効率的かつ効果的な機械学習モデルの開発には、数多くの課題があります。これらのハードルを乗り越えるために最も重要なのは、データに関連する問題を早期に発見し修正することであり、そのためにはモデル診断が非常に重要であります。そのためには、モデルの性能を阻害する前にデータの問題を特定し、修正するツールであるモデル診断が非常に重要です。
この記事では、Superb AIのCurateツールが、モデル診断とデータ問題の早期発見にどのような変革をもたらし、正確で偏りのないコンピュータビジョンモデルに不可欠な、バランスの取れた高品質なデータセットの作成にどのように大きく貢献しているかについて紹介します。
本記事でカバーする内容
モデルデータの問題の早期発見
評価とトレーニングセットの妥当性
データ問題の早期発見テクニック
Superb AIのモデル診断ツールの紹介
モデルトレーニングと最適化の自動化
モデルの診断結果を読み解く
モデル診断(モデル評価とも呼ばれる)は、機械学習モデルのトレーニングと開発の様々な段階において、潜在的なデータの問題を検出し、トラブルシューティングを行い、改善を提案するために開発された一連のチェックと調整機能で構成されます。
これらの診断テストは、学習アルゴリズムの有効性と機械学習モデルのパフォーマンスを文脈から洞察し、何がうまくいっていて、何がうまくいっていないのか、そしてモデルのパフォーマンスを強化する方法を明らかにする。診断チェックには、データセットの信頼性チェック、モデルチェック、リーク検出など、さまざまな形式があり、それぞれが診断プロセスにおいて独自の目的を果たします。
データセットの信頼性チェック: これらのチェックは、使用データの完全性を保証する。欠損値、外れ値、信頼できない結果をもたらす可能性のある不整合などの潜在的な問題を発見するのに役立ちます。
モデルチェック: これらのチェックはモデル自体に焦点を当てます。オーバーフィッティングやアンダーフィッティングのテスト、モデルの仮定とデータの整合性の検証などが含まれます。
データのもれチェック: データのもれは、過度に楽観的な性能推定につながる可能性があります。もれの検出チェックは、もれを特定するのに役立ち、モデルの性能の正確な評価を保証します。
マシンラーニング診断の実行
最新のデータサイエンスツールでは、トレーニングやデプロイされたモデルに対して様々な診断テストを行うことができます。これらのテストは、モデルの不具合に関する貴重な洞察を提供し、問題を回避するための適切な修正ソリューションを提案します。例えば、データバランシングは、ニューラルネットワークをトレーニングする際にバランスの取れたデータセットを保証し、学習バイアスを低減します。これは、欠陥のあるデータが必要とされるデータ分類タスクでは特に重要です。
評価セットおよびトレーニングセットの検証
