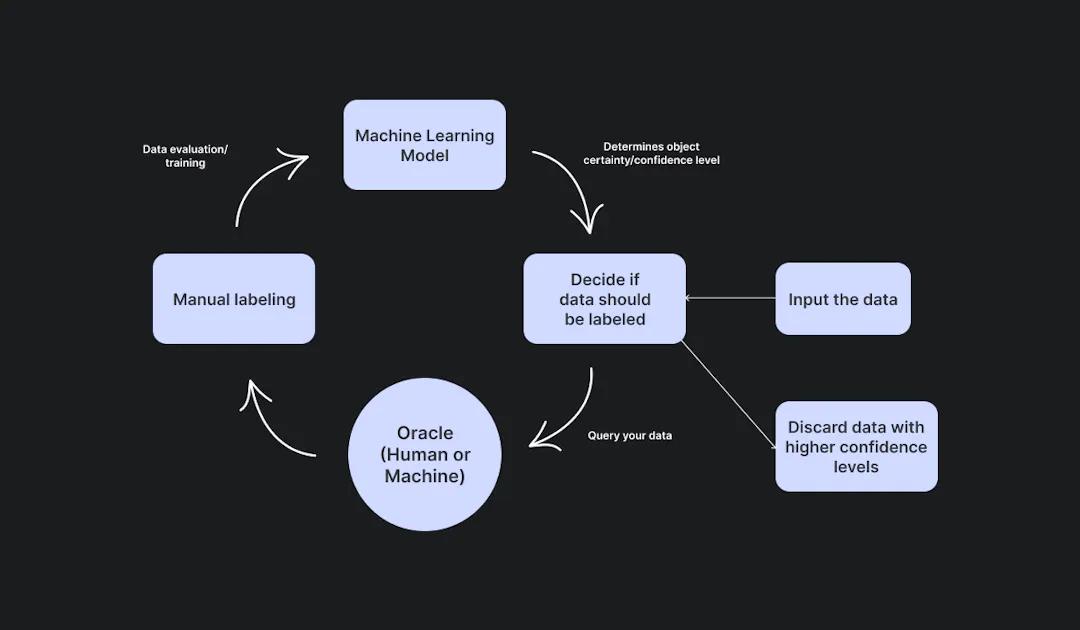
Diagram of stream-based selective sampling for computer vision tools
Stream-based selective sampling relies on your model’s confidence level to determine which pieces of data should be labeled. In this method, our human annotator, or oracle, labels a small dataset for training purposes. Then, your model evaluates the remaining data, one by one, and determines if it should be labeled. In this part of the process, your model utilizes a confidence threshold to determine its certainty of each object in an image. If its confidence is lower, your model is more likely to pull it for labeling. Stream-based selective sampling is a thorough and autonomous alternative to methods like pool-based sampling, which requires more human involvement. In comparison to random sampling, this approach is more meticulous. However, it is more time-intensive, and if your organization is using an outside service for data labeling, it can be more costly.
Membership-Query Synthesis
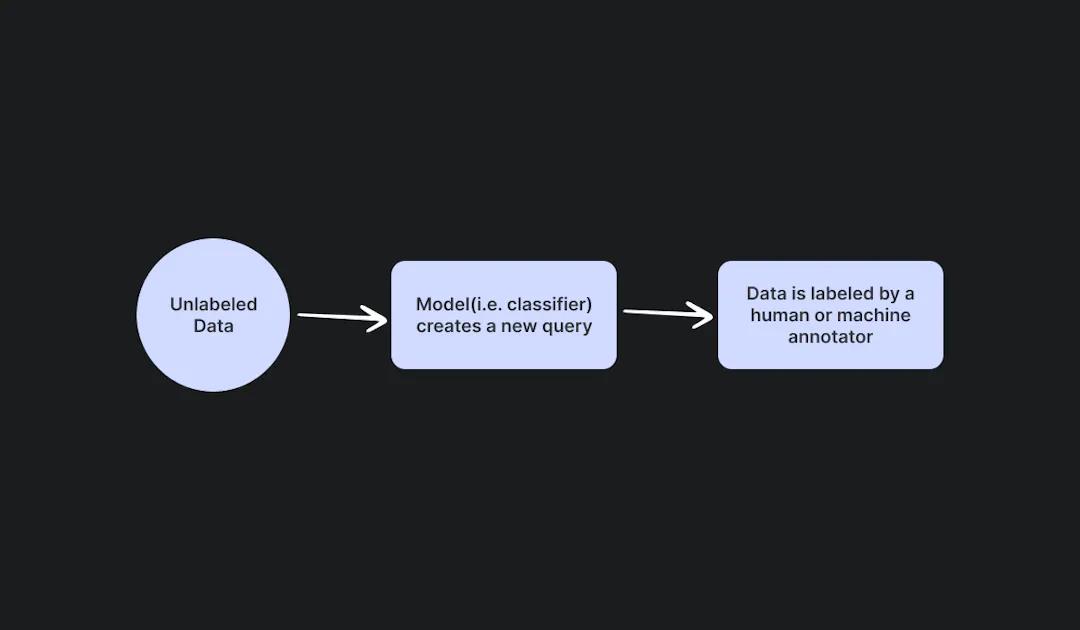
Diagram of membership-query synthesis for computer vision tools
Each active learning approach serves a different purpose in regards to the data being labeled. In membership-query synthesis, our model reuses training data to form its own examples. Here, data augmentation is often utilized to alter certain images and gain a better understanding of different perspectives. A prime example is if our model is being trained to identify certain street signs in all types of climate and weather but the data we have is limited. In a particularly cloudy environment, for example, collecting data that shows sunshine proves challenging, so our ML professionals would use a simple brightening tool to “trick” our model into thinking it’s being shown an image in a sunny climate. In another instance, our model might be swimming in far-away shots of street lights but lack those that are closeup. Here, we could crop some of our images and retrain the model on the image’s new perspective. Membership-query synthesis was developed as an active learning tool to compensate when data is limited. Rather than investing in additional data collection, membership-query synthesis makes use of what is already available.
Diminishing returns

