Product
Developing Data-Centric AI Applications with Superb AI Suite and Pachyderm Hub

2021/08/04 | 4 min read
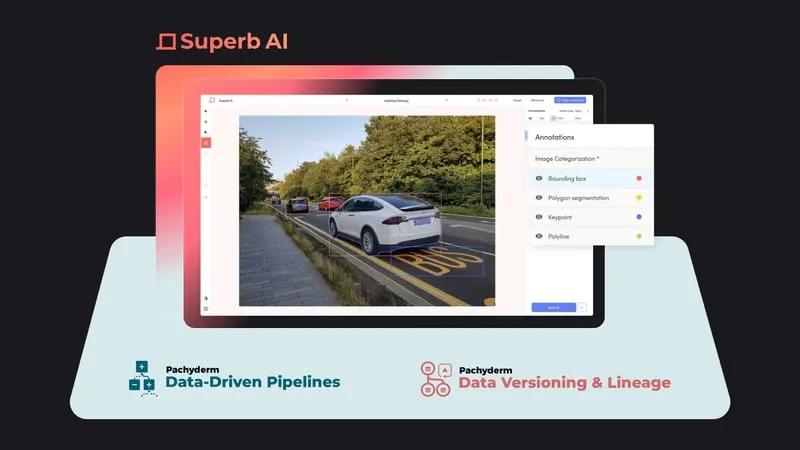
Data has become the new source code, and we need a way to manage it.
Data is so important that many of the leading practitioners in AI are pushing for data to be at the center of the ML workflow. For many years, code has been at the center of software development. And we have developed amazing tools and processes to create great software, becoming more agile and effective. But today, with the upsurging of machine learning software, curating the right data for machine learning applications is the most crucial element. Without tools and processes to develop datasets, we can’t create models with real-world impact.
The management of these stages is anything but trivial. Selecting data sources, generating labels, retraining models, all of these are key components in the data curation lifecycle, and we typically perform them in an ad-hoc fashion. So what can we do to keep our efforts from snowballing out of control?
We need a data-centric approach. We need tooling to support data development.