信頼性の高い機械学習モデルの評価のためには、使用するデータセットが訓練データと将来のスコアリングデータの両方を正確に表している必要があります。テストセットが小さすぎると、モデルの性能推定が信頼できなくなる可能性があるからです。
また、テストデータにおけるターゲット変数の分布が、トレーニングデータの分布と一致していることも必要です。そうでない場合、メトリクスは誤解を招く可能性があります。このようなシナリオでは、より大きなテストセット、より高いテスト比率、またはクロスバリデーションの使用が推奨されます。
よくあるデータの問題を診断する
コンピュータビジョンモデルを構築する際、クラスの不均衡、シナリオの不均衡、データのばらつき、ノイズなどの一般的なデータ課題に頻繁に遭遇します。このような問題は、モデルの性能、精度、全体的な効率を著しく低下させます。
クラス不均衡とは、データの特定のクラスが過剰または過小に表現され、歪んだ予測につながることで す。
シナリオのアンバランスは、現実世界のシナリオの一部がデータで十分に表現されていない場合に発生し、そのようなシナリオではモデルのパフォーマンスが低下する原因となります。
データのばらつきとは、データセットの不均一性のことで、これによってモデルが多様なシナリオにわたって一般化することが困難になる可能性があります。
ノイズには、誤ったラベル付けをされたデータと、モデルの学習と予測を歪める異常値の両方が含まれます。
早期発見の重要性
モデル診断とは、モデルの弱点を特定し理解しようとするプロセスであり、モデル展開前にこれらの問題を修正することを可能にします。データ上の課題を検出し、解決することで、モデルの性能と精度を向上させる上で重要な役割を果たします。
したがって、信頼性の高い機械学習モデルを作成するためには、データの問題を早期に発見し、解決することが不可欠であります。学習後にモデルを検証することで、モデルの診断が、モデルのパフォーマンスが低い特定のデータ・スライスをピンポイントで特定することができ、必要な改善を事前に行うことが可能になります。
データ問題の早期発見のためのテクニック
モデル診断は、それぞれのデータ課題に対して特定のテクニックを適用します:
クラスの不均衡に対処するために、少数クラスをオーバーサンプリングしたり、多数クラスをアンダーサンプリングするような技術を採用することが考えられます。
シナリオの不均衡は、代表的でないシナリオについてより代表的なデータを収集することによって是正することができます。
データのばらつきは、モデルの予測精度を向上させるために、トレーニング中に多様なデータを取り入れることで管理することができます。
異常検出のような技術は、ノイズ(外れ値やラベル付けミスされたデータ)を識別し、管理するために使用することができます。
クラスの不均衡への対応
