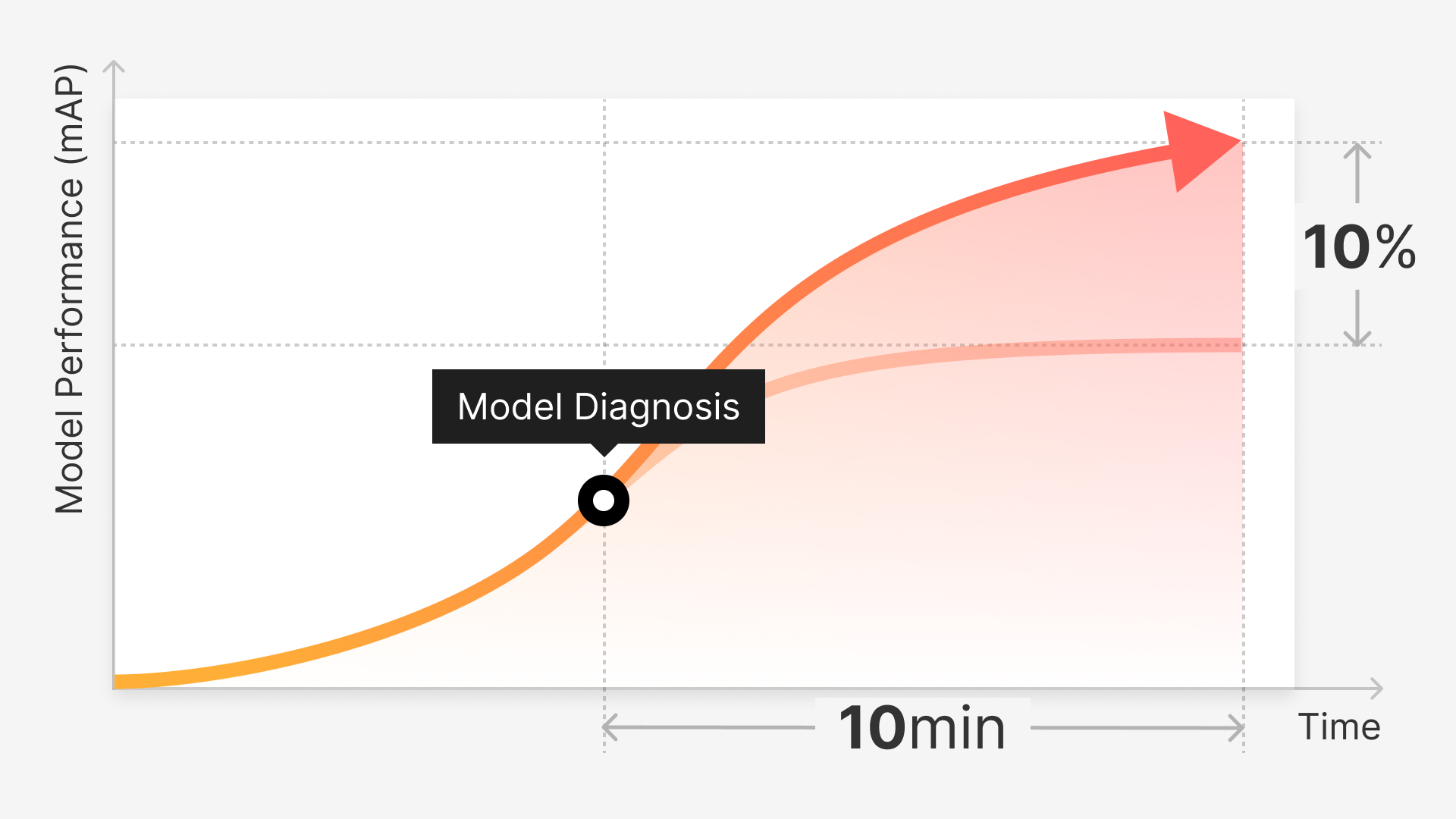
Introduction
Nowadays, we're so accustomed to using data to drive current technologies that we take it for granted and assume that it functions on its own. However, this is not the case as it's controlled by human beings, meaning that errors and prejudices can find their way into it.