In this blog, we’re combining two key tools to improve the data-centric operations: Superb AI Suite and Pachyderm Hub. Together these two tools bring data labeling and data versioning to your data operations workflow.
Superb AI Suite: Labeled Data At Scale
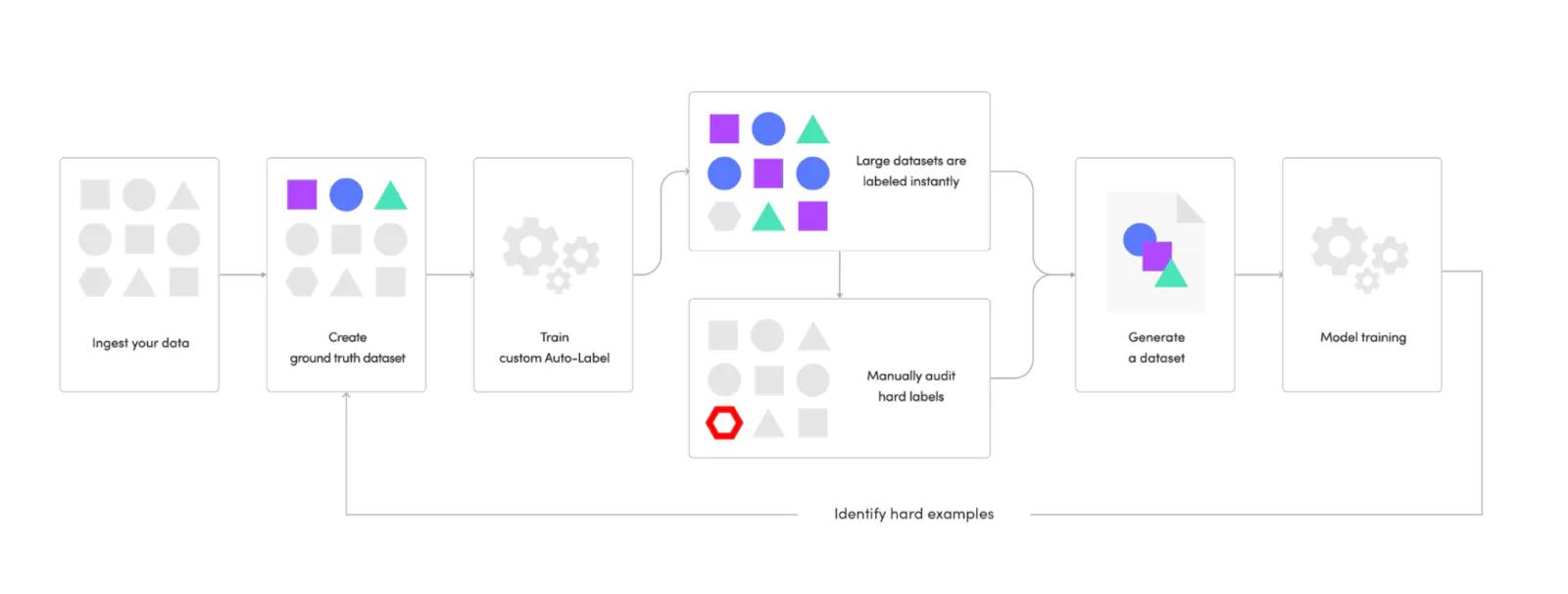
Superb AI has introduced a revolutionary way for ML teams to drastically decrease the time it takes to deliver high-quality training datasets. Instead of relying on human labelers for a majority of the data preparation workflow, teams can now implement a much more time- and cost-efficient pipeline with the Superb AI Suite.
Superb’s ML-first approach to labeling looks like the diagram above:
- You first ingest all raw collected data into the Suite platform and label just a few images.
- Then you train Suite’s CAL function (custom auto-label) in under an hour without any custom engineering work.
- Once that's done, you can apply the trained model to the remainder of your dataset to instantly label them.
- Superb AI’s CAL model will also tell you which images need to be manually audited along with the model predictions using patented Uncertainty Estimation methods.
- Once you finish auditing and validating the small number of hard labels, you are ready to deliver the training data.