クラスの不均衡は、あるクラスが他のクラスよりも著しく多くのサンプルを持つという一般的な問題で す。これに対処するために、少数クラスをオーバーサンプリングしたり、多数クラスをアンダーサンプリングしたりする技術が採用されます。
少数派クラスのオーバーサンプリング: この方法では、データセットに少数クラスのインスタンスを追加します。その目的は、クラス間のインスタンス数のバランスをとり、モデルにより多くのデータを与えて、代表的でないクラスから学習させることです。
多数派クラスのアンダーサンプリング: この方法は、データセット中の多数クラスのインスタンスを減らします。その目的は、多数派クラスがより多く存在するために、モデルが多数派クラスに偏るのを防ぐことです。
1. シナリオの不均衡
シナリオの不均衡は、あるシナリオがデータセットの中で十分に表現されていない場合に発生します。このため、代表性の低いシナリオに直面した場合、モデルの性能が低下する可能性があります。この問題に対処するには、代表的なシナリオのデータをより多く収集すれば良いので す。こうすることで、モデルがより多様な状況にさらされるようになり、その結果、その状況に対処する能力が向上します。
データのばらつきが大きいと、モデルの効果的な汎用化能力に影響を与える可能性があります。これに対処するには、トレーニング中に多様なデータを取り込む必要がある。これにより、モデルは幅広いデータパターンとシナリオにさらされ、最終的に、新しいデータや見たことのないデータに直面したときに汎用化し、正確な予測を行う能力が強化されます。
ノイズの特定と対処
データに含まれるノイズは、外れ値やラベル付けミスなど様々な形で現れ、モデルの性能に大きな影響を与える可能性があります。
異常検知: この手法は、データセット中の外れ値を識別するために使用されます。これは、他のデータから著しく逸脱しているデータ・ポイントです。一旦識別されると、これらの異常値は調査され、適切に処理されるようになります。
誤ったラベルの付いたデータの取り扱い: 誤ラベル付けされたデータは、モデルが誤ったパターンを学習する可能性があります。データクレンジングや手動レビューのような技術は、このようなラベル付けミスのインスタンスを特定し、修正するために使用できます。
1. データセットの異常を検出する
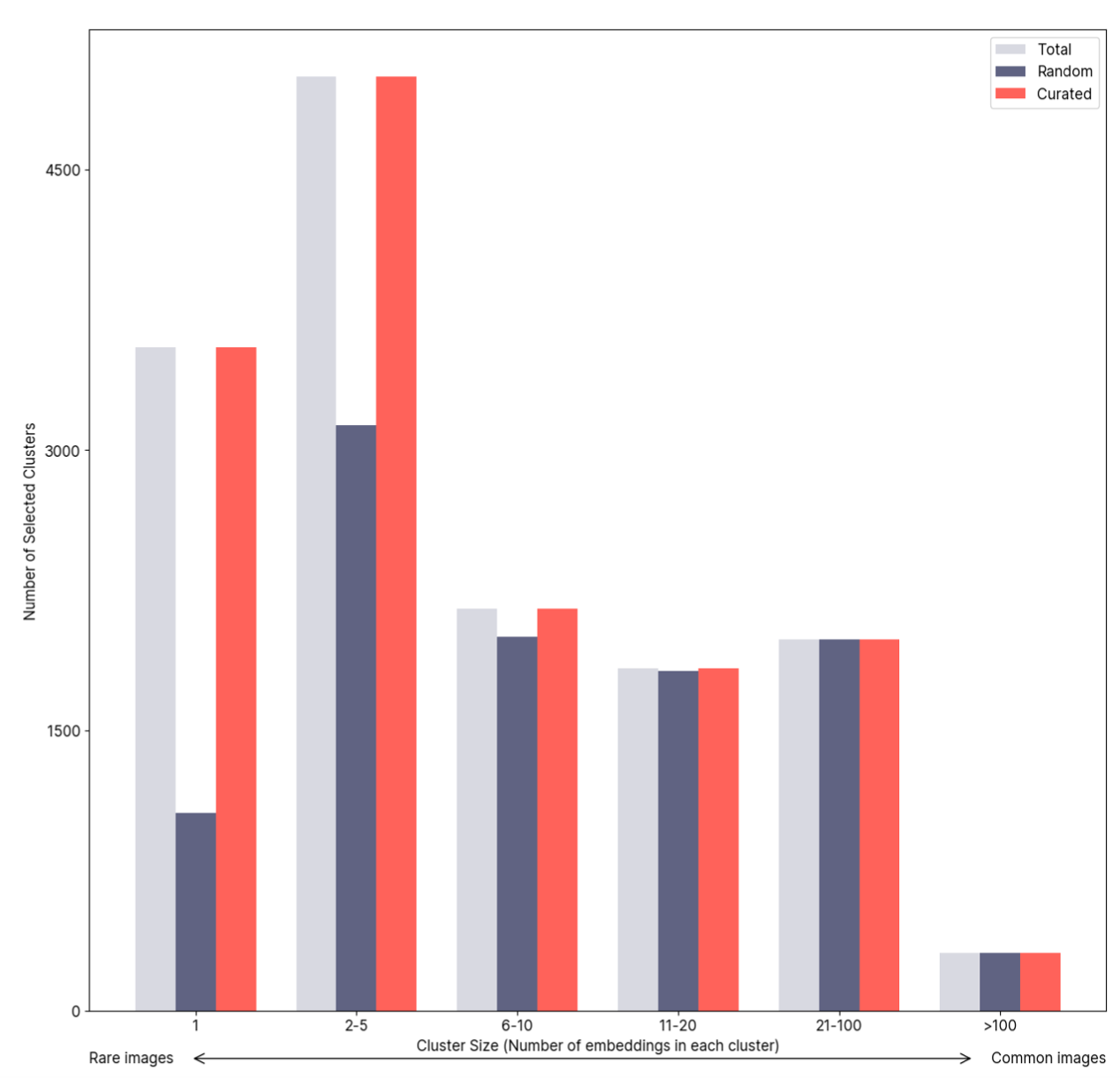
Superb CurateのAuto-Curateツールは異常検出に活用できます。”疎密”基準を強調するようにキュレーション・アルゴリズムを設定すると、ツールは埋め込み空間内で他のデータポイントから離れているケースを選択するように指示されます。基本的に、これは、アルゴリズムが、稀な位置にある、またはエッジケースである可能性が高いデータポイントを選択することに集中することを意味します。