In Machine Learning, the behavior of the program is no longer predetermined by code, but rather, the program is taught by the data. This makes the quality of the data just as important as the code. In practical ML systems, the data usually comes from multiple sources and is often not precise, inconsistent, or has some other quality issues. For this reason, ensuring data quality is of great importance.
Still, data quality is somewhat of an ambiguous concept that can refer to a variety of major or minor issues that can occur in different development stages. This gets even more confusing when it comes to unstructured visual data. We had a great discussion about data quality in the context of computer vision in our fireside chat with AI experts, thought leaders, and founders of AI infrastructure startups - Alessya and Hyun. If you're interested, you can watch the recording on our YouTube channel or continue reading.

Meet the Guests
Alessya Visnjic is the CEO of WhyLabs, the AI Observability company building tools that power robust and responsible AI deployment. Prior to WhyLabs, Alessya was a CTO-in-residence at the Allen Institute for AI, where she evaluated the commercial potential of the latest AI research.
Earlier in her career, Alessya spent 9 years at Amazon leading ML initiatives, including forecasting and data science platforms. Alessya is also the founder of Rsqrd AI, a global community of 1,000+ AI practitioners who are committed to making enterprise AI technology responsible.
Hyun Kim is the co-founder and CEO of Superb AI, an ML DataOps platform that helps computer vision teams automate and manage the full data pipeline: from ingestion and labeling to data quality assessment and delivery. He initially studied Biomedical Engineering and Electrical Engineering at Duke but shifted from genetic engineering to robotics and deep learning.
He then pursued a Ph.D. in computer science at Duke with a focus on Robotics and Deep Learning but ended up taking leave to further immerse himself in the world of AI R&D at a corporate research lab.
During this time, he started to experience the bottlenecks and obstacles that many companies still face to this day: data labeling and management were very manual, and the available solutions were nowhere near sufficient.
Why did you decide to start a company?
Alessya: I spent many years working at Amazon. I was very fortunate to experience the very beginnings of AI adoption in a company like Amazon. I had the fortune of building an internal machine learning platform in the company and watching the adoption of this platform and how every team that gets AI to production in the company was able to benefit from more streamlined operations, continuous testing, continuous monitoring and reproducibility.
It was very inspiring, actually, watching the team go from scrambled operations that rely on a lot of tribal knowledge and Jupyter Notebooks, frankly, to something that is more systematic was magical. So once I experienced that I got very excited about watching how this wave of tools is going to impact every company and every organization out there that is relying on AI. I decided to leave Amazon and find a way to participate in building this toolchain.
This was around the time the industry coined the MLOps term, and now MLOps is a fairly colloquial word in the community. So I left Amazon with the idea of participating in this wave and essentially building the tools and making them available to every practitioner out there. So that's what inspired WhyLabs.
Hyun: Prior to starting the company, you know, I used to work as a machine learning/computer vision engineer at a corporate research company, and I worked on various projects from self-driving to gaming in Starcraft AI and unsupervised learning. I strongly believe that AI will be the next breakthrough for mankind, like electricity or personal computers or the internet, but the pace at which AI tech was evolving, seemed to be too slow.
In academia, tons and tons of new research papers were being published every day, but the rate at which companies and industries adopted AI seemed stagnant. This was especially the case for large enterprises and even more so for traditional industries and enterprises. The biggest bottleneck that I identified was preparing training data. Superb AI was founded to solve the training data inefficiency problem.
Understanding Data Quality in Various Stages of ML Lifecycle
Data quality in the model development stage
Hyun: In the initial model development stage, I would classify data quality into two buckets:
The first bucket is the quality of annotations. And there are a couple of things to consider. One would be the correctness of the annotations, things like the classifications correct, whether there are any false positive bounding boxes or false negative bounding boxes, are bounding boxes tight enough around the object of interest.
Another aspect of that is the consistency of annotations. Let's say you're a self-driving AI startup and need to label a million images of cars. Do you include the side mirrors in the bounding boxes? What about occlusion? Let's say your car's occluded by a pedestrian that's standing in front of it, do you draw a large box for the entire car or do you draw two separate boxes for the left side and right side of the occlusion?