- Then, the ML teams train a model and get back to you with a request for more data.
If your model is low-performing, you need a new data set to augment your existing ground-truth dataset. Next, you run them to your pre-trained model and upload the model predictions into our platform. Then, Suite will help you find and re-label the failure cases. Finally, you can train Suite auto-label on these edge cases to drive performance up.
This cycle repeats over and over again. With each iteration, your model will cover more and more edge cases.
Key capabilities:
- Create a small amount of initial ground-truth data quickly to kickstart the labeling process
- Swiftly jump-start any labeling project with customizable auto-label technology that can adapt to your specific datasets
- Streamline auditing and validation workflow by using patented Uncertainty Estimation AI that quickly identifies hard examples for review
You can try this out for free with Superb AI Suite.
Pachyderm: Versioned Data + Automation
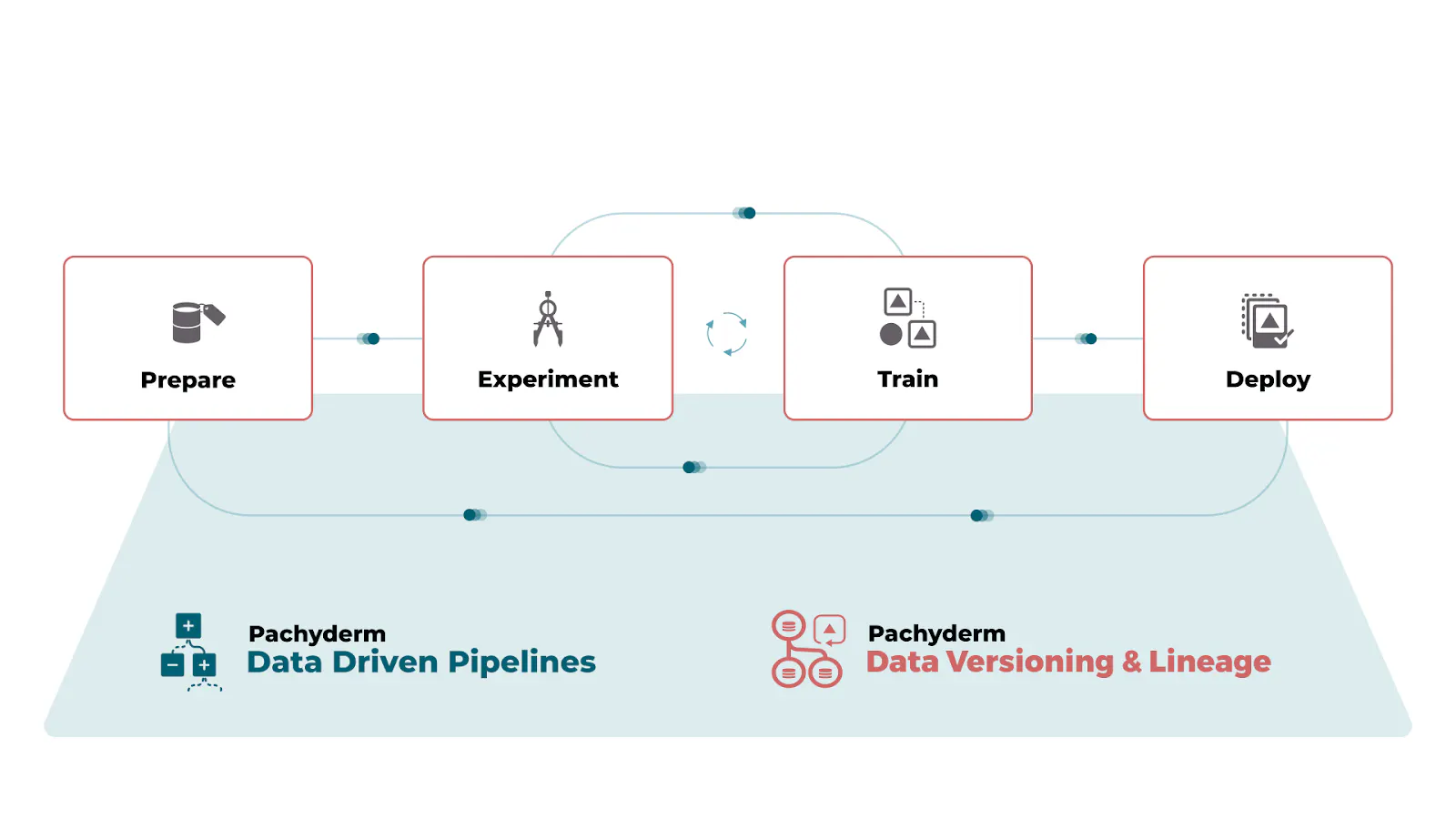
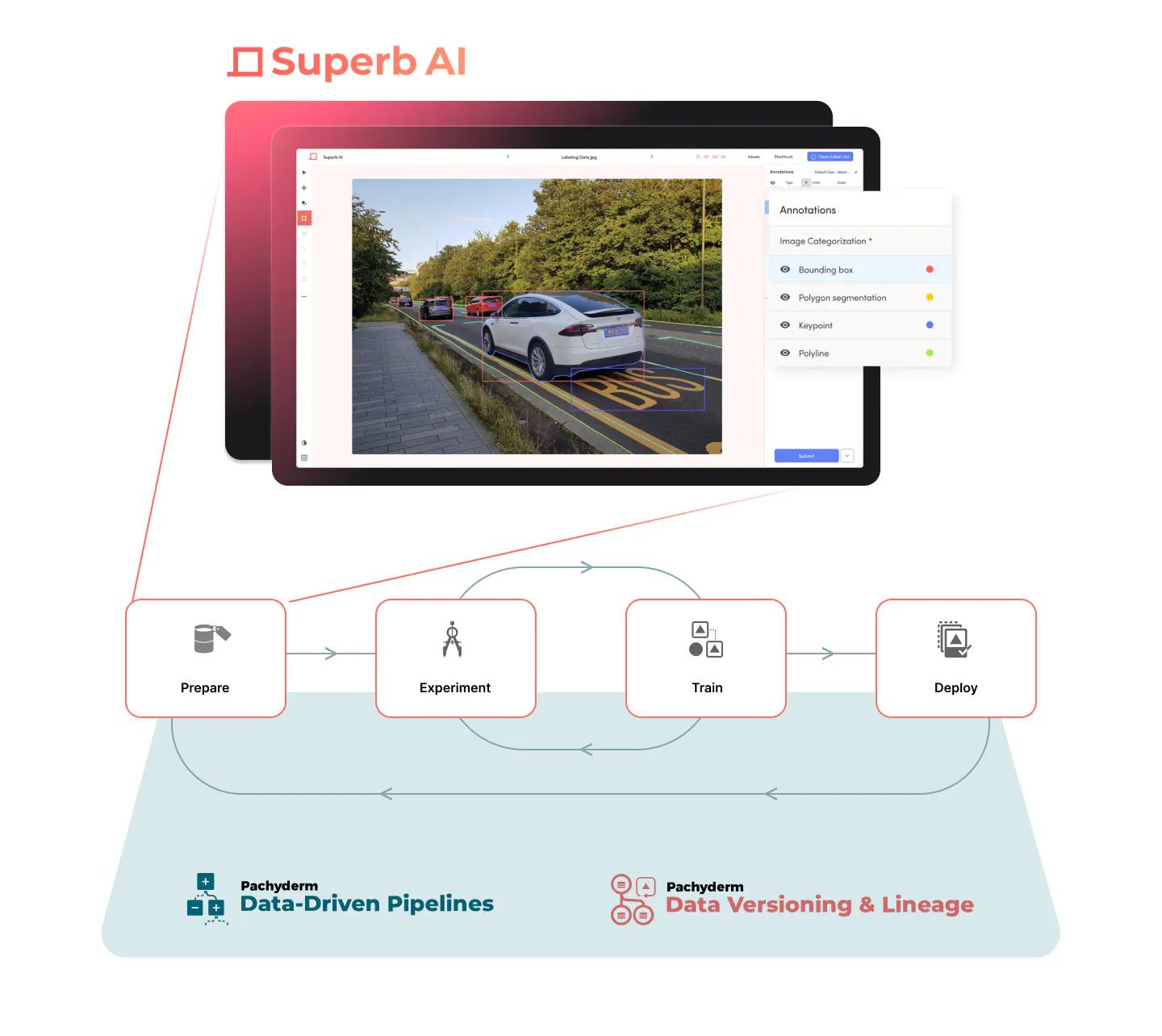
Pachyderm is the data foundation for machine learning. It is the GitHub for your data-driven applications.
Under the hood, Pachyderm forms this foundation by combining two key components:
- Data versioning and
- Data-driven pipelines.
Similar to git, with Pachyderm’s data versioning, you can organize and iterate on your data with repos and commits. But instead of being limited to text files and structured data, Pachyderm allows you to version any type of data - images, audio, video, text - anything. The versioning system is optimized to scale to large datasets of any type, making it a perfect pairing for Superb AI, giving you cohesive reproducibility.
Pachyderm’s pipelines allow you to connect your code to your data repositories. They can be used to automate many components of the machine learning life cycle (such as data preparation, testing, model training) by re-running pipelines when new data is committed. Together, Pachyderm pipelines and versioning give you end-to-end lineage for your machine learning workflows.
Key capabilities:
- Automate and unify your MLOps toolchain
- Integrate with best in class tools to enable data-centric development
- Iterate quickly while still meeting audit and data governance requirements
You can try this out for free with Pachyderm Hub.