機械学習モデルの学習プロセスにおいて、ラベル付けミスデータは深刻な問題となります。誤ったラベル付けがされたデータで学習されたモデルは、誤ったパターンを学習する可能性があり、モデルの性能に大きな影響を及ぼす可能性があります。このようなラベル付けミスのインスタンスを正しく識別し、処理することは、どのようなモデルでもバランスの取れた性能を確保する上で極めて重要なステップです。
Auto-Curateもまた、この問題に対処する上で重要な役割を果たすことができます。Auto-Curateのラベルノイズ基準を利用することで、ミスラベルの可能性のあるデータを特定することができます。その原理は、あるデータ点がラベルの異なる他のデータ点の近くにある場合、そのデータ点はラベルが間違っている可能性が高いというものです。このような事例を特定することで、ユーザは誤ったラベル付けのエラーを修正し、修正されたデータを使用してモデルをさらに訓練することができます。

Superb AIのCurateツールとModelツールは、AI導入における様々な課題に取り組む統合ソリューションを提供し、AIプロジェクト導入におけるワンツーパンチを実現します。これらのツールは、モデル診断、トレーニング、デプロイメントのための堅牢なツールとして機能し、単一のプラットフォーム内でMLOpsサイクルをシームレスに実行します。
1. データ障害のレイヤービュー
エンベッディングによる画像データの可視化は、モデル診断プロセスにおいて大きなアドバンテージとなります。Superb AIのCurateは、高次元エンベッディングアルゴリズムを採用したユニークなアプローチで画像データを表現します。これらのアルゴリズムは、画像データの包括的で視覚化しやすい表現を提供する次元ベクトルを生成します。
これらのベクトルを折りたたむと、ユーザーはデータの傾向とパターンを観察し始めることができます。この機能は、特にデータのばらつきが大きい場合に、データの効率的かつ効果的な検査と理解を容易にするため、データの問題を早期に診断する上で極めて重要です。
2. アクティブラーニングのワークフロー
Superb AIのCurateは、最も効率的なデータラベリングのためにアクティブラーニングワークフローを利用しています。この反復プロセスでは、データの小さなサブセットにラベルを付け、ラベリングモデルをトレーニングし、モデルを使用して次のサブセットの初期ラベルを生成し、自動化されたラベルを修正し、新しいモデルをトレーニングし、このプロセスを繰り返します。
このワークフローにより、モデルの継続的な学習とデータへの適応が保証され、ラベリングの精度が向上します。能動的な学習を行うことで、Curateはモデル学習の初期段階でのデータ問題の検出を強化します。
3. エンベッディングによる早期検出