These kinds of details should be consistent throughout the entire dataset because these can throw off your models during training. Another thing that's obvious, but often overlooked, is the distribution of your classes. Obviously, if you have a skewed dataset you can expect a biased model.
The second bucket is the quality of raw data. You should consider a few things here as well. One would be the quality of the images - simple things like the blurs or lighting conditions - need to be checked.
The other big piece to raw data quality is the coverage or the diversity of your raw data set. Going back to the self-driving use case car dataset, you need to check whether you have enough diversity in your background (weather conditions, lighting, time of the day, camera angles, etc.) and diversity in the object of interest itself (do you have enough variety in the car class like car model, color, the orientation of the colors, or the doors or trunks opened closed, the headlights on or off).
If something's not in your data set, you shouldn't expect your model to learn it. Of course, the model learns to generalize, that's the whole point of training a model. But there are limits to how far a model can generalize.
How can one check the quality and distribution of annotations and raw data?
Hyun: Checking the distribution of annotations is easier because you can just use statistics to do that. For example within the same class, you want an even distribution of aspect ratios. Let’s say a “Person” class usually is tall and thin bounding boxes. But what if your model in production encounters a person lying down flat? That might throw your model off. For things like these, you can catch issues using pretty straightforward statistics.
Examining the quality of raw data is a more challenging task when it comes to computer vision data. But there are ways to assess raw datasets with the help of deep learning features like embeddings. To do so, you will have to compute embeddings from your images, and then conduct multiple operations on these embeddings. This could involve clustering, analyzing the distribution of embeddings, or visualizing embeddings in a two-dimensional space using a dimensionality reduction algorithm. Although these techniques are not yet widely used in the industry, they are expected to be very useful in the near future. At Superb AI, we provide these tools and techniques but are currently in the closed beta phase. If you would like to try them out, please request a demo here.
Data quality in the post-production stage
Alessya: Just like with the model development phase, once you have a model in production there are a few data quality aspects that you need to monitor:
One of the most important factors is the quality of the features. By the time the model is put into action, the raw data has already been converted into features, and it needs to be ensured that the feature data is of consistent quality. In the case of computer vision applications, if the sensors are obstructed or if the aerial images have cloud coverage of 50 to 70 percent, then it's difficult to use these images, and the model will not be able to accurately identify the objects that need to be extracted. Thus, the quality of the features that are fed into the model should be constantly monitored.
A concept known as training-serving skew can arise when a model is used in production. This means that when the model is deployed, it should be exposed to input data that is similar to what it was trained on. For example, if the model was trained to detect how many people are standing up, but in production, it receives images of people laying down, the model may incorrectly count the number of people. This is an example of drift and can even occur when the data is simply rotated when it is fed into the model for prediction. Therefore, it is essential to be aware of any drift that may occur to ensure the model performs optimally during production.
How should you monitor data quality issues?
Alessya: The way you catch these issues is by monitoring both - the point where the data goes into the model and the point of the model outputs. For example, whether the bounding boxes that your model is producing are consistent with the shape and distribution, number and size of bounding boxes that you have seen during training.
Suppose you teach a model to detect veins and arteries on ultrasound, and the training data usually includes two or three bounding boxes. When comparing to the evaluation dataset, the model is expected to recognize two or three bounding boxes - a normal pattern. However, if the model in actual use starts to produce 20 distinct arteries in every image, then it's a clear indication that there is something wrong with either the data quality or the type of data the model is using.
To summarize, when it comes to production, there are a few different places where you would monitor for problems with the data quality:
Upstream to the model - monitor data at the model input point or earlier in the pipeline to make sure that data providers are providing data that is coming from the types of devices that you expect. For example, if a self-driving car’s camera resolution changes the model might not be ready for these types of inputs.
On the model output side - monitor data to make sure that the outputs, the bounding boxes and the distribution of classes are consistent with what you have seen during the training and evaluation.
Types of data drift and how to deal with them
Conceptually, drift is when your production environment is different from what the model has observed during training, and it could be different for several reasons. It's a pretty involved exercise to understand what kind of drift you observing, where it's coming from and what you should do about it.