Pachyderm as Superb AI’s Versioned Storage
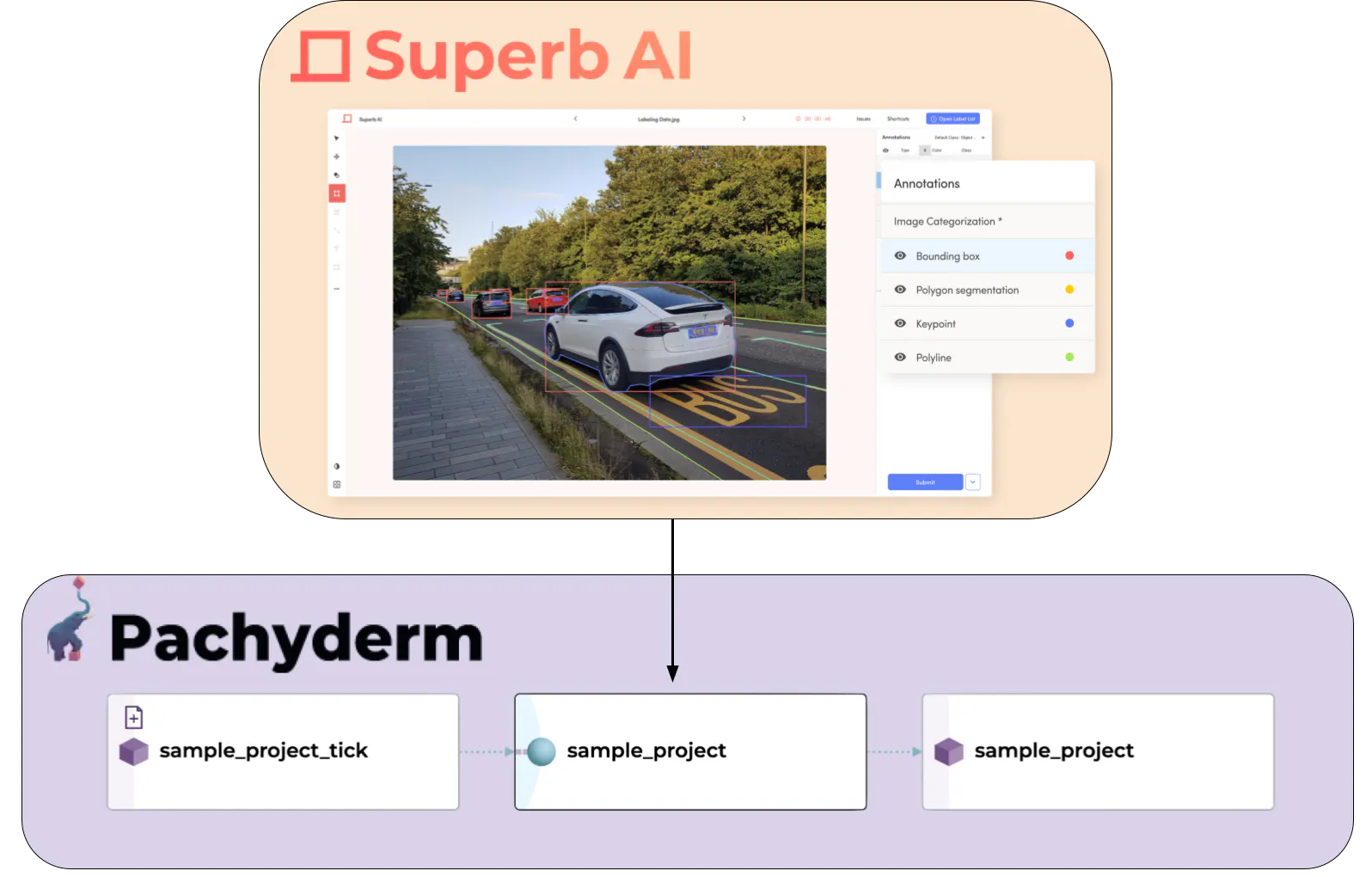
In this integration, we provide an automated pipeline to version data labeled from Superb AI. This means that we get all the benefits from Superb AI Suite to ingest our data, label it and manage our agile labeling workflows and all the benefits from Pachyderm to version and automate the rest of our ML lifecycle.
The pipeline itself automatically pulls data from Superb AI Suite into a Pachyderm Hub cluster, versioning it as a commit. This simply works by securely creating a Pachyderm secret for our Superb AI access API key. This key can then be used to create a pipeline that pulls our Superb AI data into a Pachyderm data repository.
We automate this by using a cron pipeline that automatically pulls new data according to a schedule (in our example, every 2 minutes). The output dataset will be committed to our “sample_project” data repository.