エンベッディングはデータの問題を早期に発見する上で極めて重要です。特に、大量の生データやラベル付けされていないデータを扱う場合に有益です。Superb AIのCurateは、このようなデータのエンベディングを生成し、ユーザーはそれを視覚化し、検証し、潜在的な問題を解釈することが出来ます。
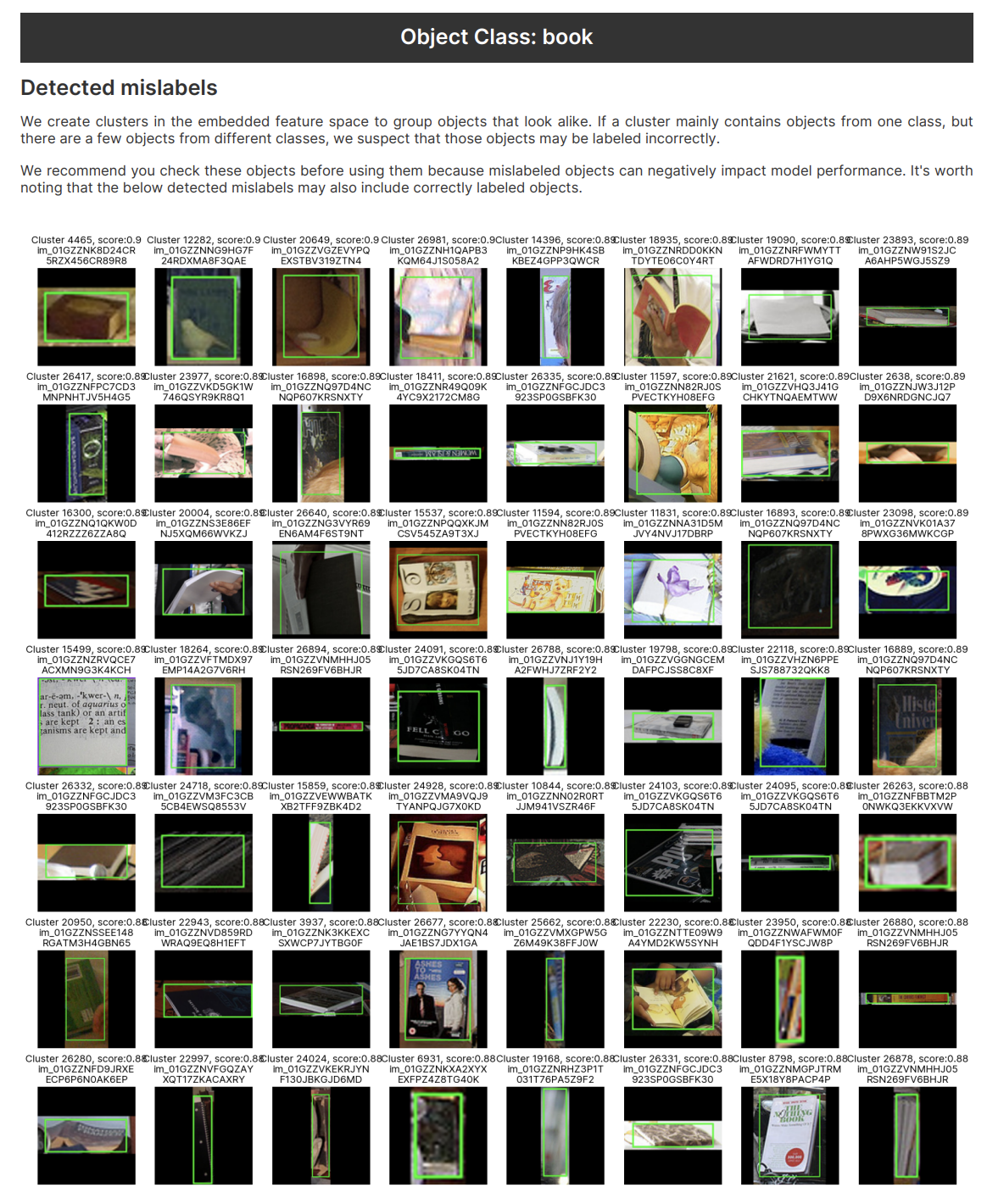
このツールはさらに一歩進んで、このコンセプトをラベル付きデータにも応用しています。ラベル付けされたデータのエンベッドをオブジェクト・レベルで生成し、これらのオブジェクトをクラスタリングすることで、Curateは潜在的なラベル付けミス・データに関する貴重な洞察を明らかにし、データ品質保証を支援します。

クラスタライゼーションは、Superb AIのツールボックスにおけるもう一つの価値あるテクニックです。個々のオブジェクトが異なるオブジェクトクラスとして同じクラスタを共有するインスタンスを調べることで、Curateは誤ったアノテーションの可能性が高いラベルを特定します。
データスライシングは、Superb AIのAuto-Curateプロセスによって提供される強力な機能です。このプロセスは、ユーザーレビュー用にデータのスライスを生成し、さらにスライスしたり、Superb Suiteのラベルセグメントに送ってラベル付けを行うことができます。
これはデータの解釈性を高めるだけでなく、データ品質の効率的な補正を可能にしています。また、Auto-Curateプロセスは、各実行に付随してレポートを生成し、エンベッディングベースのデータキュレーションプロセスの内部構造の透明性を提供します。
Superb Curateの "クエリー "機能は、データのスライスとレビューの過程で強力なアシスタントの役割を果たします。このツールは、各データセットに関連付けられたメタデータと注釈情報を活用し、ユーザーが的を絞った条件文やクエリーを作成することを可能にします。これにより、設定された条件を満たす正確なデータサンプルの抽出が容易になります。
6. Superb AIのCurateにおけるアクティブラーニング
Curateはアクティブラーニングワークフローを使用しており、データのキュレーション、問題のある領域の特定、修正の可能性の提案、ユーザーからの入力に基づくデータセットの改良といった作業を継続的に繰り返していきます。
モデルの評価と診断
モデル診断は、モデルの健康診断のようなもので、パフォーマンスに影響を与える重大な障害に雪だるま式に拡大する前に、早い段階で潜在的な問題を特定します。Superb AIのCurateは、このような診断タスクを支援するために設計されており、データの問題を迅速に特定して修正し、正確で効率的かつ堅牢なモデルの作成をサポートします。クラスの不均衡からシナリオの不均衡など様々な問題を検出することができ、開発者はこれらの問題に積極的に対処することができます。