Let's look at common types of drift:
Data drift in the real world: before COVID, people who showed up on cameras were typically not wearing masks, and as soon as we went into the pandemic, cameras that were installed in public places started to see people wearing masks. So any models that were trained to do facial recognition or even just people recognition were likely thrown off. That’s data drift demonstrated in the real world.
Concept drift: Let's say you trained an autonomous driving model to recognize cars. Then you deployed it somewhere in Italy and there are a lot of Vespas there. That's a brand new class of objects that the model has not observed before, even though it is still a car. That’s a concept drift.
When it comes to identifying the drift what you try to do is monitor the system for indicators of changed inputs into your model (data in production is different from the data your model has seen during training/evaluation).
When you're working with images, as Hyun was saying earlier, you can do simple statistical things - you can count pixel distributions, and look at lighting conditions, brightness, saturation, and color channels. These would get you pretty far. When it comes to analyzing image quality, embeddings are a good way to provide some insight.
But here's only so far that we can go with this quantitative kind of tests that we can run. Especially in computer vision systems, there's always a fallback on humans. After looking at all the statistical tests and all the embedding tests, I think falling back on the human will be the next logical step. Does this data look different? What is different about it?
Alternative phrasing: To evaluate any drift in the output, an example would be to track how objects the model identifies in one minute while driving. Also, note the sizes of these objects and examine if there has been a change in this statistic. A good indication of drift may be when the car is not moving at a fast speed because it's waiting for something, however, the model is not detecting any objects. Additionally, the bounding boxes that are marked will have a specific size and shape for different objects; for example, the shape of a car's bounding boxes will vary from that of a VESPA. So, if the shape of the bounding boxes changes considerably, it could be a sign to look further into the issue.
What are some critical aspects of data prep that ML teams are currently overlooking that eventually, should become common practice, otherwise, ML will fail in production?
Hyun: Something that ML teams overlook, especially teams that are early in their ML development cycle, is the diversity of raw data. New teams tend to focus on label accuracy because they already have the raw data collected, they want to get the labels and just start training.
As teams gain more experience, they might eventually reach a point where their labels are accurate, but their model's accuracy isn't satisfactory. At that point, they should focus on gathering more data, but not just any kind of data - they should strive to have a more diverse range of raw data. To speed up their machine learning development process, teams should make sure they have a sufficient amount of varied raw data before they face this roadblock in the future.
Another thing I wanted to mention is something that ML teams are overdoing in my opinion. I think too many teams are trying to audit the entire data set manually when they measure label quality. If you had an infinite amount of time and money to throw at that problem, sure, you can go ahead and audit your entire dataset by hand but that's not the case for most teams.
For resource and time-constrained teams, the goal should instead be to fix as many errors or mislabeled data as fast as possible. Then move on to whether it's training the model or collecting more data, the point is that you don't want to stop there and spend too much time. To do this there are intelligent ways to audit your annotations, rather than random sampling. Let's say your data set has 100,000 images and maybe 1000 of them have errors or are mislabeled - 1 percent error rate. If you can find and fix half of these errors, which is 500 images, by intelligently sampling and auditing small subsets of the dataset that's a huge time saver.
I think your time will be better spent collecting and labeling a fresh new set of data than trying to find a small number of errors. You know, it's like finding a needle in a haystack, something that I think teams are overdoing.
Closing the Machine Learning Development Loop
“One day all software will learn…” How can we practically achieve this?
Alessya: There should be a separate conference on that. Development is not a linear process. It doesn't have a beginning and an end. It's very cyclical, and there are many cycles throughout the lifecycle. I think we're still discovering what are meaningful cycles and what cycles could be automated.
So, one example is once you have a model in production, and you're monitoring and recognizing that your model is not performing well, you can close the loop by communicating at the data preparation step and say: “These are the gaps that I'm seeing, these are new images or the new categories of data that needs to be annotated, a model should be retrained and pushed through the few stages of evaluation deployment” and so on, probably pushed into shadow mode and then analyze whether that made a difference.
And the more automation is in the steps, the faster the cycle goes, and the less error-prone it is because typically human handoffs are what introduces a lot of errors. So the one I just described as the simplest one. But they exist in many steps over the lifecycle. Even in the data preparation step. You need to go through multiple steps of evaluating whether the data you have prepared is sufficient and covers all of the important use cases.