Graphic example of diminishing returns in active learning.
The aforementioned active learning frameworks provide ML engineers with a fast, and cost-effective alternative to traditional manual labeling. In traditional annotation practices, the notion that labeling inaccuracies are best solved with additional data was a popular belief that has since been reexamined. As evidence has come to find, additional data only improves a model’s accuracy in identifying the type of image sets that have been added, not necessarily its outliers. This notion is known as diminishing returns. Active learning works to understand which data are needed to improve model performance, concentrating on the quality of the data rather than its quantity. By reducing the overall volume of data needed to build a model, we are simultaneously increasing efficiency and decreasing cost.
Data Drift and Concept Drift
Additionally, ML engineers must account for the degradation of model performance and accuracy over time in what is known as model drift. There are different subsets of model drift that one must consider. Data drift, for example, is a phenomenon that describes the obsolescence of data usefulness as outside factors change. Your model then must account for the continuous changes that take place in the real world, such as season, weather, or consumer demand. Another concern is concept drift, meaning that the model’s target variable alters with time. For example, a self-driving model must account for the changes in car manufacturing and design year over year. Supplying a model with images of older cars and current vehicles fails to account for new designs that inevitably become a staple in everyday encounters. So, machine learning experts need to be diligent in ensuring that datasets are continuously updated and adapt to the changes in real world behavior. For this reason, automation in machine learning algorithms is a major tool in helping computer vision models remain accurate. To combat this challenge, ML specialists turn to active learning algorithms to keep their model updated.
Outliers: What They are and How You Handle Them
As what has been described in instances of model drift, it’s evident that the quality of your data contributes the most value to your model. When data is collected, there are often outliers that show extreme value examples and skew your model’s estimates. Outliers, and how a model treats them, can drastically affect its outcome and predictions. In some instances, outliers are obvious errors within a dataset and must be removed before training, while others are possible values and need to be considered. For example, if a model is being trained to predict the average hourly wage of fast food workers, a negative number would be an obvious error. Because the value is noticeably incorrect, it’s safe to remove. Conversely, if a value in this same dataset reads $25, we can assume that it is a high wage estimate and therefore must keep it as part of the dataset, however, it must still be addressed.
When outliers are present, disregarding their values negatively affects model performance. Ignoring erroneous values as well as outliers teaches your model to consider them and their patterns, forcing the data to be less than accurate. When handling outliers such as the one described above, it’s important to consider how it affects the overall model and which methods to use to address it. With larger datasets, outliers are more likely to exist, and therefore replacing them is an option. In our previous example, let’s say the closest value to our outlier of $25 is $15. One might replace $25 with $15 to not offset the other values in a process referred to as clipping or winsorizing. If we consider the incorrect negative value that also made its way into this dataset, we might implement a strategy known as imputing. Here, we would replace this value with one that is evidently missing. Ignoring, or improperly handling outliers, gives way to a failing model.
How Active Learning Can Benefit Your Business
Addressing inaccuracies and model drift are only a small part of building a working computer vision model. Data labeling itself is quite incommodious and sets many data scientists back in their projects, but it’s also one of the most important aspects. When choosing a data labeling strategy and an algorithm that works best with your model, active learning has proven to be one of the most efficient and effective approaches.