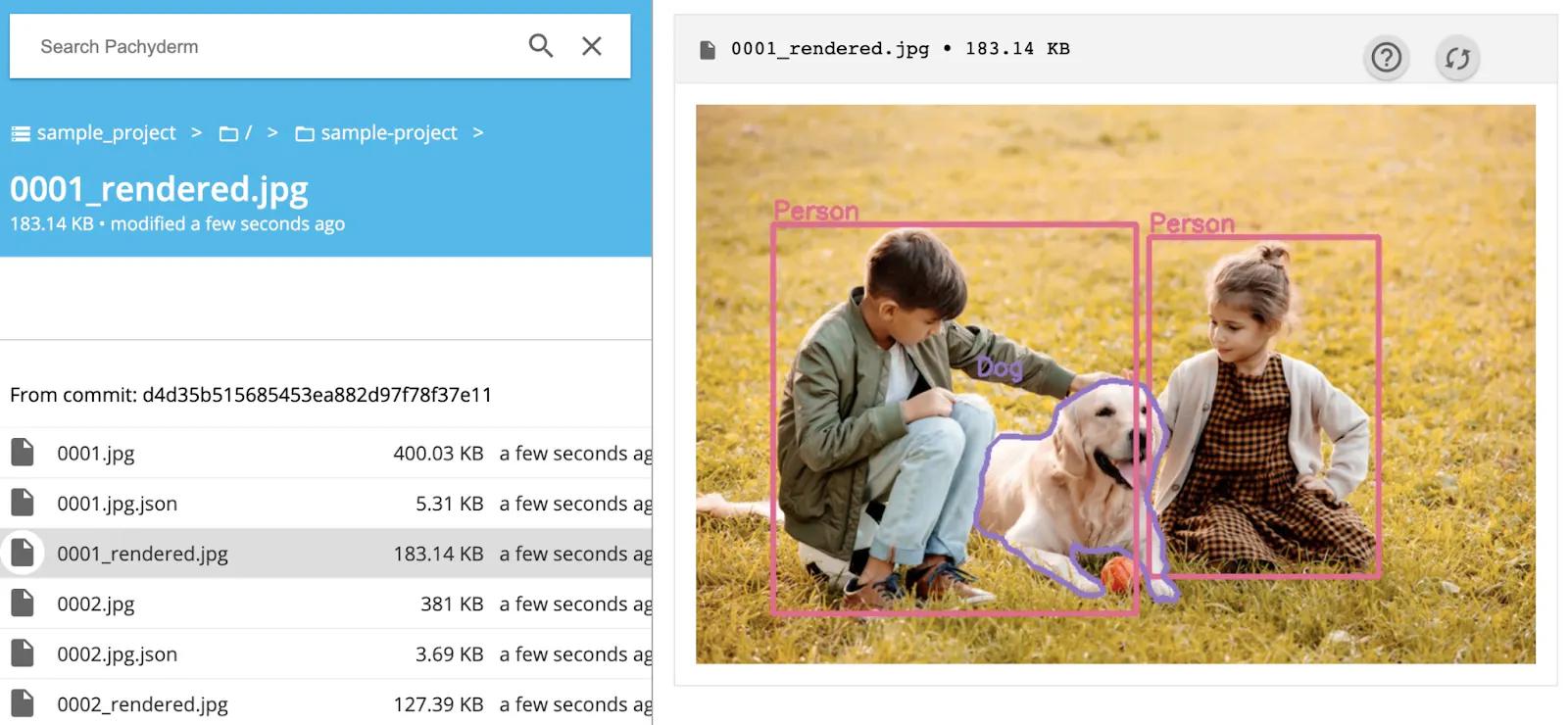
Once we have our data in Pachyderm, we can build the rest of our MLOps pipelines to test, pre-process, and train our models.
Conclusion
Data-centric development is key to producing machine learning models that operate in the real world. Together, Superb AI and Pachyderm unify the data preparation stage to be reliable and agile, ensuring we can continue to feed our models with good data and reduce data bugs.
Check out the full code for this integration on GitHub.
Both Superb AI and Pachyderm are part of the AI Infrastructure Alliance and dedicated to building the foundation of Artificial Intelligence applications of today and tomorrow.
Related Posts

Product
How to Build & Deploy an Industrial Defect Detection Model for a Lucid Vision Labs Camera

Sam Mardirosian
Solutions Engineer | 15 min read

Product
How to Build & Deploy a Safety & Security Monitoring AI Model for an RTSP CCTV Camera
Sam Mardirosian
Solutions Engineer | 15 min read

Product
How to Use Generative AI to Properly and Effectively Augment Datasets for Better Model Performance

Tyler McKean
Head of Customer Success | 10 min read

About Superb AI
Superb AI is an enterprise-level training data platform that is reinventing the way ML teams manage and deliver training data within organizations. Launched in 2018, the Superb AI Suite provides a unique blend of automation, collaboration and plug-and-play modularity, helping teams drastically reduce the time it takes to prepare high quality training datasets. If you want to experience the transformation, sign up for free today.