I think the big push in the future for us is discovering what are the most important cycles or feedback loops that need to exist in the machine learning lifecycle, and how we systematize and automate them as much as possible, minimizing that human handover. And the hardest part of this is deciding what the communication protocols should be and how the production environment communicates with data annotation steps or feature processing steps in an automated fashion to essentially signal that something is not going right and something has to change.
How does Superb AI help to close the ML development loop?
Hyun: In my experience, you always have to go back to the data side of ML. That's the whole point of data-centric AI and that’s what our team at Superb AI is working to provide for ML teams. I can think of a few ways to close the loop:
The simplest way, is basically to have the clients upload post-production model inferences or during experiments also, upload model inferences to our platform, and just have the labelers audit and review the inference results in real-time. Then use the audited version of the dataset to retrain the model and repeat this process over and over. And as time goes by, you'll have less number of errors in your model inference. Thus, you'll need less amount of manual human input, to iterate upon that cycle.
The second way, we're beta testing right now, is the data curation feature. It's an automation feature that, among other things, helps find rare or edge cases in the dataset. These rare cases are often the ones that the model in production will fail on. So with this feature, we help users identify the patterns or clusters of data that we expect their models to perform poorly on.
We can even do that before deploying the model into production by analyzing the training datasets the models trained upon. So with that information, users can then collect more of these rare cases to enhance their dataset and thus improve the model accuracy.
And then the third way is something that I want to do in the future in our product is to integrate with model deployment and monitoring platforms, like WhyLabs. Using tools like WhyLabs, our clients will have a better way to monitor their model and production and then be alerted to get back to the drawing board and do data collection, visual labeling and analytics. That's what we want to do in the future to help our users close the ML loop.
Questions From the Audience
Q: You mentioned how the distribution of data could be different for your training data versus production data. Is that always an indicator of harmful drift? Because let's say your model is deployed in a manufacturing scenario where a class of interest will be inherently skewed, right? But then for training, you want your training set to be more or less evenly distributed. So for those kinds of things, you expect the distribution to be different.
Alessya: That's a very good thing to point out if you're building an anomaly detection system in the manufacturing pipeline. In this case, you want to show your model as many examples of anomalies as possible, but in reality, you want it to see as few examples as possible. I think in this case, using direct training-serving skew parallel may not be the best. The alternatives to that:
You can use your evaluation distributions as a baseline if your evaluation dataset is reflective of the real world or expected distributions.
You could also build a baseline as a moving window. You determine at how many anomalies have you seen in the past two weeks and that becomes your baseline. So you’re saying that my past 2 weeks have been fairly good quality and a reliable indicator of things going well, I'm always going to look back two weeks to see whether I'm different today from what I've seen in the past two weeks. That's a very good way to address the training-serving skew monitoring and baseline because it gives you a more well-rounded understanding and is especially important in situations like anomaly detection.
Q: For an image-based object detection or classification model, how do you handle class overlap, where multiple classes may have some commonalities in feature space?
Hyun: I think you're talking about classes like pen versus pencil, something that visually looks similar - multiple classes have commonalities in the feature space or embedding space. I think you want to optimize the embeddings so that the embedding representations can disentangle these multiple classes. This can be done either algorithmically by using different or better-performing embedding calculation deep learning models or could be solved using data, more data, throwing more data points that are near the decision boundary of these two classes. So that your embedding model can pick up the nuances of the different classes. And then this also applies when you want to change your class set. So let's say initially, you start with a large set like for example autonomous vehicles.
Let's say you start with a car class but later down the line you might want to split that into a taxi versus sedans. And then you'll find out that within your dataset, the embedding model that you trained initially will cluster or will embed these car classes into the same more or less similar embeddings. But once you change these classes into a more granular class set, your embedding model will then have to learn to differentiate between these two classes.
Join the Community
Keeping up with advancements in the Computer Vision field can be challenging as things happen at the lightning speed. If you are working with or interested in computer vision, consider joining The Ground Truth Newsletter. It’s a bimonthly community newsletter where we share all the latest computer vision news, research, learning resources, tools, and live community chats like this one.