By choosing active learning for your model, there are many advantageous benefits in doing so. For one, it’s less costly and time-consuming for machine learning practitioners. Alternative methods, such as manual labeling, require large teams that are often outsourced. In these instances, different strategies and methods for labeling are common, meaning that the labeling process is ununiformed and prone to error. By choosing an active learning method, these challenges are easily avoided. Additionally, active learning provides much faster feedback on model performance than other ML techniques. This is due to the process itself. Because active learning requires frequent training as part of data labeling, it is possible to correct issues as they come up. In other methods, training happens after data annotation, so any problems are left undiscovered until much later. Because active learning seeks out hard-to-label examples, it identifies more difficult patterns and learns their patterns, actually boosting the performance of your model.
The Challenges in Implementing Active Learning
Active learning has proven to be a favorable machine learning algorithm for many data scientists, but not every outfit is equipped for it. In alternative practices, data labeling and model training are separate entities, but active learning calls for everything to be done together. Therefore, most projects lack the tools and software needed to execute active learning models. Many model training softwares require training data to be completely labeled beforehand, rendering active learning impossible. And this is difficult to modify. You would need to have a communication channel between annotators and your model while teaching it to auto-update.
In addition, to adapt your model to active learning, your team would need to annotate small buckets of data at one time before feeding it to your model. On top of this, many deep learning models are slow to update, so the process is much slower than having approached your project in a traditional way. What’s more, the advantages of using less data in an active learning model is often counteracted by the volume of annotations required over time. While an active learning model can be implemented with fewer data, it must be retrained frequently and with larger datasets; this means that the initial saving in labeling time isn’t grounds for the increase in training time.
Furthermore, maintaining an active learning model is ops-heavy and highly involved. In general, machine learning models must be preserved and updated, but with active learning, both your model and data loops require regular maintenance. ML professionals need to not only track labeling progress, but they must also version each label. This leaves heavy responsibility on both ML scientists and ML engineers, who are left in charge of data pipelines.
Why Active Learning is a Data Labeler’s Biggest Ally
For data labeling teams, understanding active learning is paramount in deciding the correct approach for a project. Active learning is something to be considered because of its ability to reduce the time spent on annotation, relieve common backlogs, and achieve project goals more accurately and in less time. Using data labeling software equipped for active learning bridges the gap between manual labeling and automation. Tools that emphasize the benefits of automation give way to a more reliable model and an easier approach to addressing outliers, inaccuracies, and data drift.
For machine learning practitioners, active learning algorithms can prove to be a beneficial approach to many projects. Minimizing the data labeling process, reducing costs, and increasing accuracy are just a few of the benefits of active learning. But it isn’t always possible to adopt these techniques with some of the current technology. Switching to easy-to-use software can combat these challenges and address some of the struggles your team may be facing. At Superb AI, we specialize in simplifying data labeling for active learning workflows with tools like our Custom Auto-Label and our patented Uncertainty Estimation tool. To learn more, tune into our upcoming webinars: Ai4 Technical Summit on March 10th and How to Improve Computer Vision with Advanced Active Learning on March 15th. And be on the lookout for future blog posts in our Active Learning 101 series, as we’ll cover everything from uncertainty sampling and variance reduction to setting up an active learning workflow for labeling automation, on top of a whole host of best practices and real-world examples. You won't want to miss it!
Related Posts

Insight
⑪ Germany's Physical AI Moment: Siemens, BMW, and the Robot Unicorn Counteroffensive

Hyun Kim
Co-Founder & CEO | 15 min read

Insight
⑩ Big Tech Physical AI Trends (2): Tesla vs. Amazon Strategy Breakdown
Hyun Kim
Co-Founder & CEO | 10 min read

Insight
⑨ Big Tech Physical AI Trends (1): NVIDIA vs. Google Strategy Breakdown
Hyun Kim
Co-Founder & CEO | 7 min read

About Superb AI
Superb AI is an enterprise-level training data platform that is reinventing the way ML teams manage and deliver training data within organizations. Launched in 2018, the Superb AI Suite provides a unique blend of automation, collaboration and plug-and-play modularity, helping teams drastically reduce the time it takes to prepare high quality training datasets. If you want to experience the transformation, sign up for free today.